How Computed Columns Can Cause Blocking
5 Comments
The short story: when you add a computed column that references another table, like with a scalar user-defined function, you can end up causing concurrency problems even when people didn’t really want to go see that other table, and that table is locked by someone else.
Here’s my query:
|
1 2 3 |
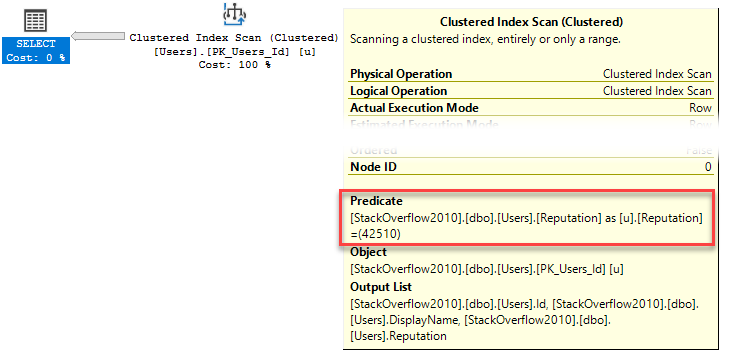
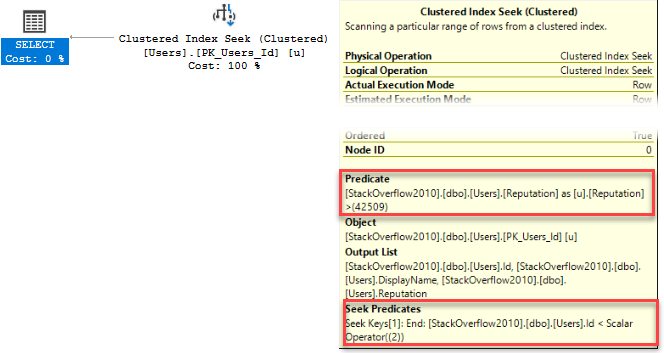
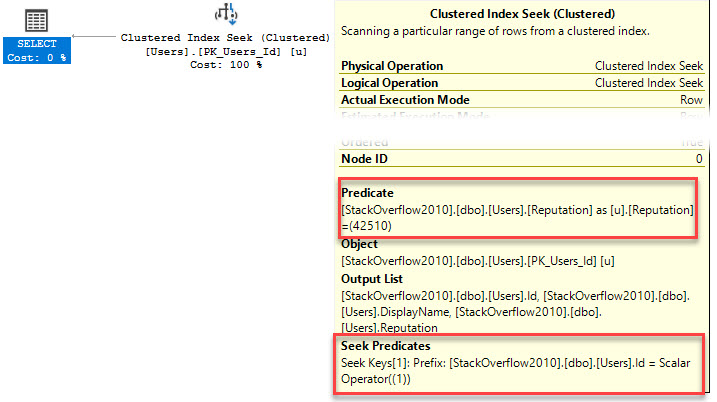
SELECT Id, u.DisplayName, u.BadgeCount FROM dbo.Users AS u WHERE u.BadgeCount >= 500; |
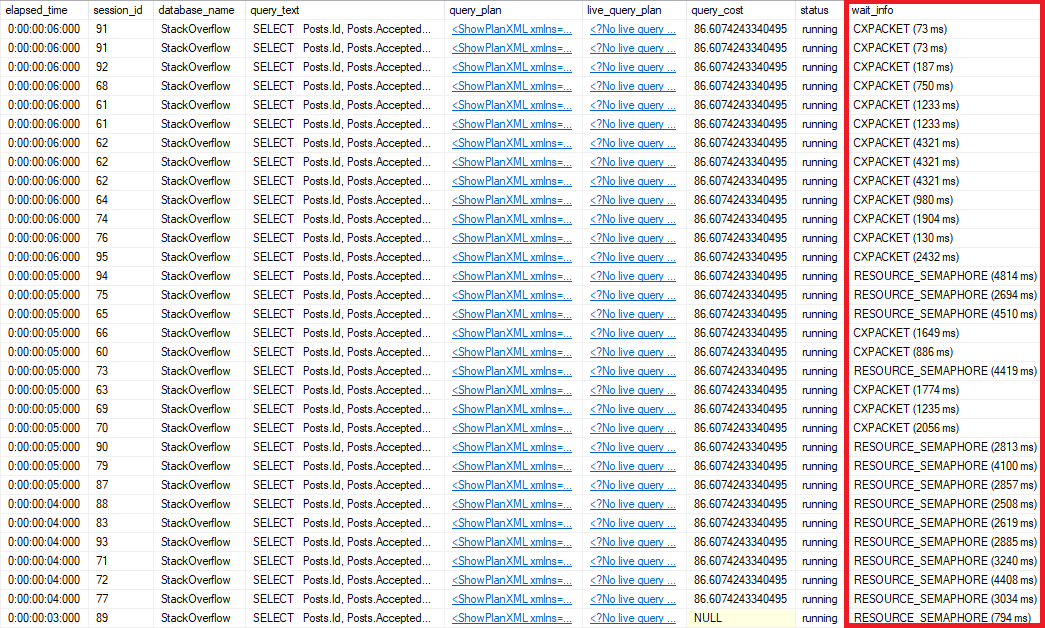
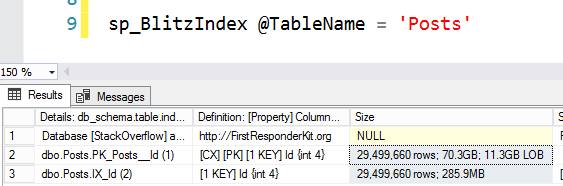
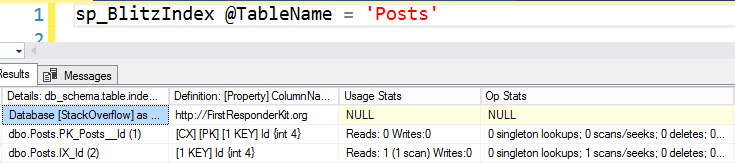
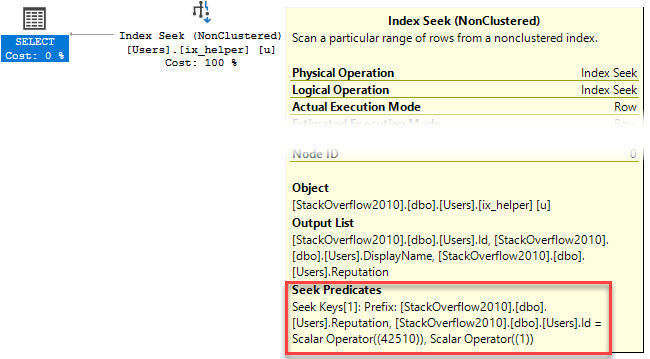
Here’s what I occasionally see when the query runs, using sp_BlitzWho:

I’m selecting data from users.
It’s being blocked by an insert into Badges.
There’s weird code running preventing my query from finishing.
What’s The Problem?
Someone had tried to be clever. Looking at the code running, if you’ve been practicing SQL Server for a while, usually means one thing.
A Scalar Valued Function was running!
In this case, here’s what it looked like:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE OR ALTER FUNCTION dbo.BadIdea ( @uid INT ) RETURNS BIGINT WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING AS BEGIN DECLARE @BCount BIGINT; SELECT @BCount = COUNT_BIG(*) FROM dbo.Badges AS b WHERE b.UserId = @uid GROUP BY b.UserId; RETURN @BCount; END; |
Someone had added that function as a computed column to the Users table:
|
1 |
ALTER TABLE dbo.Users ADD BadgeCount AS dbo.BadIdea(Id); |
Abhorrent
I know, I know. Bad, right? Who would ever do this, right?
We get some funny emails.
Now, in the past, I’ve written about Scalar Functions from a performance and parallelism angle here, here, and here.
I can feel the question coming: Can’t I just persist that computed column?
Nope.

Computed column ‘BadgeCount’ in table ‘Users’ cannot be persisted because the column does user or system data access.
Or surely we can index it.
Nope.

Column ‘BadgeCount’ in table ‘dbo.Users’ cannot be used in an index or statistics or as a partition key because it does user or system data access.
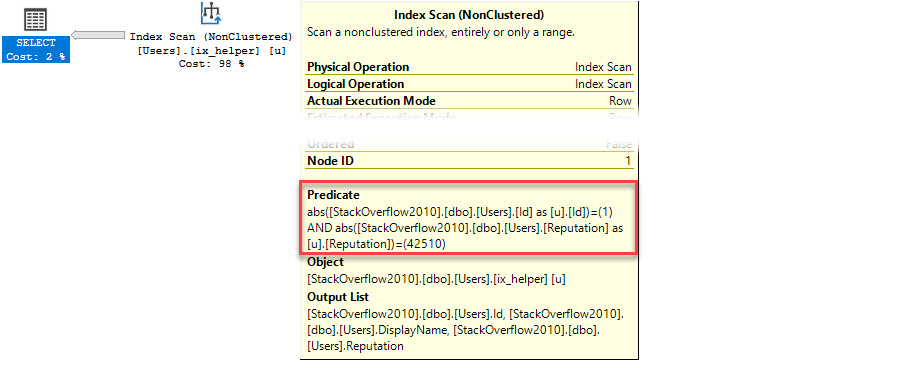
Without being able to do either of those things, our function does a couple nasty things to our query
- Executes for each row returned to grab the count of badges
- Forces it to run serial
Unfortunately, workarounds for the parallelism issue aren’t applicable here, since we can’t persist it.
You Can Guess…
This made all sorts of things like concurrency, locking, and blocking very tricky to figure out.
There’s an expectation that when someone writes a single-table query, their only concern should be that table. If we were to add additional joins, or additional aggregating functions as computed columns to other tables, we’d be making things even worse.
Hiding code like that in a function, and then hiding the function in a computed column may seem like a nice trick, but it doesn’t help performance, and it doesn’t make issues any more clear when you take all these new found SQL skills and run off to your Brand! New! Job! Leaving them as an exercise to the [next person].
And the workarounds weren’t any more pleasant.
- We could have added a trigger on the Badges table to update the Users table whenever someone got a Badge added.
- We could have had a process run every so often to recalculate Badge counts
- We could have made an indexed view to pre-aggregate the data
There’s nothing wrong with any of those in theory, but they’d require a lot of extra development and testing.
Something that hadn’t been done with the computed column.
Thanks for reading!