Does It Matter Which Field Goes First in an Index?
9 Comments
Let’s take the dbo.Users table from the Stack Overflow database, which holds exactly what you think it holds – the list of users:

Say I want to count up all of the people with 1 reputation point:
|
1 |
SELECT COUNT(*) FROM dbo.Users WHERE Reputation = 1; |
Without any indexes, that would scan the whole table. So to make it go faster, let’s create an index on Reputation:
|
1 |
CREATE INDEX IX_Reputation ON dbo.Users(Reputation); |
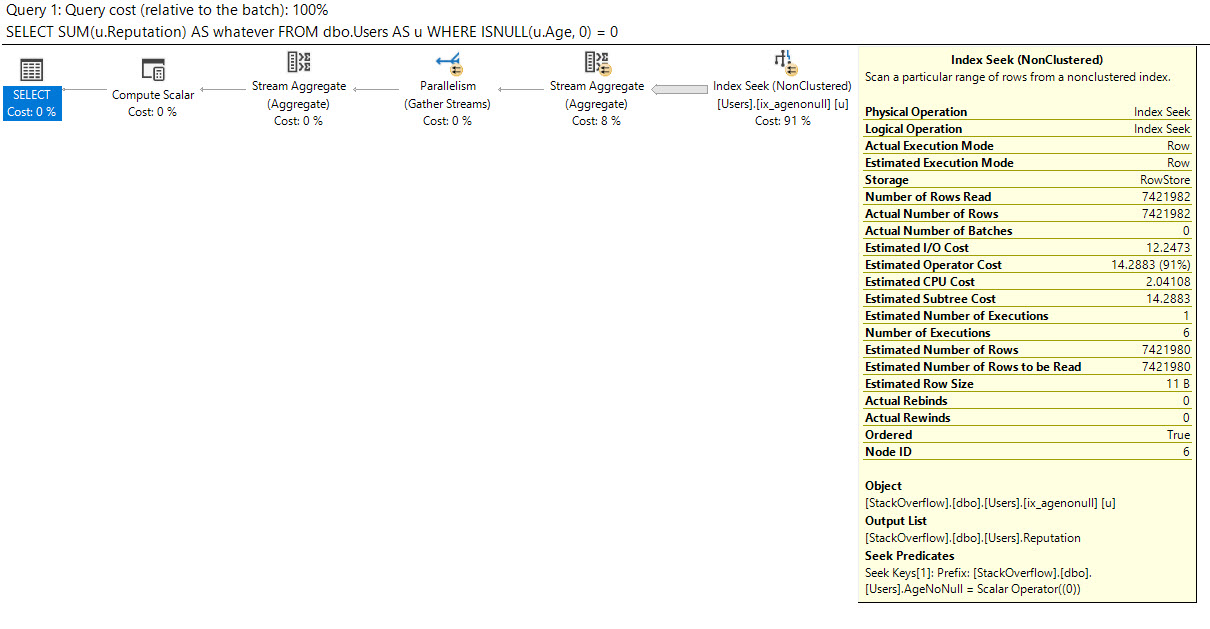
SQL Server uses the Reputation index for the count query:

It does a seek to Reputation = 1, and reads all of the users up to Reputation = 2. If you hover your mouse over the Index Seek operator on modern versions of SQL Server, you get some interesting details:

- Estimated Number of Rows to be Read = 3.3 million
- Actual Number of Rows Read = 3.3 million
- Actual Number of Rows = 3.3 million
There are a lot of people at Stack who only have 1 reputation point. SQL Server knows this because of the statistics created when the IX_Reputation index was created. So far, so good.
Now let’s filter for two things.
Let’s add a second part to our WHERE clause:
|
1 |
SELECT COUNT(*) FROM dbo.Users WHERE Reputation = 1 AND DisplayName = 'Brent Ozar'; |
SQL Server won’t use the Reputation index for this query because so many users match Reputation = 1, and it would have to do key lookups across all of them to get all their DisplayNames. That wouldn’t be efficient, so it just chooses to do a clustered index scan.

Not a surprise there – we’re going to need to create an index. First, let’s try just adding DisplayName to our existing index:
|
1 |
CREATE INDEX IX_Reputation_DisplayName ON dbo.Users(Reputation, DisplayName); |
Run our query again, and it uses the new index:

SQL Server can seek to Reputation = 1, and then seek to the rows where DisplayName = ‘Brent Ozar’. Hover your mouse over the Index Seek, and now not only are we producing (outputting) less rows, but we’re also reading way less rows:
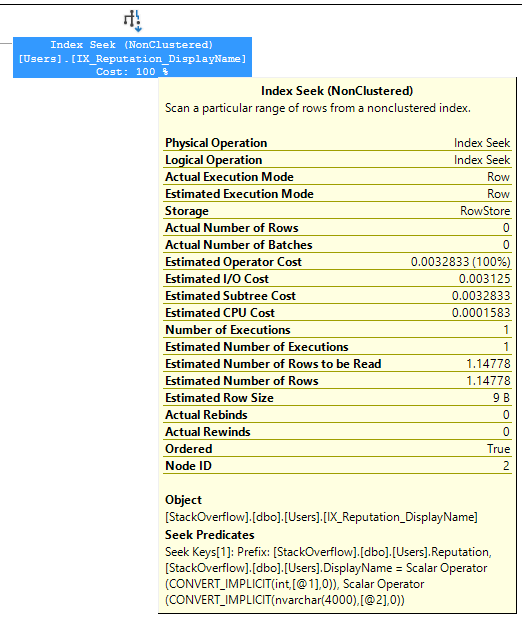
- Estimated Number of Rows to be Read = 1.15
- Actual Number of Rows Read = well, unknown, hidden, but trust me, none were read because…
- Actual Number of Rows = 0
That’s a super-fast operation! Good stuff. If we drop that index, and replace it with one where DisplayName goes first:
|
1 2 |
DROP INDEX IX_Reputation_DisplayName ON dbo.Users; CREATE INDEX IX_DisplayName_Reputation ON dbo.Users(DisplayName, Reputation); |
And run our query again, SQL Server uses the index. Let’s look at the properties on that index’s seek:

- Estimated Number of Rows to be Read = 1
- Actual Number of Rows Read = well, unknown, hidden, but trust me, none were read because…
- Actual Number of Rows = 0
In this case, it doesn’t matter which field goes first. We’re searching for an equality on two columns, so we can seek directly on both of them.
Let’s try a different search query, though.
Instead of equalities on both things in the WHERE clause, let’s have one of them be an equality, and one of them be a range scan. Let’s say Reputation > 1 – which is a minority of the table. (The majority have Reputation = 1.)
|
1 |
SELECT COUNT(*) FROM dbo.Users WHERE Reputation > 1 AND DisplayName = 'Brent Ozar'; |
Since we still have an index on DisplayName, Reputation, the query plan does a seek on that index – seeking directly to DisplayName = ‘Brent Ozar’ – and then scans through all of those folks looking for the ones where Reputation > 1. It’s called a seek because that’s how we start, basically:

If I hover my mouse over the seek to see the properties:
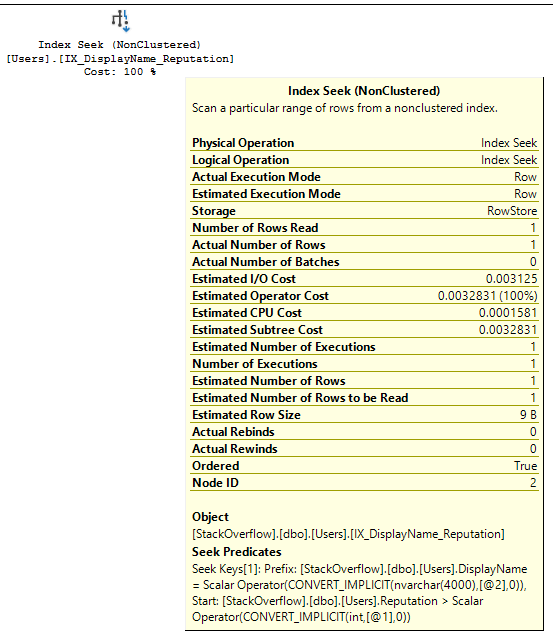
- Estimated Number of Rows to be Read = 1
- Actual Number of Rows Read = 1
- Actual Number of Rows = 1
That’s a nice, lightweight, fast seek. But now let’s drop that index, and replace it with one where Reputation is first:
|
1 2 |
DROP INDEX IX_DisplayName_Reputation ON dbo.Users; CREATE INDEX IX_Reputation_DisplayName ON dbo.Users(Reputation, DisplayName); |
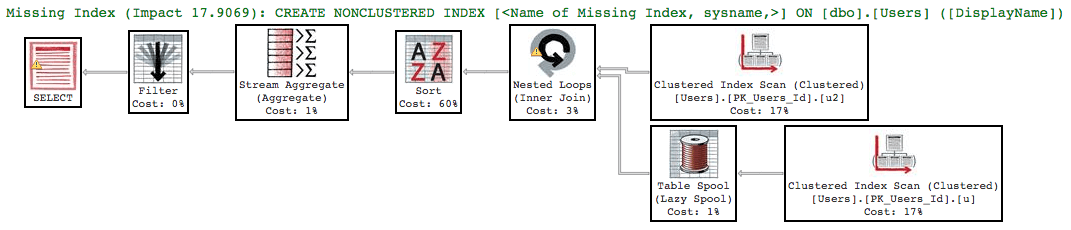
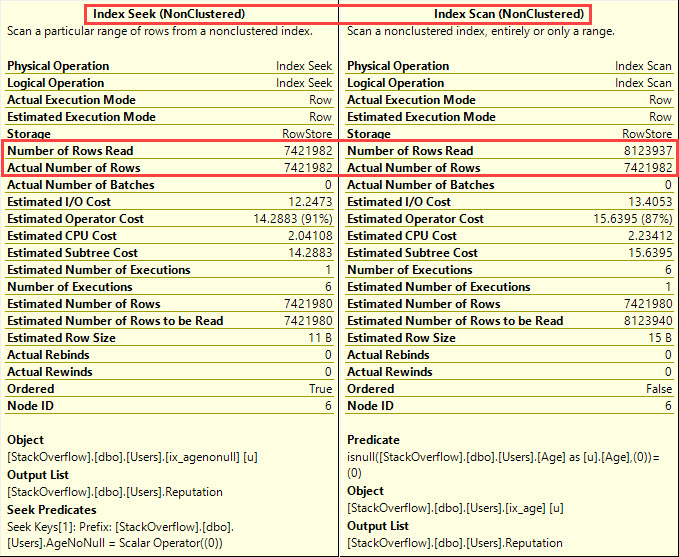
And run our query again. It’s a seek, but, uh…wait…

We get a missing index request because SQL Server knows there’s a problem here. Hover your mouse over the index seek to see the properties, and you’ll see it too:

- Estimated Number of Rows to be Read = 1,999,120
- Actual Number of Rows Read = 1,999,122
- Actual Number of Rows = 1
SQL Server had to read two million users in order to find the row that matched. That’s not a seek, it’s arms race. Because the data’s organized by Reputation first, SQL Server “seeks” to the first Reputation >1 – meaning, it seeks to Reputation = 2 – but then it has to keep reading the rest of the table. Brent Ozar could be anywhere, at any reputation level.
Index field order matters a LOT.
In order to pick the right field order, you need to understand the selectivity of the data, the selectivity of your queries, and whether you’re doing equality searches or inequality searches, and what happens to the data after you retrieve it – like how it needs to be joined or ordered.