
A Surprising Simplification Limitation
When It Comes To Simplification
Rob Farley has my favorite material on it. There’s an incredible amount of laziness ingenuity built into the optimizer to keep your servers from doing unnecessary work.
That’s why I’d expect a query like this to throw away the join:
|
1 2 3 4 |
SELECT COUNT(u.Id) FROM dbo.Users AS u JOIN dbo.Users AS u2 ON u.Id = u2.Id; |
After all, we’re joining the Users table to itself on the PK/CX. This doesn’t stand a chance at eliminating rows, producing duplicate rows, or producing NULL values. We’re only getting a count of the PK/CX, which isn’t NULLable anyway and…
Well, you see my point. It’s utterly useless as a JOIN.
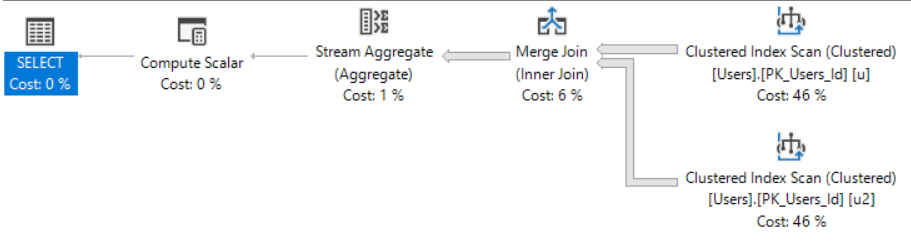
This isn’t one of those cheeky moments where I show you that the second index scan doesn’t do any work or return any rows, either.
If we compare the stats time and IO of these two queries:
|
1 2 3 4 5 6 7 |
SELECT COUNT(u.Id) FROM dbo.Users AS u; SELECT COUNT(u.Id) FROM dbo.Users AS u JOIN dbo.Users AS u2 ON u.Id = u2.Id; |
The second one does exactly twice the IO.
|
1 2 3 |
Table 'Users'. Scan count 1, logical reads 12533 Table 'Users'. Scan count 2, logical reads 25066 |
What Does This Mean For You?
Probably not much, unless you need to make a query do a lot of extra work without changing the logic.
Is this a major flaw in SQL Server’s optimizer? No, not at all.
In fact, if you work at Microsoft on the optimizer team, and you’re reading this, don’t spend one second trying to change the behavior. People aren’t out there doing this and hitting the roof about it.
It’s just one of those things that caught my attention while I was writing some demos up.
Thanks for reading!

16 Comments. Leave new
At my work we are actually running into this problem. We have a view that joins a ton of tables (like these tables can be weighed). But we only grab a few columns from the table each time and those columns are chosen by the user, so it can be random. So, what to do? We are going to have to figure out have to dynamically create the joins depending on what columns will be chosen. I was hoping SQL Server would figure it out for us. But I saw the same thing that you showed above.
Jon — what exactly are you running into? If joins aren’t being eliminated when you don’t select columns from a table, there’s usually a good reason. If you’d like, post an example on dba.stackexchange.com.
Oh, so SQL Server is supposed to be able to eliminate unused joins in views?
Yes, you should check out Rob’s talk. He goes into excellent detail on the subject. It’s the first link in the post 😉
Hmmm… Seems to be an error on the page and I can’t seem to find an alternative download location. I’ll submit a ticket to them.
If FKs (enabled and checked) are in place it can definitely eliminate the join if you’re not actively selecting columns from it. It’s also smart enough to know that even if the column is exposed in the view, but you don’t select it, then it can eliminate the join still. I’ve also noticed it has the same behaviour with apply.
Now here’s where someone tells me that even with an FK it might not eliminate…
The way we have our database set up it doesn’t have FKs unfortunately. It is set up with a parent/child table that you have to query to get which parent a table has. We are actually actively discussing on a plan to remove this since it is causing so many perf issues and makes it harder to understand what is going on. Not sure why the original developer chose to do it that way. It definitely added flexibility at the beginning when they weren’t sure how everything was going to work. But now that we have 20/20 hindsight we can see that it isn’t working out so nicely.
Now I understand why
joinelimination wasn’t working out for when I tested it. I’m glad there are people that write SQL blogs and that I follow them. I might not have ever stumbled on this information otherwise!Jon — happy to have helped in some small way.
You could also try adding a RECOMPILE hint to the query, which will allow the optimizer to build the best plan for the specific parameter values of each execution, and could allow it to avoid joins. Make sure you take into account the cost of repeated recompilations, though.
Alex — careful here. Recompile really only instructs the optimizer to embed variables as literals, and not cache the plan.
Erik, yup, it has a cost that could be too high. Definitely not recommended for all cases! Still, for cases of infrequent executions, the embedding of parameters and variables as literals could be a great help to remove parts of the execution plan that are irrelevant for that execution.
Alex, sorry, I’m missing your point on this one. There are no variables here, and it won’t remove the join.
What am I missing?
Thanks
Looks like we reached the reply limit so I’ll reply here.
As I understood Jon’s question, they have a huge view from which they select only some of the columns, according to user input. This means to me — and maybe I’m missing something — that there’s a huge query on the view, with expressions based on parameters to select only the relevant parts of the view.
Oh, I see, it was a reply to another part of the thread. My bad.
If we replace the INNER JOIN with a LEFT JOIN, the optimizer do discard the unused join. When you join a table to itself, LEFT or INNER on the PK should always produce the same result anyway.
Why would you want to join a table on itself ? Sometimes if you’re using a complex view which is missing a field in one of its table, you have to join that table to itself to get it. Of course you could add the missing field directly in the view but in a complex system you may create an undesired side-effect.
Emmanuel – here at the blog, we often build queries to reproduce a problem that a client is seeing out in the wild. We can’t show you their exact queries (for fairly obvious reasons), so we build similar queries with the Stack Overflow database.
You’d be surprised how often one needs to join a table to itself – for example, pick up the Stack Overflow database yourself and get the text of a question plus the text of all of its answers. You’ll see a self join in effect right there.