
With each new version of SQL comes a slew of new stuff
While some changes are cosmetic, others bewildering, and the rest falling somewhere between “who cares about JSON?” and “OH MY GOD TAKE MY MONEY!”, but not really my money, because I only buy developer edition. Aaron Bertrand has done a better job finding, and teaching you how to find new features than I could. Head over to his blog if you want to dive in.
What I wanted to look at was something much more near and dear to my heart: Parallelism.
(It’s so special I capitalized it.)
In the past, there were a number of things that caused entire plans, or sections of plans, to be serial. Scalar UDFs are probably the first one everyone thinks of. They’re bad. Really bad. They’re so bad that if you define a computed column with a scalar UDF, every query that hits the table will run serially even if you don’t select that column. So, like, don’t do that.
What else causes perfectly parallel plan performance plotzing?
Total:
- UDFs (Scalar (but maybe not for long!), MSTVF)
- Modifying table variables
Zone:
- Backwards scan
- Recursive CTE
- TOP
- Aggregate
- Sequence
- System tables
- OUTPUT clause
Other:
- CLR functions (that perform data access)
- Dynamic cursors
- System functions
We’ll just look at the items from the first two lists. The stuff in Other is there because I couldn’t write a CLR function if I had Adam Machanic telling me what to type, cursors don’t need any worse of a reputation, and it would take me a year of Sundays to list every internal function and test it.
I’m going to depart from my normal format a bit, and put all the code at the end. It’s really just a mess of boring SELECT statements. The only thing I should say up front is that I’m leaning heavily on the use of an undocumented Trace Flag: 8649. I use it because it ‘forces’ parallelism by dropping the cost threshold for parallelism to 0 for each query. So if a parallel plan is possible, we’ll get one. Or part of one. You get the idea.
Just, you know, don’t use it in production unless you really know what you’re doing. It’s pretty helpful to use as a developer, on a development server, to figure out why queries aren’t going parallel. Or why they’re partially parallel.
All of this was run on 2016 CTP 3.1, so if RTM comes along, and something here is different, that’s why. Of course, backwards scans are probably close to 15 years old, so don’t sit on your thumbs waiting for them to get parallel support.
Backwards scan!

Scalar!

Table with computed column

MSTVF

Table Variable Insert

Top

Aggregating

Row Number (or any windowing/ranking function)

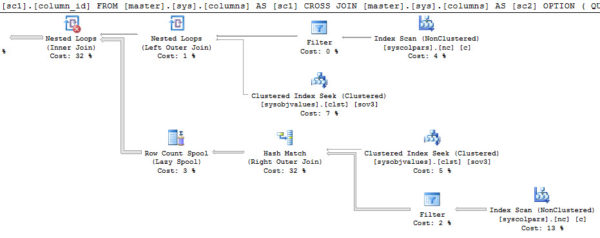
Accessing System Tables
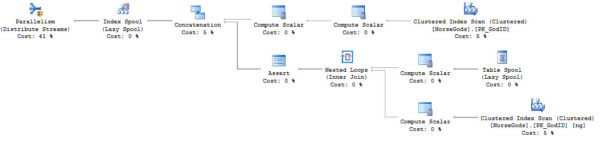
The recursive part of a recursive CTE
Picture time is over
Now you get to listen to me prattle on and on about how much money you’re wasting on licensing by having all your queries run serially. Unless you have a SharePoint server; then you have… many other problems. If I had to pick a top three list that I see people falling victim to regularly, it would be:
- Scalar functions
- Table variables
- Unsupported ORDER BYs
They’re all relatively easy items to fix, and by the looks of it, we’ll be fixing them on SQL Server 2016 as well. Maybe Query Store will make that easier.
Thanks for reading!
Das Code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 |
USE StackOverflow; SET NOCOUNT ON; GO /*Scalar*/ CREATE FUNCTION dbo.ScalarValueReturner ( @id INT ) RETURNS INT WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING AS BEGIN RETURN @id * 1; END; GO /*MSTVF*/ CREATE FUNCTION dbo.MSTVFValueReturner ( @id INT ) RETURNS @Out TABLE ( Returner INT ) WITH SCHEMABINDING AS BEGIN INSERT INTO @Out ( Returner ) SELECT @id; RETURN; END; GO SELECT Id FROM dbo.Users WHERE Id BETWEEN 1 AND 10000 ORDER BY Id DESC OPTION ( QUERYTRACEON 8649, RECOMPILE ); SELECT Id, dbo.ScalarValueReturner(Id) FROM dbo.Users WHERE Id BETWEEN 1 AND 10000 OPTION ( QUERYTRACEON 8649, RECOMPILE ); SELECT Id, ca.Returner FROM dbo.Users CROSS APPLY dbo.MSTVFValueReturner(Id) AS ca WHERE Id BETWEEN 1 AND 10000 OPTION ( QUERYTRACEON 8649, RECOMPILE ); DECLARE @t TABLE ( Id INT ); INSERT @t SELECT Id FROM dbo.Users WHERE Id BETWEEN 1 AND 10000 OPTION ( QUERYTRACEON 8649, RECOMPILE ); SELECT TOP ( 10000 ) u.Id, ca.Id AS Returner FROM dbo.Users AS u CROSS APPLY ( SELECT u2.Id FROM dbo.Users AS u2 WHERE u2.Id = u.Id ) AS ca WHERE u.Id BETWEEN 1 AND 10000 OPTION ( QUERYTRACEON 8649, RECOMPILE ); SELECT AVG(CAST(dt.Reputation AS BIGINT)) AS WhateverMan FROM ( SELECT u.Id, u.Reputation FROM dbo.Users AS u JOIN dbo.Posts AS p ON u.Id = p.OwnerUserId WHERE p.OwnerUserId > 0 AND u.Reputation > 0 ) AS dt WHERE dt.Id BETWEEN 1 AND 10000 OPTION ( QUERYTRACEON 8649, RECOMPILE ); SELECT Id, ROW_NUMBER() OVER ( PARTITION BY Id ORDER BY Id ) AS NoParallel FROM dbo.Users WHERE Id BETWEEN 1 AND 10000 OPTION ( QUERYTRACEON 8649, RECOMPILE ); SELECT TOP ( 10000 ) sc1.column_id FROM master.sys.columns AS sc1 CROSS JOIN master.sys.columns AS sc2 CROSS JOIN master.sys.columns AS sc3 CROSS JOIN master.sys.columns AS sc4 CROSS JOIN master.sys.columns AS sc5 OPTION ( QUERYTRACEON 8649, RECOMPILE ); CREATE TABLE dbo.NorseGods ( GodID INT NOT NULL, GodName NVARCHAR(30) NOT NULL, Title NVARCHAR(100) NOT NULL, ManagerID INT NULL, CONSTRAINT PK_GodID PRIMARY KEY CLUSTERED ( GodID ) ); INSERT INTO dbo.NorseGods ( GodID, GodName, Title, ManagerID ) VALUES ( 1, N'Odin', N'War and stuff', NULL ), ( 2, N'Thor', N'Thunder, etc.', 1 ), ( 3, N'Hel', N'Underworld!', 2 ), ( 4, N'Loki', N'Tricksy', 3 ), ( 5, N'Vali', N'Payback', 3 ), ( 6, N'Freyja', N'Making babies', 2 ), ( 7, N'Hoenir', N'Quiet time', 6 ), ( 8, N'Eir', N'Feeling good', 2 ), ( 9, N'Magni', N'Weightlifting', 8 ); WITH Valhalla AS ( SELECT ManagerID, GodID, GodName, Title, 0 AS MidgardLevel FROM dbo.NorseGods WHERE ManagerID IS NULL UNION ALL SELECT ng.ManagerID, ng.GodID, ng.GodName, ng.Title, v.MidgardLevel + 1 FROM dbo.NorseGods AS ng INNER JOIN Valhalla AS v ON ng.ManagerID = v.GodID ) SELECT Valhalla.ManagerID, Valhalla.GodID, Valhalla.GodName, Valhalla.Title, Valhalla.MidgardLevel FROM Valhalla ORDER BY Valhalla.ManagerID OPTION ( QUERYTRACEON 8649, RECOMPILE ); |

30 Comments. Leave new
“It’s so special I capitalized it.”
Parallelism [sic]?
Perhaps in an earlier draft. I know, picky, picky.
Thanks for this article. I’m not sure I got it all but it was informative and useful.
Cheers.
Google and I are at least 99% sure we spelled parallelism correctly.
I think he was expecting PARALLELISM. But it’s not THAT special!
So wait… Table Variables are bad and so are cursors? Then what should I use? Or is that a loaded question?
I know I know, we shouldn’t have to enumerate through our data. But then again, I should be rich instead of just good looking. 🙂
Hey thanks for the great article.
Hi! I prefer temp tables to table variables, hands down. As for cursor replacements, it depends on what you’re trying to do.
Can you briefly explain why, or point me to an article? I haven’t been writing queries long, but I have been trying to use table variables wherever possible because they seem to work a little faster and I also appreciate that they require less cleanup than temp tables. I’m not working with vast amounts of data typically; but I want to start good habits now if I can.
Also, I’m still struggling to replace cursors in my algorithms with better logic; can you point me to any articles that might help me wrap my head around ways to do cursory things without cursors? Thanks!
Fred – we’ve actually got a whole online course about it, believe it or not! Check this out:
https://learnfrom.brentozar.com/product/t-sql-level-up-18-months-access/
That’s pretty much exactly what I was looking for, thank you! I love the site but I’m still exploring 🙂
I can give you exactly one reason why you might want to use table variables over temp tables: internationalization.
But still, table variables… who came up with them?
Calin – errr, what does internationalization have to do with it?
N00b question here: if aggregates cause serial plans, then why is there a stream aggregate in the screenshot?
Only the aggregation part will go serial, the “read-the-data-part” will be parallel. On the other hand, some aggregations could be become more tricky if they are parallel.
Did a bit more research. Aggregation itself doesn’t cause a plan to go serial. A big part of the aggregation can be done in parallel. You just need a serial aggregation at the end to aggregate the different results of the parallel streams, which seems totally logical to me.
So I don’t really agree with how aggregates are portrayed here in this blog post; as they are bad for parallelism. Algorithm-wise they can’t be calculated for 100% in parallel, but the heavy load of calculating the aggregate can be done in parallel.
Hey Koen, it causes a serial zone in the plan, which was my only point. Several of the operators do, that’s why I differentiated between which each causes at the beginning of the post — zone or full serialization — so when people look at execution plans, they don’t think something is wrong when an aggregation is serialized.
You mentioned sequences — how do they cause issues?
Thanks
Hi! Not sequences like the identity generating sequences. I’m referring to the Sequence (Project) operator that is used in execution plans that call windowing functions. It’s up there in one of the screen grabs.
Would be good to clarify in the article that as it reads as if you are referring to Sequence object types.
Great article.
How about if the computed column is Persisted?
No, doesn’t matter.
USE [tempdb]
SET NOCOUNT ON
;WITH E1(N) AS (
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL ),
E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j),
Numbers AS (SELECT TOP (10000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2)
SELECT
IDENTITY (BIGINT, 1,1) AS [ID]
INTO [ComputedColumns]
FROM [Numbers] [N]
ORDER BY [N] DESC
;
ALTER TABLE [dbo].[ComputedColumns] ADD [CompCol] AS [ID] * 2 PERSISTED
SELECT [cc].[ID]
FROM [dbo].[ComputedColumns] AS [cc]
OPTION(QUERYTRACEON 8649)
DROP TABLE [dbo].[ComputedColumns]
Wow that is bad. Thanks!
I think you want “me” not “be” in the first paragraph after “PICTURETIME IS OVER” header.
Great article.
This isn’t really for posting… I think/hope these comments are moderated?
Fixed!
I think inline TVF is not so bad
You think right! Table valued functions are cool in my book.
This is a fantastic article, I keep coming back here to re read it.
Just to clarify, do all computed columns cause serial plans, or just those using scalar functions?
And does it cause a serial zone, or completely serial plan?
I’ve often heard good things about computed columns, but this is definitely something to consider.
Hey, thanks! So for computed columns, it’s only the kind that reference scalar functions, and as far as my testing has shown it’s the entire plan.
Phew. Came here looking for this. I was plowing through the courses this weekend (hellooooo Black Friday deal!) and I thought you meant all Computed Columns, but your specific video on them made them seem magical.
The heading for them here ^ also made me do a double-take. Glad to know it’s just the ones I’d never do, because functions are pretty bad all round.
Hello Erik,
I think for ranking functions you can get serial execution (Sequence Project +Segment)
but parallel execution is also possible with new Window Aggregate operator that can use multiple threads.
Simple example on Wide World Importers DB:
SELECT ROW_NUMBER() OVER(PARTITION BY i.DeliveryMethodID ORDER BY i.InvoiceID) AS RN,
i.InvoiceID
FROM Sales.Invoices i
INNER JOIN Sales.InvoiceLines il ON il.InvoiceID = i.InvoiceID
/*DUMMY TABLE JOIN*/
LEFT JOIN dbo.ForBatchModeOnly ON 1 = 2
WHERE i.InvoiceID < 100000
GO
Accessing System Tables – The use of TOP kinda overshadows the demonstration of sys tables killing the parallelism doesn’t it?
Justin – I’m not sure what you mean about accessing system tables. Can you rephrase the question?