
Should I Worry About Index Fragmentation?
Here’s a handy flowchart for whenever you find yourself worrying about fragmentation:
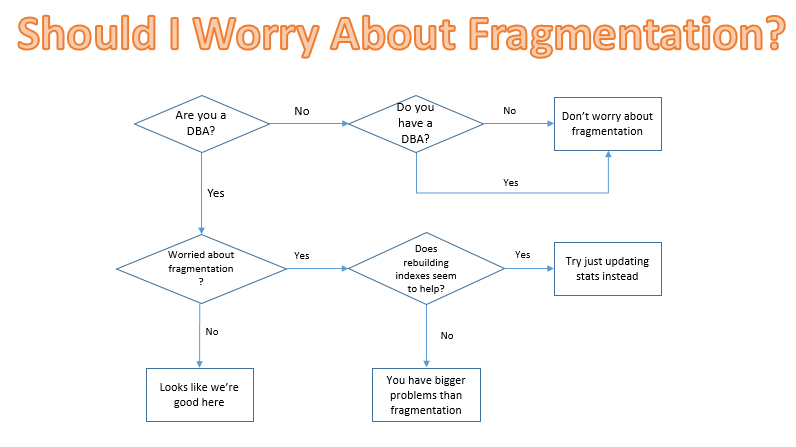
*Talk to your doctor about whether fragmentation is a problem for you. Seek help for index maintenance lasting longer than four hours. Serious side effects may occur if all index maintenance is ignored completely.
Brent says: pop quiz: what are you doing more often, rebuilding indexes or running DBCC CHECKDB?

34 Comments. Leave new
Brent – CheckDB FTW!
Doug, great flowchart. Looks like I’ll leave the index fragmentation witchcraft to the big guys.
Brent, you had the perfect opportunity for a “pop quiz hotshot”, but you blew it!!
Checkdb once a week; we also have page verify turned on and scan msdb.dbo.suspect_pages every day. We don’t rebuild indexes because it’s too hard to quantify the impact to applications even with that short blocking of an online rebuild; so we use Hallengren scripts set to only reorganise where needed and update stats that have changed (once a week after the checkdb).
This has not caused any performance issues in our environment.
After this we do our weekly full backup (and keep the last one; plus more) so that we’d have something to restore a corrupt page from if we needed to. This hasn’t happened yet; we’ve had other corruptions but they were due to the 2012/2014 index bugs, user restores of corrupted backups (somehow!), and others from when we’ve “taken ownership” of servers but these were addressed in other ways.
I know that Paul Randal would suggest running Checkdb constantly but across hundreds of servers it would degrade even our multi-million dollar SAN storage. We think we’ve adequately covered bases with how we have it.
I like to tell people that rebuilding indexes is a tremendously expensive way to update statistics.
I have a framed screen cap of this comment that I keep over my desk.
I just use Ola’s job to rebuild old and sad indexes.. and rebuild uncared stats.
Is that so wrong? ;(
I hate to comment on this, because the behavior I’m about to describe is not something I could find documented, and you’re not going to believe me 🙂
What I saw, though, is that when indexes got severely fragmented, they were no longer used in the execution plan. I know. It’s not supposed to be the case. I’m telling you, though, I saw it with my own eyes! (Just like the guy who got kidnapped by the aliens)
In our case, our software was incorrectly written and depended on SQL Server using the index in order to return the results in the correct order. (Again, I know – that’s very sick and wrong, but it happens)
Just saying, I know that what I’m describing here may be an edge case, but these exist, and maybe there should be something in your flow-chart to address people in tinfoil hats who talk about things that can’t possibly exist but which we’ve seen with our own eyes. 😉
Ugh. Now I don’t even want to sign my name to this. Oh, well. I’ll be over here discussing your potential replies with my pal Big Foot …
I’ve seen some weird stuff and I totally believe you. Did you try updating stats without the rebuild? I’d be curious to hear what happened if you did. What you’re describing is definitely a “talk to your doctor about fragmentation” scenario.
This actually isn’t an edge case scenario. If the size (number of pages) in an index ABC increases (due to fragmentation) to the point where the IO for index DEF is lower than that of index ABC, then the cost of the second index will likely be lower as well (with old or new statistics). In most cases, the DEF index will end up being a scan operation on the tables clustered index. Updating the statistics usually will not resolve this since its a matter of index size and the resulting row density.
Jason – just to be clear, you’re saying it’s a common scenario – not an edge case – for a fragmented nonclustered index to be larger in size than the clustered index of the table?
This assumes the following:
* The nonclustered index is fairly wide, with lots of columns
* The clustered index is relatively narrow (doesn’t have many more fields than the nonclustered, especially big varchar fields)
* The nonclustered index has extremely bad internal fragmentation
* The clustered index has nearly no fragmentation (quite an interesting combination)
And you’re saying you run into this often? I totally believe you, just want to make sure I understand your common case scenario.
You could also see that potentially in 2016 with a clustered colstore index (highly compressed and small) and a non-compressed NC rowstore index, but to your point 2016 is still 100% edge-case, so probably not what Jason was referring to….
Apologies, lacked some clarity in my responses. Assumptions I didn’t write out that are needed.
Here’s the a specific scenario that comes to mind. Consider a query that leverages a non-clustered index and a key lookup. The IO requirements for the those two operations can exceed the IO for a scan against a clustered index if enough rows are being accessed. Kimberly Tripp does a great job explaining this in her tipping point blogs.
In cases where the tipping point shouldn’t have been reached, fragmentation is often the cause. Since statistics, accurate or not quite so, indicate that the IO from the scan would perform better than the seek/key lookup.
I see this scenario pretty often. It can happen within a non-clustered index as well, but not too frequently.
The real point I was trying to make is that this behaviour isn’t weird but driven by the statistics on the table. Refreshing stats wouldn’t change the behaviour.
This all said, defragmenting a database to fix performance is a bad idea. Defragment an index when you’ve identified this specific scenario first.
Hopefully this is more clear
PS – Yes, I misspelled behaviour, I like the UK spelling better.
Jason – hahaha, okay, that makes much more sense. In that case, though, I’d zoom back a little and say that rather than fixing it with fragmentation, I’d make a huuuuge difference by turning the index into a covering one. (Unless of course the include fields are huge – but at that point, you’re going to be doing lots of high-IO lookups against the clustered index anyway, and then defrags won’t save us there either.)
The only way to guarantee the order of the results is to use the order by clause. An index will not cut it, and I would not rely on it within any code.
This is documented in BOL
So, when you have MS come in and do their health assessment of your environment and one of the things they look at is fragmentation, they seem to flag any tables/indexes that have more than 5000 pages and is more than 30% fragmented. With a busy SCCM (or other configuration management product) database, it takes about 90 minutes after a full rebuild of indexes to cross that threshold. I like to tell them we have weekly maintenance that handles it and to stuff it. I can’t see a good reason to do it daily or > weekly, do you? It’d be one thing if we had performance problems we needed to track down, but when the system is working as advertised…I’m just not feeling it.
Yeah, if its not broken, no reason to try and fix it. I have seen times when rebuilding a select index or maybe a handful of indexes on a daily or even twice daily schedule was helpful, but that was always in response to a very specific problem that was causing the business a lot of head aches.
Taking the time and resources to rebuild the indexes on a more then weekly basis, just to make sure your metrics look good is crazy.
The flow chart should have a link to Ola’s IndexOptimize code and end with, “Don’t Worry about Fragmentation or Stats”.
hmm. interesting question.
Is it because of OLTP system such as most query do not scan and only pick necessary couple of pages?
I thought, it’s also “depends”…
I thought, you should add more condition on this chart.
Very good OLTP system, enough memory and very good Design, I absolutely agree with this chart.
Even that is, you probably do not recommend to run DBCC shrink for data file.
But, not a good table design, a lot of ad hoc query, a lot of ETL job and e.t.c.
I thought, we should be care Index fragmentation.
To be clear, you should not ignore index fragmentation completely. My point is that you shouldn’t *worry about it* causing major performance issues, especially if you do index maintenance on a reasonable schedule — say, once a week. Even on a poorly-designed database, adding high-value missing indexes is far more effective than defragmenting existing indexes.
I say “Try updating stats instead” as a method of proving it’s a stats problem versus a fragmentation problem. Often times it’s the stats that lead to bad query behavior.
Thank you for your comments. It makes sense.
That’s why I’m worrying about index fragmentation atm. Just got into new place that had no DBA ever before. So I’ve found this little SAPish database (around 2.7TB?) that has up to 90-97% fragmentation on most of indexes, ouch.
Combined with not that often transact log backups, some obvious configuration problems and some other issues (“yea, one of programmers thought it’s too slow so he started adding indexes” is one of them) makes me think index fragmentation is something I have to be worried. At least till I’ll be able to put that monster in cage, get my maintenance window and do that first, very painful (even with Olla’s scripts) rebuild. Then put it on schedule and monitor it.
Luckily some things are covered: backups, checkdb (ok I don’t like it being called on daily scheduly in SAP agent but that might be just my opinion).
Sounds like we’re in similar situations – no DBA ever before at my new job, just Dev’s and some lower experience accidental DBA’s. While I don’t have that one large DB, I have discovered close to 100 instances. 95% of which nobody has ownership or knowledge of, 50% are running on Windows 7, and only 20% I have been able to get access to. Fun times!
Marcin,
That describes my situation last October.
For that first pass through the indexes that have long been ignored, I would omit the largest indexes. Get the 90% of the indexes done that are smaller.
There is a variable to skip certain tables with Ola’s scripts. Skip the big ones initially. Then do the big indexes manually the first time, perhaps one per day or whatever works for you.
They are likely also running with 100% fillfactor. Maybe on rebuild with Ola’s code drop that down also.
Just some ideas to consider for what I wen through a few months ago when whipping this beast into shape.
Never thought about using anything else than Ola’s scripts. But I had different plan. Start with manual rebuilding the worst ones and then bulk work on smaller ones. But your solution might be less painful while still giving some noticeable results.
Fillfactor has to wait till I’ll be able to say how often (and how much) those indexes are fragmenting. There is no point in changing it right now when I’m not even sure it’s needed.
We have Indexes regularly at over 90% fragmented rates. Shouldn’t I be defragmenting them?
Graham – what’s the problem that you’re trying to solve? When you defragment, do users cheer and do you notice a significant performance difference?
Hey Brent,
I haven’t measured the performance difference with and without defragmenting the indexes, so I’m not sure what kind of difference it is making.
I’m just assuming that when I see something like 97% fragmented clustered indexes that that is a bad thing for performance right? We have a lot of down time on our databases on nights and weekends, so it seems like a good time to rebuild.
Not sure about performance overall, but on plates there should be some difference (randoms ftw).
On the other hand – db size. Defragmenting my 2.7TB database resulted in increase of space available from 40GB to 680GB which means db files won’t be growing up soon.
I like to think it shows more about state that database is in. Of course, now it would be time to check how those indexes behave. And I’ll be ok with scheduled Ola’s script, I don’t know, every week, two weeks?.
Showing that “size available” change is more of my business value issue. Showed my manager that yea, I can do stuff that is easily measurable. It opens doors to other changes I would like to test and implement.
I could be wrong but I think one of the reasons we also need to do index rebuilds often is to reduce free space in the memory pages. since sql reads 8kb page into memory first, with a fragmented database, we are reading less data(less no of rows) per page than compared to a healthy database (defragmented).
I agree that many people who don’t dig into the actual root cause often blame fragmented indexes for query performance problems when its actually a stats issue.
One reason we might actually encourage a non-DBA (particularly devs) to actually be concerned about index fragmentation…you pick a bad clustering key and your index is constantly fragmenting, resulting in constant page splitting, wasted white space in the buffer pool and on disk, higher page counts per scan, etc. So as a DBA I appreciate that a developer might be concerned enough to want to ensure that they aren’t creating a massive fragmentation machine that then becomes my headache.
But again, in general, I think more often than not people latch onto index fragmentation as a potential source of slowness when it is stale statistics or who knows what else. I guess I would say, if you can’t explain exactly why and how fragmentation is slowing down your query, you shouldn’t assume its fragmentation, because its probably not!
Another nice thing about automating with Ola’s scripts…you find the fragmentation headaches, which usually boil down to bad clustering key choices. The CommandLog table logs history and if you see a table hitting high fragmentation every day, might be time to go chat with the developer/vendor.
Very well said Nic. /And a nice tip about counting top tables in the CommandLog to help identifying bad clustering key choices! I’m definitely going to start trying that out.
This is perfect. I wish everyone did this.
I potentially have an interesting idea for a blog post in relation to this. The advice which I’ve heard a lot recently is, don’t worry about fragmentation, instead just update statistics…but I’ve noticed on many of my tables that they have upwards of 100 (or more) stats, often times most of these are system generated. When I dig into them, I see that due to AutoStats, they often are sampled at low percentages like 4%. I’m wondering, is there a query or some other way I can determine if the stats are valuable (being used) or if they can be removed (kind of like the unused index query)…on my larger tables, updating my stats can take a when I’ve got a large number of stats to update; so I’m thinking reducing the number of stats may help speed up that process.
I’ve found this post after Erik mentioned it during Office Hours.
Recently i had to alter a table with about a billion rows (halfway the integer range) where the ID column had to be updated from int to bigint. The too obvious alter table alter column would have put the server 6 feet underground so another strategy was needed. An extra column was added and i copied the int value from the ID column to the new bigint column. At first, this was really really slow, in the range of 1000 records per 3 minutes. Not good. The table is partitioned and i even used the partitionkey in the query to get the value.
Some query tuning sped the process op to about 1 million records every hour.
Anyway, updating the statistics didn’t help. Rebuilding the index (fragmention around 60%) did help really really well.
In the end, the process ran at over 100 million records every hour. Still not max speed but good enough for that moment. In the end, rebuilding the index did really help.