The Annals of Hilariously Bad Code, Part 1: Critique the Code
35 Comments
Hey Beavis
That’s the first time I’ve used “annals” correctly. I will be 40 sooner than later.
Sometimes when we blog, we get inspiration from clients, students, other bloggers, questions on Stack Exchange, nightmares, or just drinking heavily.
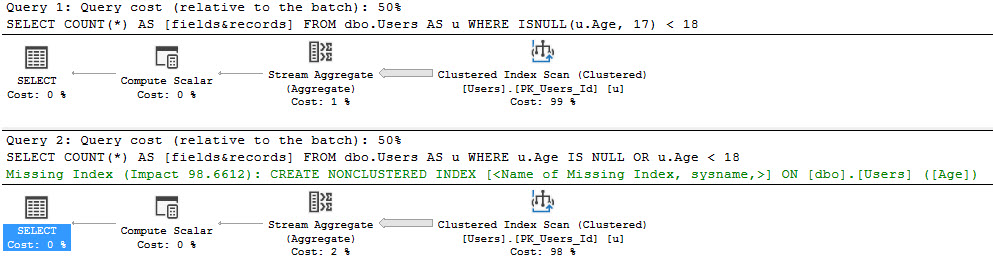
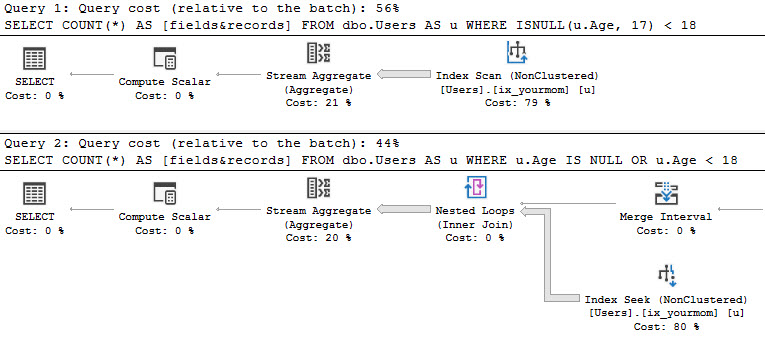
I’m going to anonymize some code, and I want you to guess where it came from.
I’d also like you to to critique the code, to see if it lines up with my feelings on it.
In the next post, we’ll talk about where it came from, and how we’d fix it.
I don’t want any Big Mouths Striking Again! If you happen to recognize the code, don’t tattle.
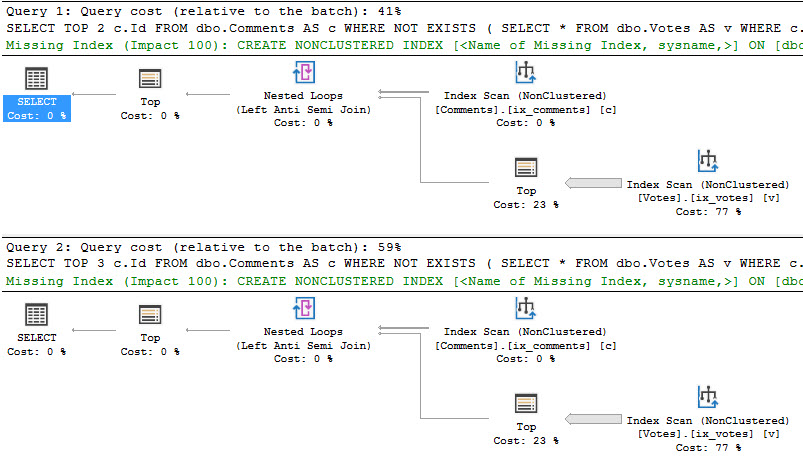
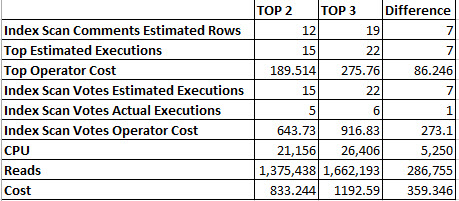
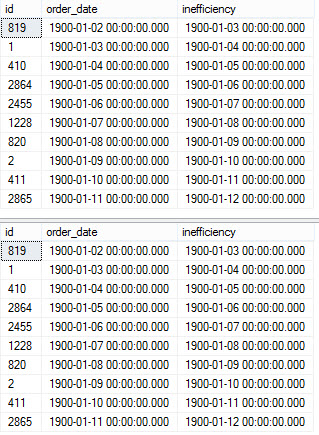
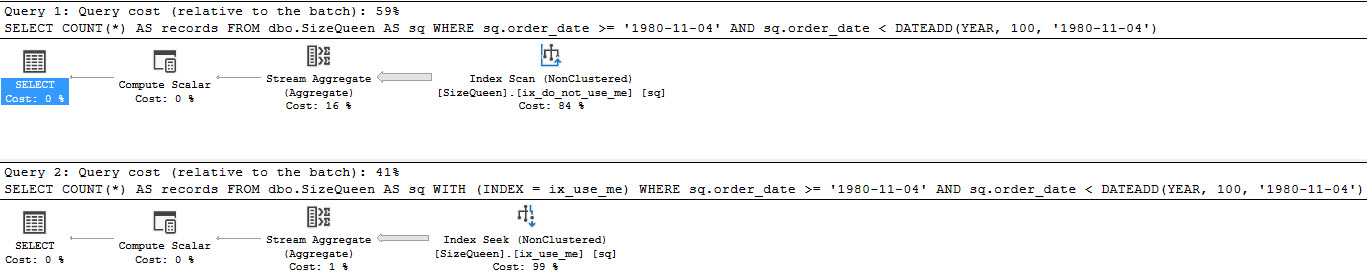
Begin Transmission
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
CREATE OR ALTER PROCEDURE dbo.delete_some_stuff @date DATETIME AS BEGIN SET NOCOUNT ON; DECLARE @b_id TABLE ( b_id INT ); DECLARE @m_id TABLE ( m_id INT ); DECLARE @r_id TABLE ( r_id INT ); INSERT INTO @b_id ( b_id ) SELECT DISTINCT b_id FROM b1 WHERE b_date < @date; INSERT INTO @m_id ( m_id ) SELECT DISTINCT m_id FROM b2 WHERE b_date < @date; INSERT INTO @r_id ( r_id ) SELECT DISTINCT r_id FROM r1 WHERE b_id IN ( SELECT b_id FROM @b_id ); BEGIN TRANSACTION; DELETE FROM b1 WHERE b_id IN ( SELECT b_id FROM @b_id ); IF ( @@error > 0 ) GOTO Quit; DELETE FROM b2 WHERE b_id IN ( SELECT b_id FROM @b_id ); IF ( @@error > 0 ) GOTO Quit; DELETE FROM r1 WHERE r_id IN ( SELECT r_id FROM @r_id ); IF ( @@error > 0 ) GOTO Quit; DELETE FROM r2 WHERE r_id IN ( SELECT r_id FROM @r_id ); IF ( @@error > 0 ) GOTO Quit; DELETE FROM r3 WHERE r_id IN ( SELECT r_id FROM @r_id ); IF ( @@error > 0 ) GOTO Quit; DELETE FROM b3 WHERE b_id IN ( SELECT b_id FROM @b_id ); IF ( @@error > 0 ) GOTO Quit; DELETE b4 FROM b4 AS b4 WHERE b4.m_id IN ( SELECT m_id FROM @m_id ) AND (( SELECT COUNT(*) FROM b1 WHERE m_id = b4.m_id ) = 0 ); IF ( @@error > 0 ) GOTO Quit; DELETE b5 FROM b5 AS b5 WHERE b5.m_id IN ( SELECT m_id FROM @m_id ) AND (( SELECT COUNT(*) FROM b1 WHERE m_id = b5.m_id ) = 0 ); IF ( @@error > 0 ) GOTO Quit; COMMIT TRANSACTION; RETURN; Quit: ROLLBACK TRANSACTION; END; |