Do Disabled Indexes Affect Missing Index Recommendations?
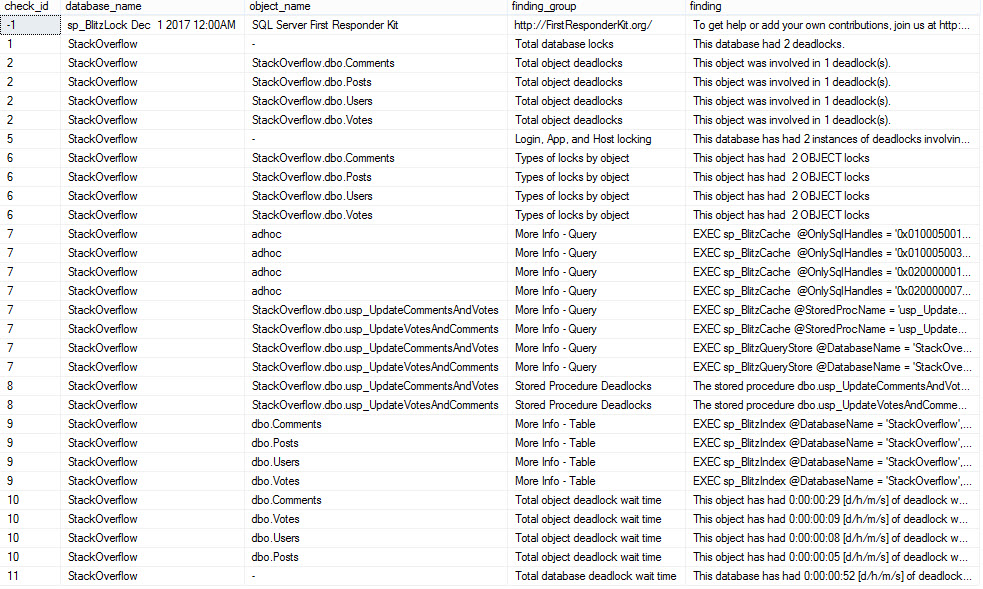
8 Comments
I’m so glad you asked! Let’s take a look. Open up the Stack Overflow database, turn on actual execution plans, and run a query that will cause SQL Server to beg and plead for an index:
|
1 2 3 |
SELECT * FROM dbo.Users WHERE DisplayName = 'Hovercraft Full Of Eels'; |
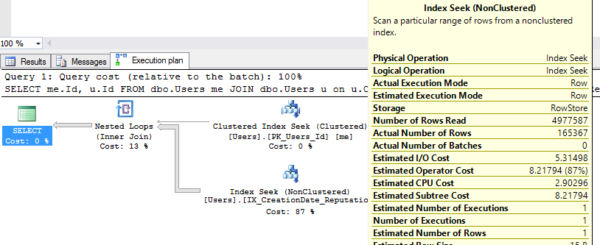
And we get a missing index recommendation in the plan:

Now create the index, and try the query again:
|
1 2 3 4 5 6 7 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Users] ([DisplayName]); GO SELECT * FROM dbo.Users WHERE DisplayName = 'Hovercraft Full Of Eels'; GO |
Oh, don’t act like you haven’t done that. And sure enough, SQL Server uses the index:
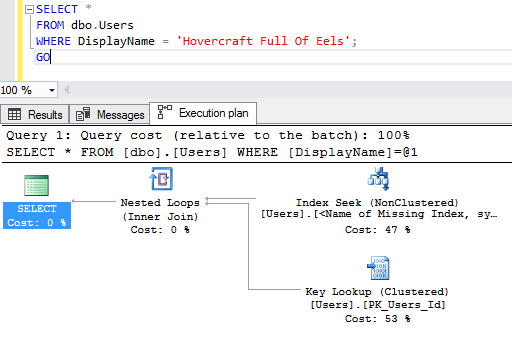
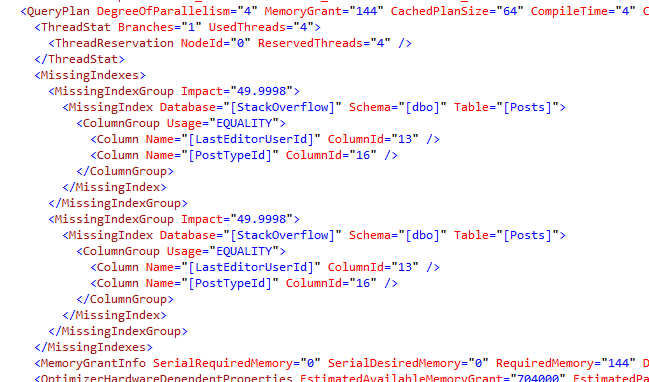
Now disable that index, and run the query again, looking to see if there’s a missing index recommendation in the plan:
|
1 2 3 4 5 6 |
ALTER INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Users] DISABLE; GO SELECT * FROM dbo.Users WHERE DisplayName = 'Hovercraft Full Of Eels'; GO |
And let’s see if SQL Server obeys Betteridge’s law:
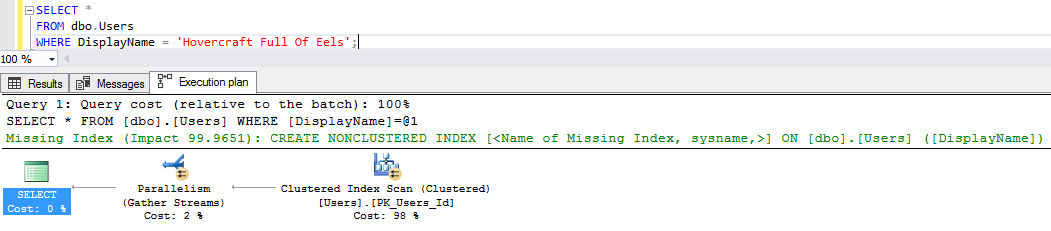
It does! SQL Server asks for the index. Sure, the index exists – it even has the same name – but it’s currently disabled.
The missing index DMVs even keep track, as we can see with sp_BlitzIndex:

Love that. Good work, SQL Server. You can take the afternoon off.