
Using the good ol’ Stack Overflow public database, get the execution plan for this query – either estimated or actual, doesn’t matter:
|
1 2 3 |
SELECT Id FROM dbo.Users WHERE LastAccessDate = '2016/11/10'; |
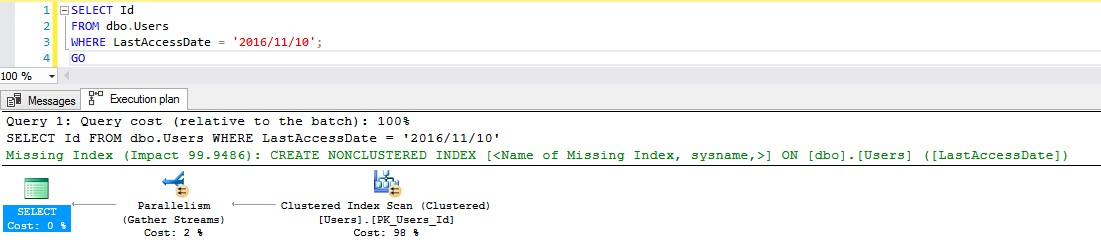
In the execution plan, SQL Server asks for a missing index on the LastAccessDate field:
If you right-click on the plan and click Show Execution Plan XML, you get more technical details:
SQL Server’s telling us that it needs an index to do an equality search on LastAccessDate – because our query says LastAccessDate = ‘2016/11/10’.
But in reality, that’s not how you access datetime fields because it won’t give you everyone who accessed the system on 2016/11/10 – it only gives you 2016/11/10 00:00:00. Instead, you need to see everyone on that day, like this:
|
1 2 3 |
SELECT Id FROM dbo.Users WHERE LastAccessDate >= '2016/11/10' AND LastAccessDate < '2016/11/11'; |
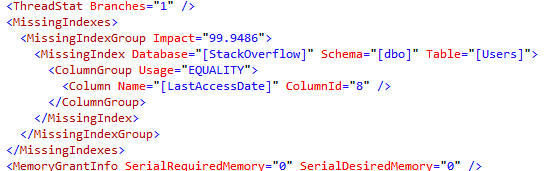
The missing index is just a little bit different already:

Huh. Now SQL Server is recommending that we include the Id field. Technically, Id is the clustering key field on the Users table – so why did SQL Server tell us to include it this time? God only knows, and by God I mean the people on the query optimizer team, because in my eyes, they’re gods.
Let’s see the hand of God by right-clicking on the query, click Show Execution Plan, and:
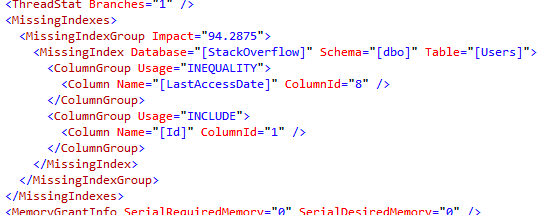
This time around, SQL Server’s saying that we’re doing an INequality search on LastAccessDate. When you look for a range of values, you get an INequality index recommendation.
What happens when we use NULL and NOT NULL?
Are those considered equality searches? Well, I wanted to show you that with LastAccessDate just to keep the demo consistent, but there’s something amusing about the way the LastAccessDate field is created with SODDI: it’s not nullable. As a result, SQL Server is way too smart to ask for an index on that field:
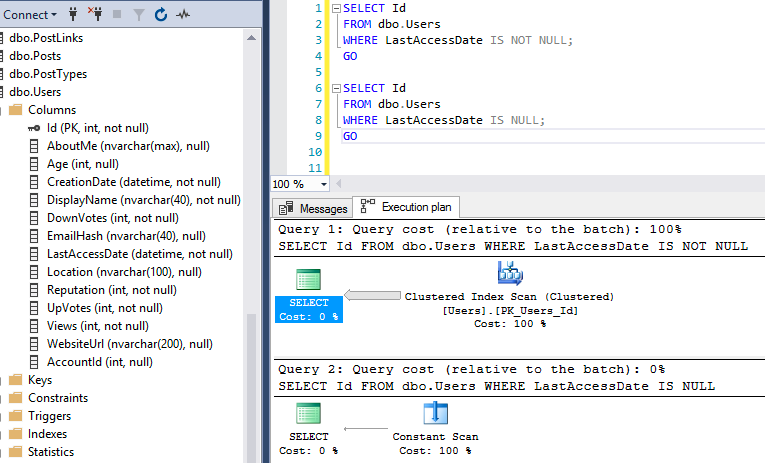
Instead, I’ll use the nullable Location field. In both cases, SQL Server asks for an index on the Location field:
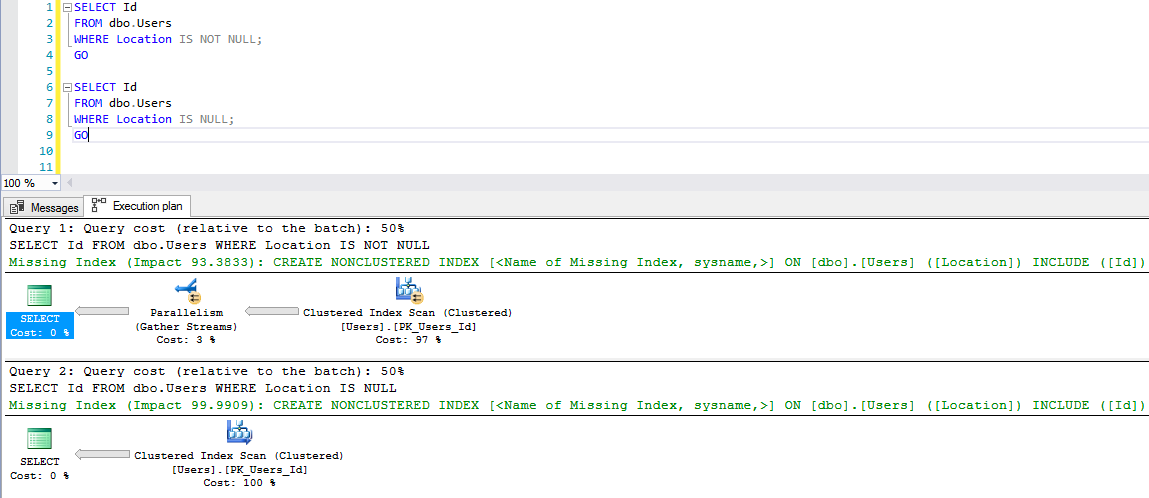
As you might expect, the IS NOT NULL query’s missing index is an INequality one, since we’re not doing an exact value match:
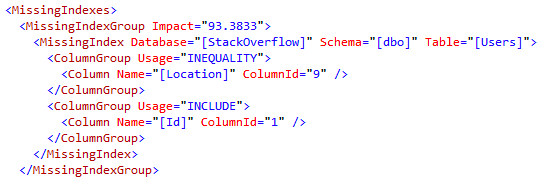
Whereas the IS NULL is considered an equality search, and gets a separate equality index recommendation:

Note that I got two different hints in the XML because my two queries were separated by a GO. When I ran only one batch with both queries in it, and no GO, I got a single missing index with INequality.
What happens when we filter on two fields?
Here’s where understanding the difference between equality and inequality starts to pay off:
|
1 2 3 4 |
SELECT Id FROM dbo.Users WHERE LastAccessDate = '2016/11/10' AND Location IS NOT NULL; |
The LastAccessDate is an EQUALITY search, while Location is an INEQUALITY search:

And when you look at the missing index hint on the query, the equality field is first:

This recommendation makes perfect sense for this query because LastAccessDate is very selective: it’s going to filter our query results down to nearly no rows. Generally speaking, you want the most selective field first in your nonclustered indexes. The IS NOT NULL search on Location isn’t selective at all – it brings back millions of rows – so you want to perform that filtering second.
But what happens in the opposite scenario – when the equality search isn’t all that selective at all?
|
1 2 3 4 |
SELECT Id FROM dbo.Users WHERE Reputation = 1 AND Age BETWEEN 90 AND 99; |
In the query plan’s XML, the missing index hints show that we’re doing an equality search on Reputation, and an inequality search on Age:
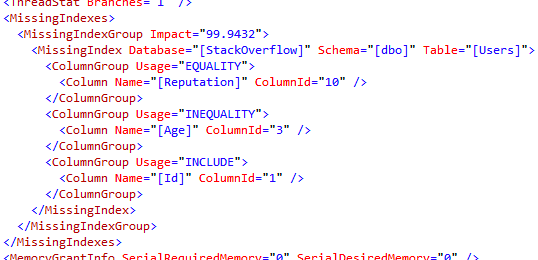
But here comes the curveball: there are millions of users with only one reputation point, but only about 1,000 users with Age between 90 and 99. Age is way more selective in this case. So what does SQL Server Management Studio recommend for our missing index?

The first index recommendation bombshell:
the index fields aren’t in order.
SSMS is following three out of four of Books Online’s guidelines for human beings to interpret missing index DMV data:

It’s up to you, dear reader, to do the fourth bullet: order the fields based on their selectivity. SSMS can’t do that when it’s rendering a query plan, because that would require querying your database. sp_BlitzIndex suffers from this same limitation, too, as does every single tool that uses the missing index DMVs.
I’m not mad at Microsoft, either: they do a great job of laying out the issues on the page Limitations of the Missing Indexes Feature.
In this case, the ramifications are no big deal: if we create SQL Server’s index on Reputation, then Age, it can seek first to Reputation = 1, then seek to Age = 90, and it gets the job done in just a handful of reads. However, in real-world, 3-4-5 key indexes, with a mix of equality and inequality predicates in your query, plus grouping, the difference can be staggering.
When you see a missing index request, don’t think of it as a request to create a specific index. Think of it as SQL Server tapping you on the shoulder, going, “Hey, friend, take a look at your indexes.”

6 Comments. Leave new
Additionally, you should rename the index something other than []
Hmmmm. metacode eliminated. Well, you know what I meant: “Name of Missing Index, sysname”
More clues can then be gotten by also playing around with the tuning advisor to see what it thinks of these indexes, with and without. And then also actually running the queries that you are trying to improve to verify. It’s not easy to make sure the index will be a good thing. You can even record a days worth of load and then verify against that. You may speed up an infrequently run low priority query and slow down some critical process.
The fourth rule says to only order the equality columns. Since Age is an inequality column didn’t SSMS follow all of the rules correctly? Are the rules incorrect?
Joe – they’re not rules, only starting point guidelines. (Insert Matrix joke here.)
And then there is the odd case (which I see fairly often unfortunately) where it recommends an index that already exists. Sometimes a well-meaning DBA has come along and recreated it a couple of times based on the missing index recommendations. The existing index not being used by the query optimizer begs the question, why does it recommend creating it? And does this mean the query optimizer is usurped by some other engine when it comes to the missing index DMV?