Partition Level Locking: Explanations From Outer Space
It’s not that I don’t like partitioning
It’s just that most of my time talking about it is convincing people not to use it.
They always wanna use it for the wrong reasons, and I can sort of understand why.
Microsoft says you can partition for performance.
Partitioning large tables or indexes can have the following manageability and performance benefits.
How?
You may improve query performance, based on the types of queries you frequently run and on your hardware configuration. For example, the query optimizer can process equi-join queries between two or more partitioned tables faster when the partitioning columns in the tables are the same, because the partitions themselves can be joined.
Takeaway: PARTITION EVERYTHING
But…
When SQL Server performs data sorting for I/O operations, it sorts the data first by partition. SQL Server accesses one drive at a time, and this might reduce performance. To improve data sorting performance, stripe the data files of your partitions across more than one disk by setting up a RAID. In this way, although SQL Server still sorts data by partition, it can access all the drives of each partition at the same time.
Takeaway: This was written before anyone had a SAN, I guess?
Ooh ooh but also!
In addition, you can improve performance by enabling lock escalation at the partition level instead of a whole table. This can reduce lock contention on the table.
Takeaway: Except when it causes deadlocks
HoBT-level locks usually increase concurrency, but introduce the potential for deadlocks when transactions that are locking different partitions each want to expand their exclusive locks to the other partitions. In rare instances, TABLE locking granularity might perform better.
Why tho?
Good question! In the Chicago perf class last month, we had a student ask if partition level locks would ever escalate to a table level lock. I wrote up a demo and everything, but we ran out of time before I could go over it.
Not that I’m complaining — partitioning, and especially partition level locking, can be pretty confusing to look at.
If you really wanna learn about it, you should talk to Kendra — after all, this post is where I usually send folks who don’t believe me about the performance stuff.
Demo a la mode
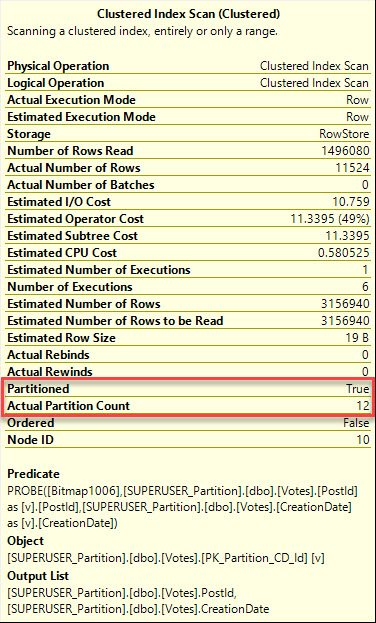
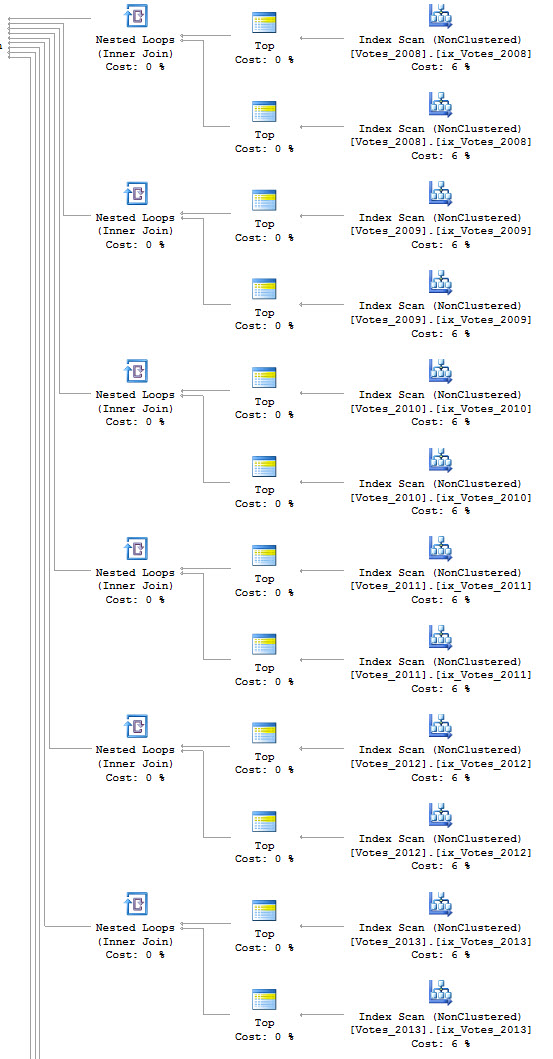
To talk about this, I’ve partitioned the Votes table in the Stack Overflow database by CreationDate.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/*Partitioning*/ CREATE PARTITION FUNCTION VotesCreationDate ( DATE ) AS RANGE RIGHT FOR VALUES ( '20070101', '20080101', '20090101', '20100101', '20110101', '20120101', '20130101', '20140101', '20150101', '20160101', '20170101' ); /*Scheming*/ CREATE PARTITION SCHEME VotesSchemeCreationDate AS PARTITION VotesCreationDate ALL TO ( [PRIMARY] ); /*Indexing*/ ALTER TABLE dbo.Votes ADD CONSTRAINT PK_Partition_CD_Id PRIMARY KEY CLUSTERED ( CreationDate, Id ) ON VotesSchemeCreationDate(CreationDate); |
Now, partition level locking isn’t the default, you have to set it per-table. It’s not the default because of the deadlock scenarios that are talked about in the BOL link up there.
|
1 2 |
/*This isn't the default, you need to set it*/ ALTER TABLE dbo.Votes SET ( LOCK_ESCALATION = AUTO ); |
Query that
Let’s look at how updates work!
I’m going to use sp_WhoIsActive to look at the locks, with the command EXEC dbo.sp_WhoIsActive @get_locks = 1.
This query will hit exactly one year, and one partition, of data.
|
1 2 3 4 5 6 7 8 9 10 |
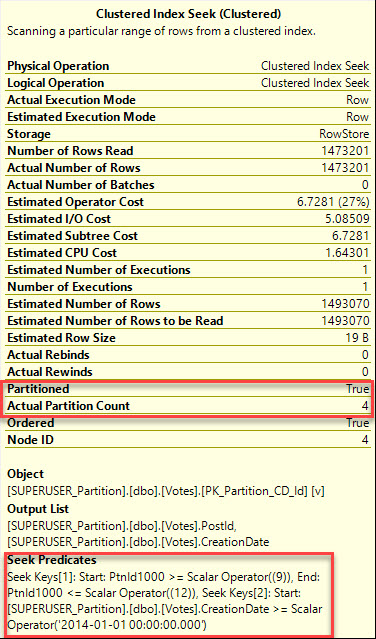
/*What about one clean partition?*/ BEGIN TRAN; UPDATE v SET v.BountyAmount = v.BountyAmount + 100 FROM dbo.Votes AS v WHERE v.CreationDate >= '20090101' AND v.CreationDate < '20100101'; ROLLBACK; |
What do locks look like?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<Database name="SUPERUSER_Partition"> <Locks> <Lock request_mode="S" request_status="GRANT" request_count="1" /> </Locks> <Objects> <Object name="Votes" schema_name="dbo"> <Locks> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="1" /> <Lock resource_type="OBJECT" request_mode="IX" request_status="GRANT" request_count="1" /> </Locks> </Object> </Objects> </Database> |
Confusing part, the first
We have an object lock, and a HOBT lock. Both have been granted, with a single request.
But the Object lock is only IX (intent exclusive), which means that other queries can still dance around it.
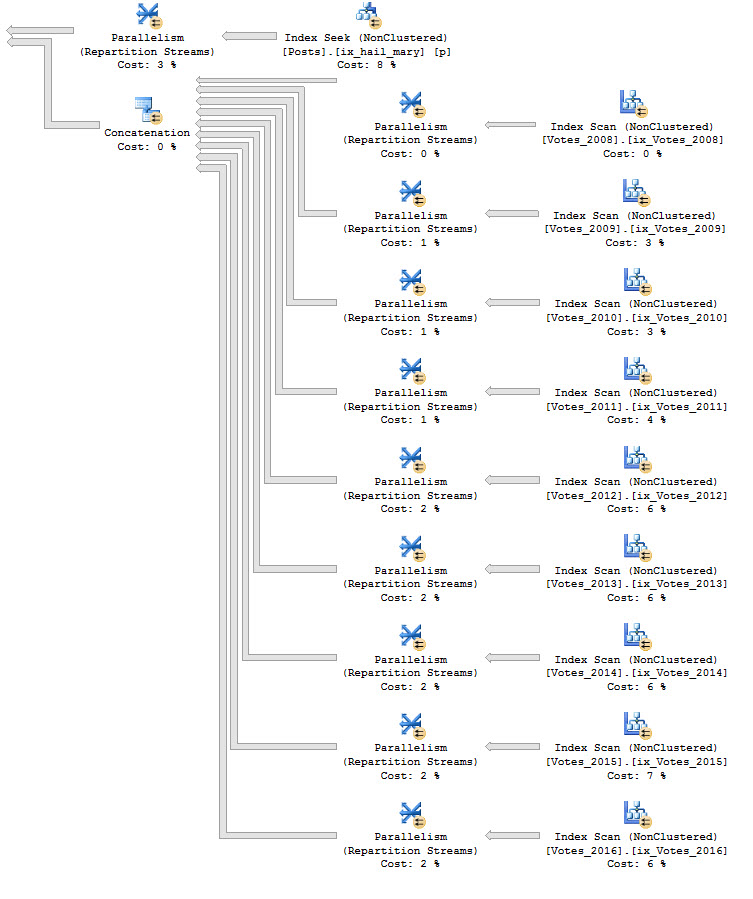
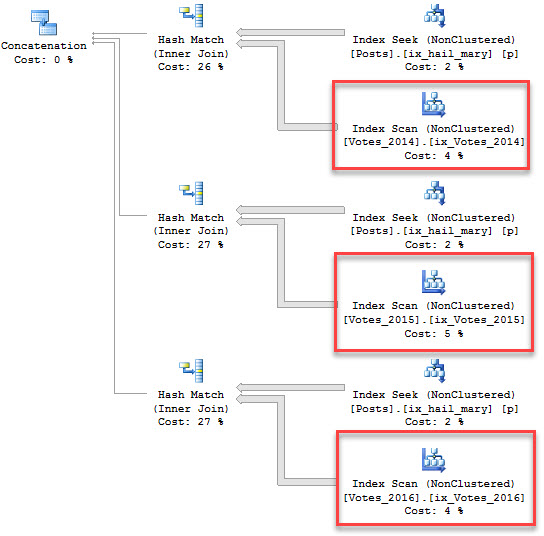
If I run a query that hits a different partition, say for the year 2014, it will finish without being blocked.
|
1 2 3 4 |
SELECT COUNT(v.BountyAmount) AS records FROM dbo.Votes AS v WHERE v.CreationDate >= '20140101' AND v.CreationDate < '20150101'; |
The X lock (exclusive), is just on the one partition for the year 2009. If I run a select query for that partition, it will be blocked.
Patterns
This basic pattern will continue if we cross a partitions, and hit two years of data
|
1 2 3 4 5 6 7 8 9 10 |
/*What if we cross partition boundaries?*/ BEGIN TRAN; UPDATE v SET v.BountyAmount = v.BountyAmount + 100 FROM dbo.Votes AS v WHERE v.CreationDate >= '20090101' AND v.CreationDate < '20110101'; ROLLBACK; |
If we cross lots of partition boundaries
|
1 2 3 4 5 6 7 8 9 10 |
/*What if we cross lots of partition boundaries?*/ BEGIN TRAN; UPDATE v SET v.BountyAmount = v.BountyAmount + 100 FROM dbo.Votes AS v WHERE v.CreationDate >= '20090101' AND v.CreationDate < '20130101'; ROLLBACK; |
Or if we cross all of them
|
1 2 3 4 5 6 7 8 9 10 |
/*What if we cross every partition boundaries?*/ BEGIN TRAN; UPDATE v SET v.BountyAmount = v.BountyAmount + 100 FROM dbo.Votes AS v WHERE v.CreationDate >= '20070101' AND v.CreationDate < '20170101'; ROLLBACK; |
Confusing, part the second
When we cross a single partition boundary, this is what locks look like. I can deal with this. The HOBT X lock has two requests. One for each partition.
This’ll happen for a few more partition crossing queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<Database name="SUPERUSER_Partition"> <Locks> <Lock request_mode="S" request_status="GRANT" request_count="1" /> </Locks> <Objects> <Object name="Votes" schema_name="dbo"> <Locks> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="2" /> <Lock resource_type="OBJECT" request_mode="IX" request_status="GRANT" request_count="1" /> </Locks> </Object> </Objects> </Database> |
Until we hit 2013, and then our locks change. Now we have three requests for X locks on HOBTs, and one IX. Huh. We have a bunch of X locks on pages now, too.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<Database name="SUPERUSER_Partition"> <Locks> <Lock request_mode="S" request_status="GRANT" request_count="1" /> </Locks> <Objects> <Object name="Votes" schema_name="dbo"> <Locks> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="IX" request_status="GRANT" request_count="1" /> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="3" /> <Lock resource_type="OBJECT" request_mode="IX" request_status="GRANT" request_count="1" /> <Lock resource_type="PAGE" page_type="*" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="1997" /> </Locks> </Object> </Objects> </Database> |
When we cross every partition boundary, this is what the locks end up looking like. The HOBT locks went up, we have two kinds of Page locks, and now Key locks as well.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<Database name="SUPERUSER_Partition"> <Locks> <Lock request_mode="S" request_status="GRANT" request_count="1" /> </Locks> <Objects> <Object name="Votes" schema_name="dbo"> <Locks> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="IX" request_status="GRANT" request_count="7" /> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="3" /> <Lock resource_type="KEY" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="3356" /> <Lock resource_type="OBJECT" request_mode="IX" request_status="GRANT" request_count="1" /> <Lock resource_type="PAGE" page_type="*" index_name="PK_Partition_CD_Id" request_mode="IX" request_status="GRANT" request_count="16" /> <Lock resource_type="PAGE" page_type="*" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="10866" /> </Locks> </Object> </Objects> </Database> |
So what’s going on with all that?
Remember that this setting changes lock escalation. Locks don’t always escalate, and SQL Server can choose to lock different partitions with different granularity.
This becomes a little more obvious with a pretty simple query!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT OBJECT_NAME(p.object_id) AS table_name, p.index_id, p.partition_number, SUM(p.rows) AS sum_rows, dtl.resource_type, dtl.request_mode, dtl.request_type, dtl.request_status, COUNT(*) AS records FROM sys.dm_tran_locks AS dtl JOIN sys.partitions AS p ON dtl.resource_associated_entity_id = p.partition_id WHERE dtl.request_session_id = 56 GROUP BY OBJECT_NAME(p.object_id), p.index_id, p.partition_number, dtl.resource_type, dtl.request_mode, dtl.request_type, dtl.request_status ORDER BY p.partition_number; |
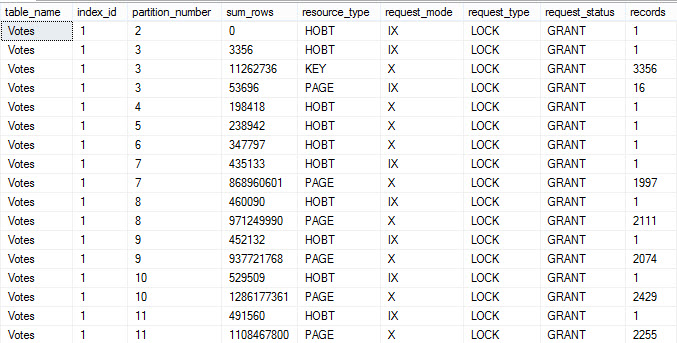
This makes the locking a bit more clear. Some partitions have different kinds of locks, different levels of locks, and different numbers of locks.
I’m not saying there’s a flaw in Who Is Active — sys.partitions is per database, so unless We added a bunch of nasty, looping, dynamic SQL in here, we couldn’t get partition-level information.
I know what you’re thinking
These are all using the partitioning key. What happens if we change our where clause to something that doesn’t? Say, where BountyAmount is NULL, instead. That column isn’t even indexed.
|
1 2 3 4 5 6 7 8 9 |
/*So let's just update the NOT NULL ones*/ BEGIN TRAN; UPDATE v SET v.BountyAmount = v.BountyAmount + 100 FROM dbo.Votes AS v WHERE v.BountyAmount IS NOT NULL; ROLLBACK; |
Heh heh heh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<Database name="SUPERUSER_Partition"> <Locks> <Lock request_mode="S" request_status="GRANT" request_count="1" /> </Locks> <Objects> <Object name="Votes" schema_name="dbo"> <Locks> <Lock resource_type="HOBT" index_name="PK_Partition_CD_Id" request_mode="IX" request_status="GRANT" request_count="12" /> <Lock resource_type="KEY" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="3112" /> <Lock resource_type="OBJECT" request_mode="IX" request_status="GRANT" request_count="1" /> <Lock resource_type="PAGE" page_type="*" index_name="PK_Partition_CD_Id" request_mode="IX" request_status="GRANT" request_count="2014" /> <Lock resource_type="PAGE" page_type="*" index_name="PK_Partition_CD_Id" request_mode="X" request_status="GRANT" request_count="5212" /> </Locks> </Object> </Objects> </Database> |
Our X locks are still only on HOBTs and pages. Our object lock is still only IX!
This is exciting, because even using a non-partitioning key where clause doesn’t lead to an X lock on the object.
We still lock different partitions with different granularity, too. We have a mix of HOBT, Key, and Page locks.
Thanks for reading!






 You’ll go back to the office with free scripts, great ideas, and even a plan to convince the business to upgrade to SQL Server 2016 or 2017 ASAP.
You’ll go back to the office with free scripts, great ideas, and even a plan to convince the business to upgrade to SQL Server 2016 or 2017 ASAP.