The Next Mastering Series is About to Start. Wanna Save $2,000?
Ever wanted to take my Mastering series of classes? I recommend that you take ’em in a specific order because each class builds on the next. If you try to parachute in out of order, you’re gonna have a bad time.
The next rotation is about to start:
- Fundamentals of Index Tuning – Feb 13
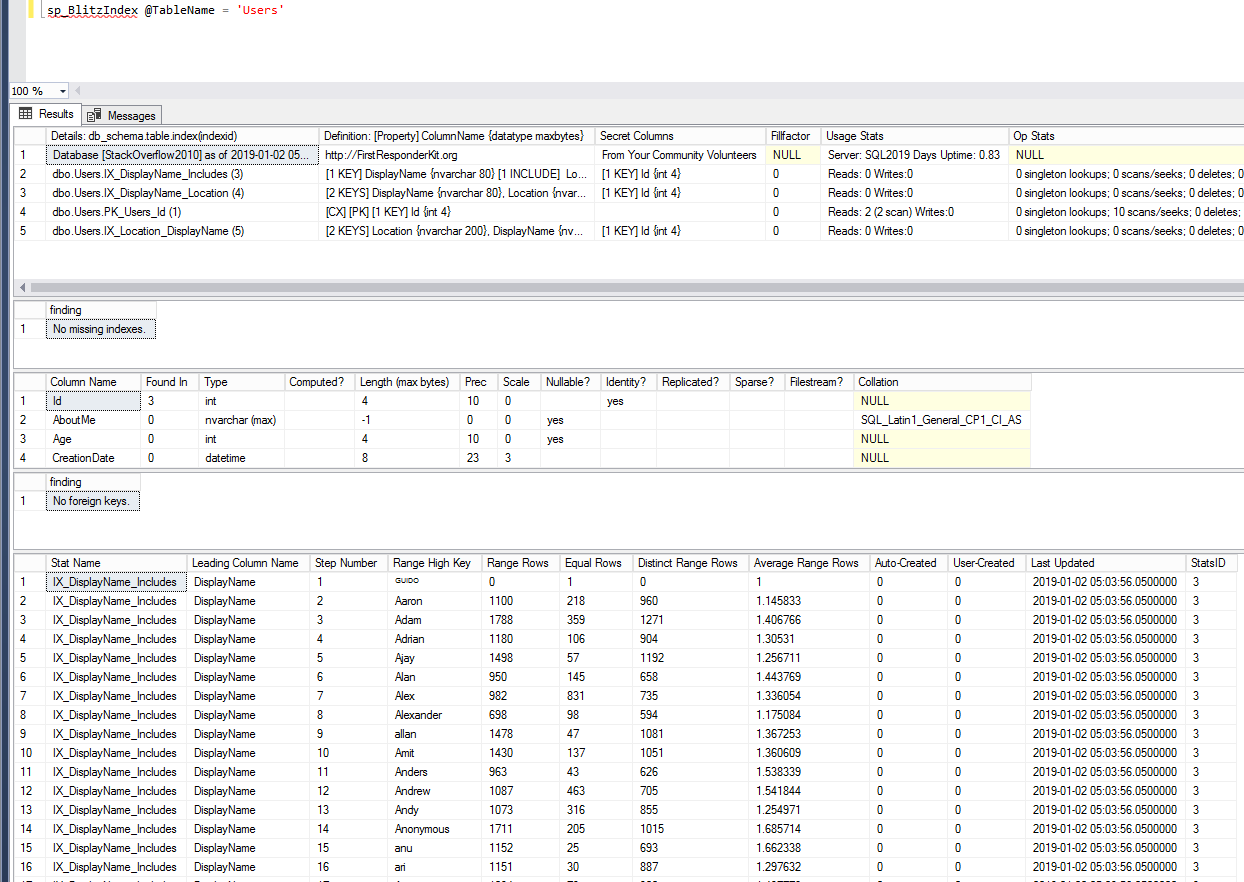
- Mastering Index Tuning – March 4-6
- Mastering Query Tuning – April 1-3
- Mastering Server Tuning – May 1-3
It’s not a cheap investment, I know: the Mastering classes are $2,995 each. That’s why a lot of folks choose the Live Class Season Pass which lets you attend all of ’em for a year straight – so you can re-take classes when work gets in the way, or when you wanna take your game up a notch.
There’s a new less expensive option:
save $2,000 by skipping the lab VMs.
During the Mastering classes, you get your own private lab VM in the cloud to follow along during the labs. You’re tasked with a series of tough assignments, and they help you reinforce the concepts that you’ve been seeing during the lectures. You get a lunchtime lab, and an afternoon/overnight lab as homework.
However, some students don’t use their lab VMs – they have a pesky day job that interferes. During the lunch & afternoon breaks, they work on their day job stuff instead, answering emails and doing help desk tickets.
Since the lab VMs are pretty expensive, I’d rather pass the savings on to you. So starting today, you can pick up a Live Class Season Pass for just $3,995. Enjoy, and see you in class!









 Hey, wanna learn about SQL Server for free?
Hey, wanna learn about SQL Server for free?