The Second Concern for SQL Server Virtualization: Recoverability
Your first concern is licensing, and once you’ve got that under control, it’s time to talk about backups, restores, and uptime.
The business begins by defining the RPO and RTO requirements for high availability, disaster recovery, and “oops” deletions. Use our High Availability Planning Worksheet and fill in the “Current” column on page 1:

You need to give the business a rough idea of the current state – how much data you’ll lose under each of those scenarios, and how long the SQL Server will be down. Be honest – don’t overstate your capabilities, because that just means you’ll get less budget money to build the system the business wants.
Then let the business users fill in the “Biz Goal” column for each scenario. Of course, by default, everyone wants to pick zero data loss and zero downtime, but that’s where page 2 of the worksheet comes in:
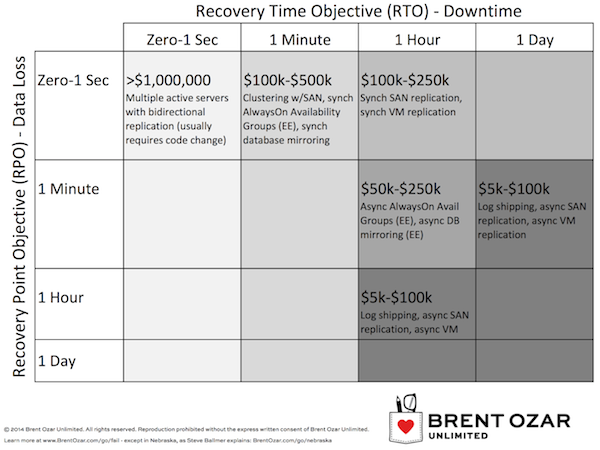
Give both page 1 & 2 of the worksheet to the business users and let them pick the right availability requirements for their budget. Technical managers will want to leap to specific methods (“we have to use VMware replication”) but keep steering the conversation back to the big picture – what does the database need?
The costs aren’t meant to be exact estimates, just rough ballpark numbers of the hardware, software, installation, and ongoing maintenance costs for a couple/few years. To learn more about the technologies in each box, check out our High Availability and Disaster Recovery Resources page.
If your business checks different boxes for each of the three scenarios (HA, DR, and OOPS), then you’ll probably end up with a mix of different SQL Server technologies. For example, the OOPS scenario is usually handled by transaction log backups and a separate standby restore server so that you can pull out just the data you need, but that isn’t going to help you for high availability if you need 1-minute automatic failover with zero data loss.
After the business checks boxes for high availability, disaster recovery, and “oops” deletions, it’s time to pick the right recoverability option. There are virtualization-friendly options in every box, but it’s important to note what isn’t in these boxes.
VMware, Hyper-V, and Xen Alone Aren’t High Availability.
Virtualization admins often think, “If something goes wrong with hardware, the virtual server will just start up on another host.” VMware, Hyper-V, and Xen all do a great job of recovering from these kinds of failures, but those aren’t the only kinds of failures we need to avoid. Note the list of failure types in our High Availability scenario.

Sure, hypervisors protect you fairly well from Windows crashes, RAID controller failures, bad memory chips, or somebody unplugging the wrong box.
But what about patching and OS-drive-full type problems?
I’ve heard admins say, “No problem – before we do any patching, we’ll shut SQL Server down, take a snapshot of the VM, and then start the patch. If anything goes wrong, we’ll just roll back to the snapshot. No data loss, not much downtime.”
Oh, I wish. Let me tell you a story.
One of my clients was preparing a new SQL Server for production. As part of their prep, they needed to apply SQL updates to it, so they started the installation process, and …
A few minutes later the phone calls started pouring in.
Because they were patching the wrong box. They were patching the production SQL Server VM, not the new VM. To make matters worse, they ran into the SSISDB bug, and their production server was down for hours while they figured it out.
How Recoverability Influences Virtualization Design
When you’re designing solutions for HA, DR, and OOPS, read the scenarios described in this simple worksheet. Expect that sooner or later, at a time you can’t predict or control, every one of these is going to happen to you. (Well, maybe not zombies in the data center.) Your technical solution is driven by the business’s requirements for RPO/RTO in each scenario. Understand what virtualization alone can give you, and when you’re going to have to add SQL-Server-level solutions.
Your design then needs to take into account one more challenge: capacity. How many databases will you have, how large will they be, and how fast will the data change? For example, a solution involving log shipping, a 1TB database, a 10% change rate per day due to batch load jobs, and a 1Gb Ethernet pipe probably isn’t going to be a 1-minute-data-loss solution.
It all boils down to one simple question:
can you back up, DBCC, and restore the databases fast enough?
Not only do you have to answer the question for today, but for the life expectancy of the server as well. In my next virtualization post, I explore capacity planning as it relates to RPO/RTO, and then we’ll be able to put the whole picture together of what our VM environment will look like.
Keep Reading with Concern #3: Capacity Planning
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
Brent,
Another outstanding post. Timely for us since we are currently planning a SQL Server virtualization project. We are looking at how to best utilize SQl server consolidation with virtualization. Currently we have a data center with many individual SQL servers (you know the story, each vendor says “Oh no my app must have it’s own server!”).
Keep ’em coming,
Tracy
Tracy – thanks! Glad we can help. The next one will hit next week. Enjoy!
Brent,
regarding the bug with SSISDB, the solution I adopted in my company is first the “separation of concerns”.
I have different servers for the engine, for the ETL (SSISDB and SQL Agent to schedule jobs) and for SSRS: Enterprise edition for the engine (AlwaysOn Availability groups for databases) and standard edition for the ETL server for which I developped a PoSh routine to backup/restore the msdb and the SSISDB (each hour) to a secondary server where the SQL Agent is stopped. When I want to failover, I stop the agent on the primary and start on the secondary (again with PowerShell) and voila…it does the work as expected…
SqlZen – I’m a huuuuuge fan of that approach. I really like separating SSIS onto its own server. There are licensing concerns, but virtualization of course makes that so much better if you license at the host level.
I’m sure this was covered before… but… Can you reduce the RPO from 1 hour to 5 min (or less) by running the logshipping jobs every 5 min (or less)?
(as suggested by this super smart guy? https://www.brentozar.com/archive/2014/02/back-transaction-logs-every-minute-yes-really/)
John – the gotcha is that if you do a big index rebuild, your transaction logs can easily get more than 5 minutes behind. (Same thing with large ETL jobs.)
Good gotcha 😉
Thanks for the quick reply.
A question about the story. Why didn´t they go back to the snapshot instead of troubleshooting for hours?
Pablo – they took the snapshot on the server they INTENDED to patch. Then they accidentally patched a totally different server that hadn’t been snapshotted.
We have heard many times over that physicians operate on wrong knee. I wonder what kind of design solution will stop people doing from that.
You can’t blame that on virtualization, just carelessness. They could have done that to a physical server.
Clay – but what I *can* blame on virtualization is that the admins said, “Virtualization protects us from outages due to patching.” They knew a single physical box wouldn’t, but they thought a single VM would – because they thought they’d snapshot every VM before they patched it. That’s what this post is all about.
I think you are masking the fact that a human error occurred and using that to justify your statement. Virtualization is not magic. It does protect the app or db from hardware failures and other failures on the infrastructure front. Earlier, people had to depend on hardware clustering and pray to God that heartbeats worked and kept everything running. MSCS was the famous solution on MS Windows, but anyone with practical experience will tell you the pains behind it.
The keyword to remember when talking about virtualization is “automation”. Capacity management, resource management and scalability can be automated. But manual activities like patching, software updates, change in code logic, etc. is still something people will do manually mostly and is subject to error. You’re taking the word of some so-called misguided “Admins” to try to prove something that’s not factual.
Kasim – as long as humans are involved, there’s going to be human error.
Personally, I’d like to have protection from that. I understand that protection from human error isn’t important to you, and that’s cool. Virtualization is a great fit for your needs.
Thanks for stopping by!
I love these posts where you talk about your consulting framework.
How low can you realistically get database startup time with synchronous AG/mirroring? Can we use indirect checkpoints with a very low target recovery time (like 1sec)? On high-IOPS storage we could handle the increased load. High-IOPS storage could be SSDs which are cheap per IOPS.
Hi Brent, Thanks for the post. At the place i work, we are moving almost everything to virtualization. I tend to think virtualization is for consolidation, and when we need build high performance database servers, one would want it to be on physical servers. How can one decide what path to choose ? Or when to say, “Nope, we shouldn’t be virtualizing this”. – specifically for DB servers.
It’s a myth that large databases cannot be virtualized. I have virtualized very large SQL and Oracle databases in my career and every single one of them is successfully executed. Almost every single one of them were high performance databases with 100-250k IOPS and sizes anywhere from 4-12 TB (Without compression).
Intel has come a long way on their CPU architecture. A core from 5 years ago has higher bus latency and lower throughput than a core of today. Big difference in the architecture and speed. Same thing for memory. Not to mention, a single virtual machine from major hyper-visors can do 64-128 vCPU and 1-4 TB vRAM “PER VM”. This is, in no way, specs for a small machine. If performance is a concern, it’s no longer a concern. The only time I have seen people not virtualizing large systems is for political reasons, not technical ones.
Kasim – I didn’t say large databases cannot be virtualized. Glad to hear that every one of your projects has been successfully executed though. Have a great week!
Hi Brent,
Was responding to Pradeep’s post. I never said anything about you saying anything 🙂 Thanks for responding though.