
Watch Brent Tune Queries: Fixing Nested Functions
When I do performance tuning for clients, I really pride myself on making as few changes as possible in order to make a tremendous difference. I consider it a failure when I have to tell someone to rewrite a bunch of queries from scratch.
However, there are some cases where I just can’t work around a perfect storm of anti-patterns. To understand why, let’s take an example. I’ve kept the general idea the same, but I’ve rewritten the entire example in the Stack Overflow database to protect the innocent.
The most resource-intensive query was a stored procedure – let’s say it looked for interesting users who live in the same location as you, who you might like to meet, because they’ve commented on the same answers that you have:
|
1 2 3 4 5 6 7 |
CREATE OR ALTER PROC dbo.usp_FindUsersToMeet @UserId INT AS BEGIN SELECT u.DisplayName, u.Location, u.Reputation, u.Id, u.AboutMe FROM dbo.ufn_UsersYouMightLike(@UserId) ul INNER JOIN dbo.Users u ON ul.UserId = u.Id END GO |
Uh oh – it called a table-valued function, ufn_UsersYouMightLike. What’s in there?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE OR ALTER FUNCTION dbo.ufn_UsersYouMightLike (@UserId INT) RETURNS @Users TABLE ( UserID INT ) AS BEGIN /* Build a list of other users in the same city */ DECLARE @OtherUsersInYourLocation TABLE (Id INT); INSERT INTO @OtherUsersInYourLocation(Id) SELECT them.Id FROM dbo.Users me INNER JOIN dbo.Users them ON me.Location = them.Location WHERE me.Id = @UserId; /* Find questions they've commented on, that you've also commented on */ INSERT INTO @Users (UserId) SELECT DISTINCT o.Id FROM @OtherUsersInYourLocation o INNER JOIN dbo.Comments c ON o.Id = c.UserId WHERE dbo.fn_HasCommentedOnAnAnswer(@UserId, c.PostId) = 1; /* You also commented on the same post*/ RETURN END GO |
Uh oh – it’s getting worse. It populates a table variable, and we know those have massive problems. Then, it queries that table variable, and it has a scalar function in the where clause. What’s in that fn_HasCommentedOnAnAnswer?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE OR ALTER FUNCTION dbo.fn_HasCommentedOnAnAnswer(@UserId INT, @PostId INT) RETURNS INT AS BEGIN /* Get the current PostTypeId for an answer */ DECLARE @PostTypeId INT; SET @PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer'); /* Find out if they've left a comment on an answer to this @PostId */ DECLARE @HasCommented int = 0; IF EXISTS (SELECT * FROM dbo.Posts q INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = @PostTypeId INNER JOIN dbo.Comments c ON a.Id = c.PostId WHERE q.Id = @PostId AND c.UserId = @UserId) SET @HasCommented = 1; RETURN @HasCommented; END; GO |
Hoo boy. We’ve got some work to do. We have a few problems to fix:
- A table variable – producing bad row estimates, underestimating costs, and probably stopping us from getting parallelism
- A multi-statement table-valued function – which makes performance tuning way harder for my developers, who couldn’t see what was really happening inside the stored procedure
- A scalar function – which the above function is going to run row by row, and it’s going to inhibit parallelism too
I’m going to unpack all of ’em, and I could probably fix ’em in any order. Let’s start with the scalar.
Fixing the scalar function by inlining it
My general advice on scalars is to take their logic out and try to inline them wherever they’re called. In our case, the calling query looks like this:
|
1 2 3 4 5 |
SELECT DISTINCT o.Id AS UserId FROM OtherUsersInYourLocation o INNER JOIN dbo.Comments c ON o.Id = c.UserId WHERE dbo.fn_HasCommentedOnAnAnswer(@UserId, c.PostId) = 1; /* You also commented on the same post*/ |
So in a perfect world, I’d open up fn_HasCommentedOnAnAnswer, copy the logic out, and paste it directly into the WHERE clause here. Let’s open it up and see if I can do it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE OR ALTER FUNCTION dbo.fn_HasCommentedOnAnAnswer(@UserId INT, @PostId INT) RETURNS INT AS BEGIN /* Get the current PostTypeId for an answer */ DECLARE @PostTypeId INT; SET @PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer'); /* Find out if they've left a comment on an answer to this @PostId */ DECLARE @HasCommented int = 0; IF EXISTS (SELECT * FROM dbo.Posts q INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = @PostTypeId INNER JOIN dbo.Comments c ON a.Id = c.PostId WHERE q.Id = @PostId AND c.UserId = @UserId) SET @HasCommented = 1; RETURN @HasCommented; END; GO |
Drat – they’ve got multiple statements in here. They’re setting a configuration variable, and then using that variable in a subsequent query. The more queries you find in the scalar, the harder the rewrite is going to be.
In this case, I’m going to do a very fast and dirty rewrite. I bet the @PostTypeId is a config variable that doesn’t even change very often, and I could probably hard-code it, but I’m not going to go quite that dirty. Here, I’m just going to dump the config variable into a subquery.
Instead of this:
|
1 2 3 |
INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = @PostTypeId |
I’m going to do this:
|
1 2 3 |
INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer') |
I know – not elegant – but it does get my scalar function down to just one query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE OR ALTER FUNCTION dbo.fn_HasCommentedOnAnAnswer(@UserId INT, @PostId INT) RETURNS INT AS BEGIN /* Find out if they've left a comment on an answer to this @PostId */ DECLARE @HasCommented int = 0; IF EXISTS (SELECT * FROM dbo.Posts q INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer') INNER JOIN dbo.Comments c ON a.Id = c.PostId WHERE q.Id = @PostId AND c.UserId = @UserId) SET @HasCommented = 1; RETURN @HasCommented; END; GO |
Which means that now I can take that one SELECT query, copy it out, and paste it into the query where it was being called, ufn_UsersYouMightLike. Here’s the part of that function that was calling the scalar:
|
1 2 3 4 |
SELECT DISTINCT o.Id FROM @OtherUsersInYourLocation o INNER JOIN dbo.Comments c ON o.Id = c.UserId WHERE dbo.fn_HasCommentedOnAnAnswer(@UserId, c.PostId) = 1; /* You also commented on the same post*/ |
If I copy out the scalar’s logic and embed it into the WHERE clause, it’ll look like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT DISTINCT o.Id FROM @OtherUsersInYourLocation o INNER JOIN dbo.Comments c ON o.Id = c.UserId WHERE EXISTS (SELECT * FROM dbo.Posts q INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer') INNER JOIN dbo.Comments cInner ON a.Id = cInner.PostId WHERE q.Id = c.PostId AND cInner.UserId = @UserId); /* You also commented on the same post*/ |
Ugh. I’m not proud of that, but at least the scalar’s out of the way for now. Next up…
Fixing the multi-statement TVF by inlining it
After inlining the scalar, I’m dealing with an outer function that looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE OR ALTER FUNCTION dbo.ufn_UsersYouMightLike (@UserId INT) RETURNS @Users TABLE ( UserID INT ) AS BEGIN /* Build a list of other users in the same city */ DECLARE @OtherUsersInYourLocation TABLE (Id INT); INSERT INTO @OtherUsersInYourLocation(Id) SELECT them.Id FROM dbo.Users me INNER JOIN dbo.Users them ON me.Location = them.Location WHERE me.Id = @UserId; /* Find questions they've commented on, that you've also commented on */ INSERT INTO @Users (UserId) SELECT DISTINCT o.Id FROM @OtherUsersInYourLocation o INNER JOIN dbo.Comments c ON o.Id = c.UserId WHERE EXISTS (SELECT * FROM dbo.Posts q INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer') INNER JOIN dbo.Comments cInner ON a.Id = cInner.PostId WHERE q.Id = c.PostId AND cInner.UserId = @UserId); /* You also commented on the same post*/ RETURN END GO |
If you’ve been through the functions module in Fundamentals of Query Tuning or in Mastering Query Tuning, you’ll recognize the problem: this function has multiple queries in it, meaning it’s a perilous multi-statement TVF. Its true cost and work won’t show up in the calling query (the proc), so our developers had no idea how bad it really was.
Like with scalars, my general advice here is to try to turn them into inline (single-statement) functions. Again, the more statements you have, the harder this is – but here, it’s not too bad. Let’s just take the statement that was populating the table variable:
|
1 2 3 4 5 |
INSERT INTO @OtherUsersInYourLocation(Id) SELECT them.Id FROM dbo.Users me INNER JOIN dbo.Users them ON me.Location = them.Location WHERE me.Id = @UserId; |
And shove that into the FROM clause, which used to be:
|
1 2 3 4 |
INSERT INTO @Users (UserId) SELECT DISTINCT o.Id FROM @OtherUsersInYourLocation o INNER JOIN dbo.Comments c ON o.Id = c.UserId |
The fast duct-tape way of doing it would be to simply paste it in:
|
1 2 3 4 5 6 7 |
INSERT INTO @Users (UserId) SELECT DISTINCT o.Id FROM (SELECT them.Id FROM dbo.Users me INNER JOIN dbo.Users them ON me.Location = them.Location WHERE me.Id = @UserId) o INNER JOIN dbo.Comments c ON o.Id = c.UserId |
But let’s clean that up a little:
|
1 2 3 4 5 6 |
INSERT INTO @Users (UserId) SELECT DISTINCT them.Id FROM dbo.Users me INNER JOIN dbo.Users them ON me.Location = them.Location INNER JOIN dbo.Comments c ON them.Id = c.UserId WHERE me.Id = @UserId |
Now I can set aside the table variable, and this whole thing turns into one statement, a magical inline table-valued function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE OR ALTER FUNCTION dbo.ufn_UsersYouMightLike (@UserId INT) RETURNS TABLE AS RETURN SELECT DISTINCT them.Id AS UserId FROM dbo.Users me INNER JOIN dbo.Users them ON me.Location = them.Location INNER JOIN dbo.Comments c ON them.Id = c.UserId WHERE me.Id = @UserId AND EXISTS (SELECT * FROM dbo.Posts q INNER JOIN dbo.Posts a ON q.Id = a.ParentId AND a.PostTypeId = (SELECT TOP 1 Id FROM dbo.PostTypes WHERE Type = 'Answer') INNER JOIN dbo.Comments cInner ON a.Id = cInner.PostId WHERE q.Id = c.PostId AND cInner.UserId = @UserId); /* You also commented on the same post*/ GO |
We still have the stored proc calling a function, mind you – but I’m trying to change the bare minimum of things I can to suddenly get the client across the finish line.
So how does it perform?
I really wanted to show you before-and-after numbers, dear reader, but the “before” query was still going after 45 minutes – and I’m only using the small 10GB StackOverflow2010 database here!

The improved version runs in under a second! Granted, the execution plan isn’t pretty:
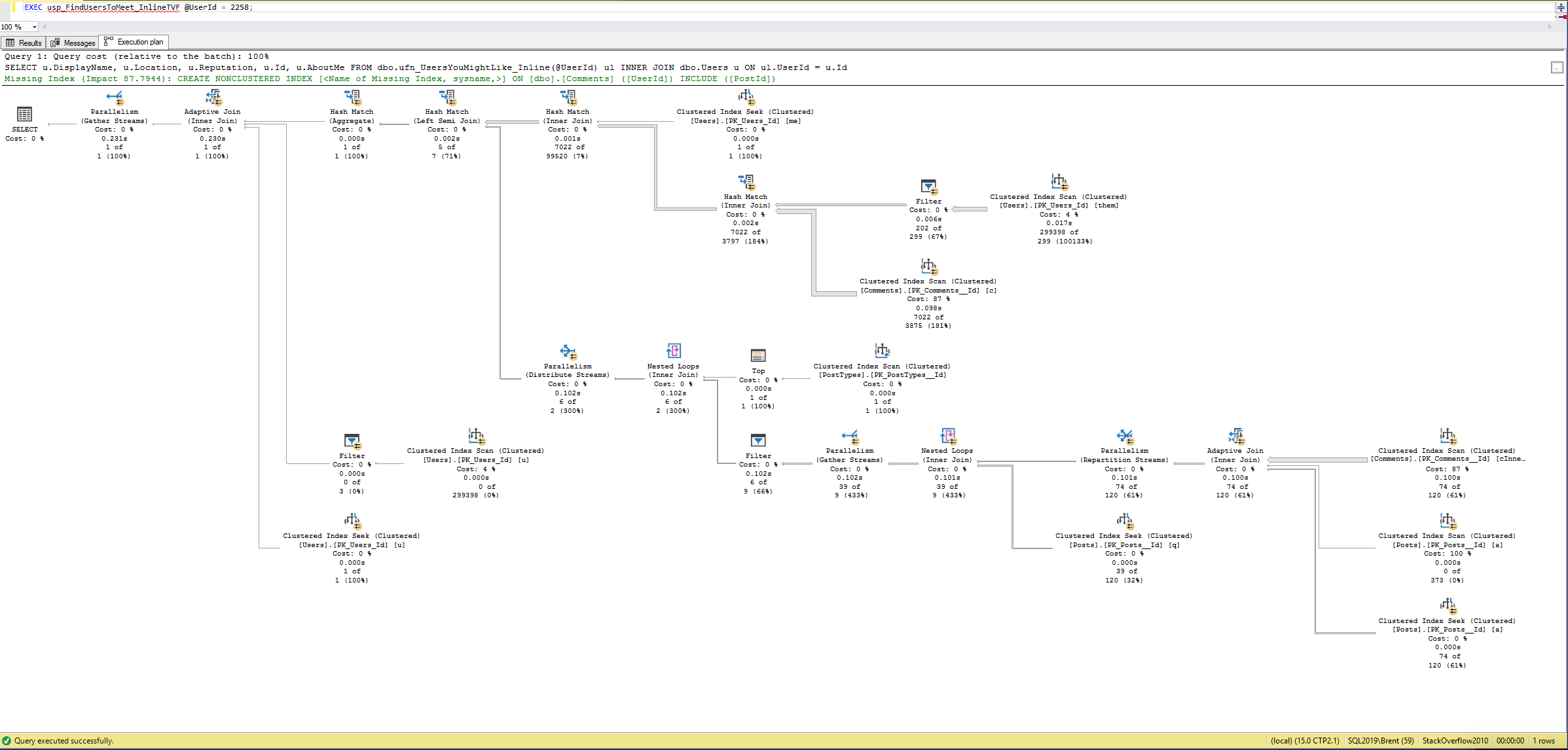
And there are obvious improvements we could make to the code and indexes, but…who cares? IT RUNS IN UNDER A SECOND! Rather than chasing further improvements to that one, I’d hand that to my developers, walk them through the changes we made, and then talk about the next terribly long query to go tune. In most cases, the big bang for the buck will be taking those 45-minute-long queries and turning them into just 1 second, rather than turning 1 second queries into 200ms queries.
Recap and lessons learned
When I show this to a developer, there are usually hugs and sobbing involved. They believed – rightfully – that if a feature ships in SQL Server, then it should perform well. That just isn’t the reality, sadly: table variables, scalar UDFs, multi-statement TVFs – these are all things that the documentation don’t warn you about. Sure, they compile – but they sure don’t scale.
These two function examples were simple on purpose because this is a blog post, not a doctoral thesis. When you get into functions that have several statements, each building on the next, building tables and fetching configuration data, this just gets more laborious. It’s not mentally hard, mind you, it’s just hard work, rolling up your sleeves to combine queries into one big ugly monster – or rewriting it from row-by-row functions to a set-based approach inside a stored procedure.
The earlier a senior database developer can get involved in the design and code review process, the less work gets wasted by other developers who don’t know that SQL Server just can’t handle those, nor implicit conversions, dynamic WHERE clauses with OR/ISNULL/COALESCE, etc, things that compile – but don’t scale.
To learn more about why – and how to work around ’em – check out my free Watch Brent Tune Queries videos, and then graduate to the Fundamentals of Query Tuning course.

15 Comments. Leave new
> But let’s clean that up a little:
How do you assert that such “cleanups” produce the same results as the original monster?
That would be valuable discussion — unit testing t-sql to confirm refactoring did non break it. Unfortunately I don’t have much to add here. . .
Absolutely, that’s suuuch a great question. That’s why I end it with:
> I’d hand that to my developers, walk them through the changes we made
The re-architecting, re-factoring, re-writing type work usually requires a senior database developer for the first pass, but then going through the different input parameters and validating results, that can be tasked down to a less senior developer.
Great information.
Thanks!
[…] Brent Ozar takes us through a realistic but nasty scenario: […]
Great stuff. Have no idea why Red Gate has this on in Prompt “Consider using table variable instead of temporary table” (https://documentation.red-gate.com/codeanalysis/style-rules/st011)
Mike – great question, but you should definitely ask them, not me. 😉
Following that link, Red Gate answers your question themselves on https://www.red-gate.com/hub/product-learning/sql-prompt/choosing-table-variables-temporary-tables .
Great post, Brent. I’m curious if you tried the same query against SQL Server 2019. What kind of performance difference does table variable deferred compilation and scalar UDF inlining make? It seems like these features were made for this type of query.
Bryan – check the screenshots carefully. 😉
Whoopsie – missed that. That’s both surprising and disappointing. I guess that DBAs will have a job for at least one more version. ?
It would appear, then, that you found a case where these new features either aren’t used during query optimization and execution or they just simply don’t play well together.
Yeah, it’s a little more complex than that – not every function will get inlined, and it’ll depend on your database’s compatibility level and settings, too. Read more here: https://sqlperformance.com/2019/01/sql-performance/scalar-udf-sql-server-2019
45 min vs 1 second…, it means that in the real world scalar and multistatement table valued function must not be used, so the question is: why mssql has these feature if they are so much hazardous?
Why can you buy guns?
To understand how dangerous they are… But if the purpose of the scalar and multistatement table valued function is that, mmmh It was not a great idea… Why use them? To have to rewrite the code when the data grows? Or hope that our db is not used and therefore remains, this is not a great idea, either.