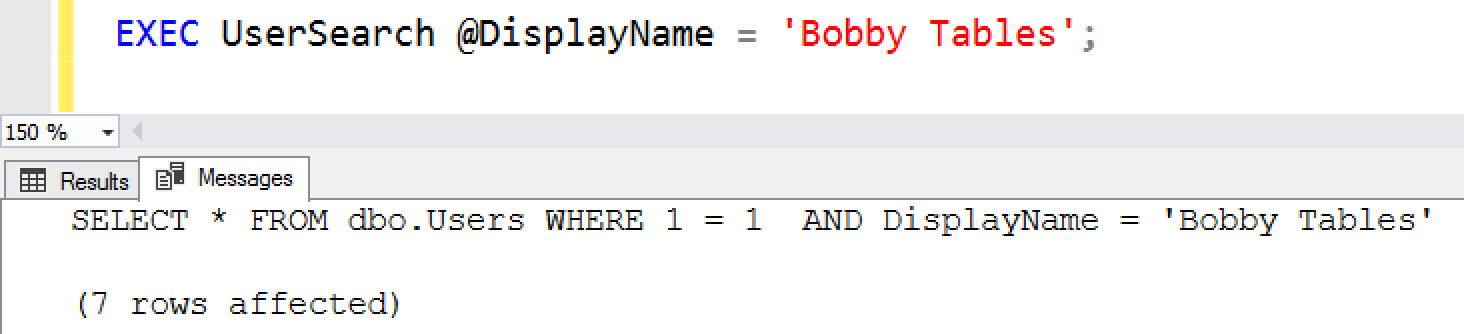Comparison Review: Microsoft SSDT vs Redgate SQL Source Control
19 Comments
Hi. I’m still not Brent.
My name’s Alex, and I care about databases, DevOps and data protection. Last year I delivered a session on GroupBy all about how to do Database DevOps right, and back in May I wrote a blog post for BOU about how to screw it up.
Now, dear reader, I’m going to review and compare the two most popular tools to help you put it all together: Microsoft SSDT/Visual Studio Database Projects and Redgate SQL Source Control. I hope this post will help you to decide which is more likely to suit you and your team.
But first…
Why SSDT or SQL Source Control and not something else?
Good question.
Firstly, there are two styles of database source control and deployment: Model (aka “state”) and Migrations. I’ve written about the relative pros and cons here but the tl;dr is that neither are perfect, both hold value, and generally you do need to pick one or the other.
To avoid getting tangled up in higher level debates about whether to adopt a migrations-based or a model-based source control solution – or even a hybrid, this blog post is specifically scoped to model-based source control solutions.
So what about alternative model-based solutions?
I believe it’s important to use widely used and supported tools wherever possible. SSDT and SQL Source Control are the two most widely used tools in Europe and North America for model-based source control and deployment of SQL Server databases. Other model-based tools certainly exist (see ApexSQL source control, DBmaestro and dbForge Source Control for example) but none are anywhere near as widely used or trusted for SQL Server databases as either SSDT or Redgate SQL Source Control.
So let’s get stuck in.
Ease of use
Implementing database source control or continuous integration is a big change for your team and it will be hard on your developers and you will move more slowly to begin with. Choosing a tool that is easy to adopt will make your life much easier and lead to a far greater chance of success.
Redgate SQL Source Control plugs right into SQL Server Management Studio (SSMS), whereas SSDT lives in Visual Studio (VS).
This is enormous. If your developers and DBAs prefer to work in SSMS, SQL Source Control may feel very natural to them, but Visual Studio is full of new concepts: Solutions files? Project files? MSBuild? The list goes on. This makes the learning curve much more difficult for people who are used to working in SSMS.
It’s not entirely one-sided however. The SSDT table designer is amazing, combining the SSMS table designer and a query window and allowing you to use whichever you prefer.

On balance, SQL Source Control is much easier and more natural tool for most database folks.
Winner: Redgate
Refactoring
When deployments scripts are generated by schema comparison tools, which do not look at or understand your data, there are some scenarios which can cause the software problems. For example:
- Renaming a column or table
- Splitting a table
- Adding a new NOT NULL column
Both SSDT and Redgate SQL Source Control have features to help you in these scenarios, but the SSDT features are better.
Redgate’s “migration scripts” feature is hard to understand and has a tendency to break in nasty ways and cripple your performance. In contrast SSDT gives you both pre- and post-deploy scripts and the refactor log. SSDT pre- and post-deploy scripts are a pain to maintain, but ultimately, they work more reliably.
In fairness, Redgate have recently released their own pre- and post-deploy script feature, so they aren’t far behind – but the Redgate scripts do not support SQLCMD variable syntax like the SSDT version does and they do not have anything like the refactor log.
Winner: SSDT
Filters
Perhaps you aren’t interested in versioning objects prefixed with “test_”. Or perhaps you want to filter out some other objects that are supposed to exist in your dev environment, but not production, such as the tSQLt unit testing framework?
This is a big win for Redgate – SQL Source Control filters are, frankly, awesome. Whether you want to filter out something small (like the IsSqlCloneDatabase extended property added by SQL Clone) or whether you want to set up your own naming conventions, these things work a treat. You can even use them to do quite complicated stuff to manage multiple databases with several known variations, but I’d generally discourage going down that road if you can.
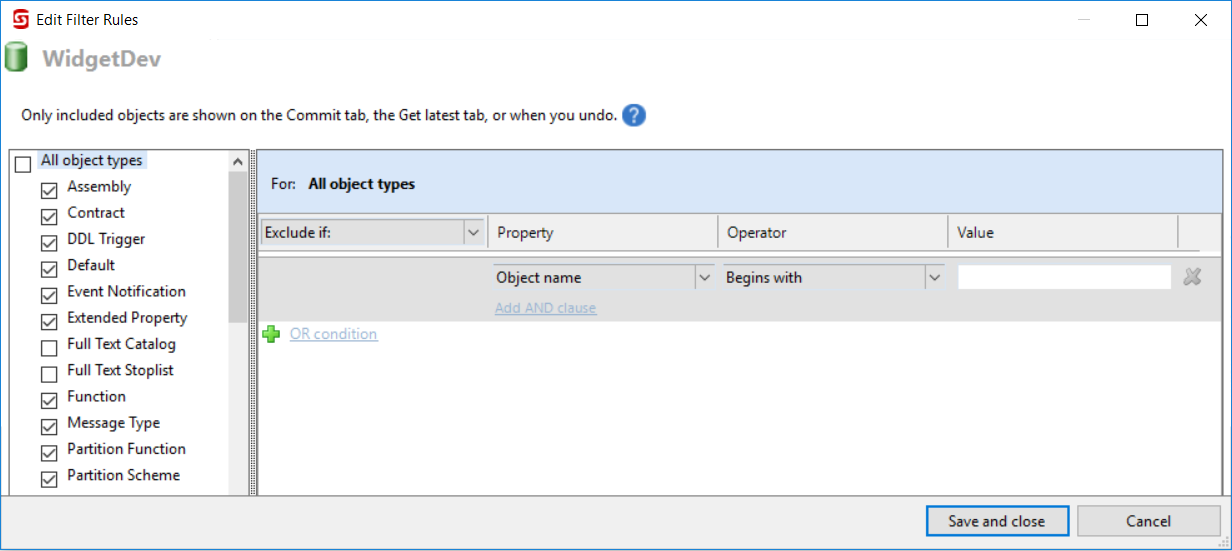
In contrast, while SSDT does include some filtering functionality in Visual Studio’s schema compare tool, it’s not as easy to source control your filters and to use them when publishing DACPACs to production environments. What you can do you need to do with PowerShell and the Schema Compare API, as Gavin Campbell clearly explains here. I’d also like to put in an honorary shout out to Ed Elliot’s filtering deployment contributor which makes the process a little easier, as long as your database folks are comfortable playing with C#, APIs and DLLs etc.
Another option SSDT provides, which is lacking in Redgate SQL Source Control, is to create partial projects with database references. To demonstrate how this works, read Ken Ross’ post on adding tSQLt to an SSDT project. While I prefer the way Redgate handles tSQLt for you, others like the way the SSDT database reference approach separates the tests from the rest of your code.
To summarise: The Redgate approach to filtering is generally easier to manage, especially if your team includes folks who aren’t .NET developers.
Winner: Redgate
Static data
Redgate SQL Source Control makes adding static data to source control super easy – just right-click and select the tables you want and voila.
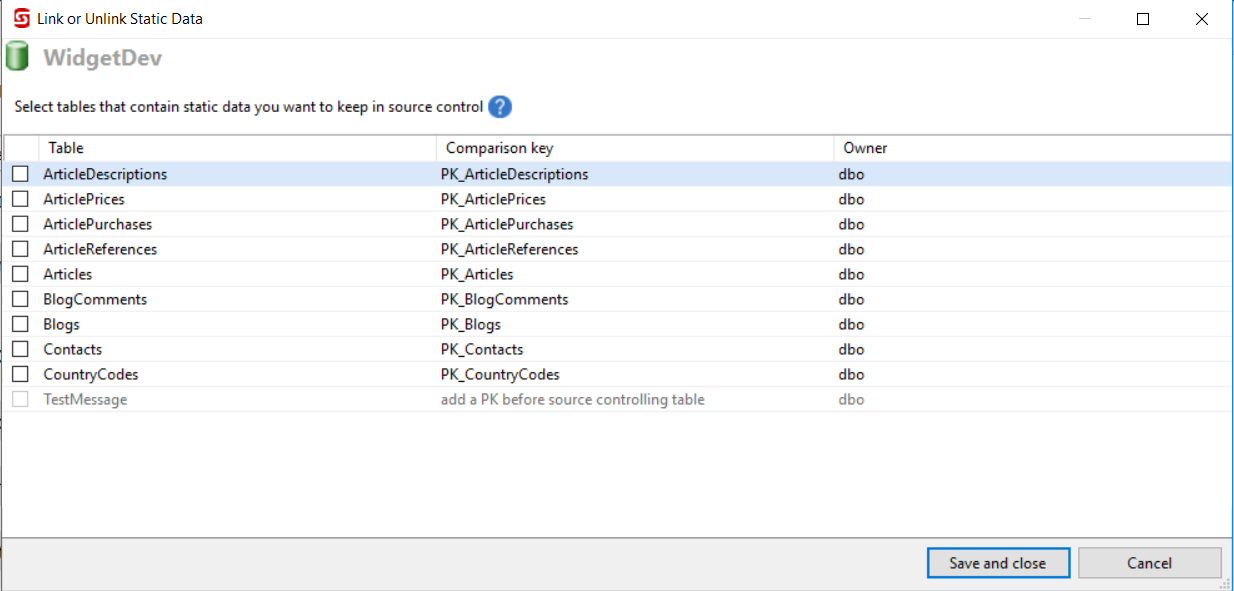
However, there are a few issues with it.
- All static data tables require a primary key (although, to be fair, they should have one anyway!)
- The scripts generated are not easily ‘diff-able’ because changes to the data do not appear in-line.
- Column level or row level versioning, (e.g. to support seed data), is not supported. It’s all or nothing.
- Adding lots of static data can have a negative impact on performance.
In SSDT static data is handled using post deploy scripts and MERGE statements. Your post deploy scripts can be a pain to manage and the MERGE scripts can be annoying to write by hand, but these pains can be minimised by separating out the data scripts into multiple scripts/stored procedures that are simply executed by a single coordinating post deploy script, and by using sp_generate_merge to create your merge scripts.
If you can get over the pain, SSDT allows you to create data scripts that are “diff-able” and with far greater flexibility, for example to support seed data.
All that being said, since you can now add a post-deploy script in Redgate SQL Source Control, this means Redgate can support both options.
Winner: Redgate
Money
Redgate costs money. SSDT is free with Visual Studio.
You can buy SQL Source Control as a standalone product, but you also want the automated deployment bits and that increases the cost because each team member will need a licence for the full SQL Toolbelt.
At the end of the day, free is always going to be more attractive than not free, so if this was the only issue, clearly we would all use SSDT. The decision you need to make is whether the benefits listed above are worth the additional expense.
Winner: SSDT
More detail
There is a lot more to say so this post risks getting very long. The first draft was over four times longer than this version! Hence, I’ve created a much more detailed whitepaper to partner this blog post. You can download it from the DLM Consultants website: www.dlmconsultants.com/redgate-vs-ssdt
The full whitepaper covers all the issues listed above in much more detail, as well as also discussing:
- Shared development databases
- Security
- Deployment
- Support
- Complex projects
The full whitepaper has been peer-reviewed by Brent Ozar, a long list of SSDT and Redgate power users, as well as representatives from both Redgate and the Microsoft MVP program. I hope you find it useful.
Summary
To re-cap, here are our winners for each category:
- Ease of use: Redgate
- Refactoring: SSDT
- Filters: Redgate
- Static data: Redgate
- Money: SSDT
So which is better? Which would I recommend? Well, like most things, it depends. If there was a simple answer you probably wouldn’t be asking the question.
If you have read all the above and anything has jumped out at you as being particularly important to you and your team, great. Otherwise, if you are still undecided, the proof of the pudding will be in the eating. SSDT comes free with Visual Studio and Redgate offer a free trial – so download both and give them a try.
When I went to visit Farm Credit Mid-America, we set up three parallel proof of concepts (PoCs) and our cross-functional team voted (unanimously) for their favourite. As a result, implementation was much easier for them:

Whichever you choose, both products are an excellent investment of your time and/or money.
Good luck!
Want to learn more?
I hope this post has helped you to figure out whether SSDT/Visual Studio Database Projects or Redgate SQL Source Control are likely to be a better fit for you and your organisation.
If you would like my support to build your own proof of concept, get in touch through the website.