Index Tuning Week: How Many Indexes Are Too Many?
34 Comments
This week I’m running a series of posts introducing the fundamentals of index tuning. First up, let’s talk about understanding how many indexes make sense on a table.
The more nonclustered indexes you have on a table,
the slower your inserts and deletes will go.
It’s that simple.
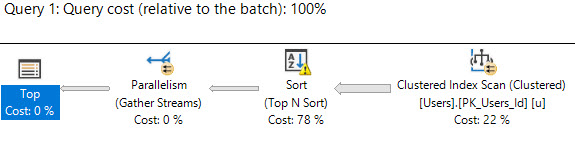
If you have a table with 10 nonclustered indexes, that’s 10x (or more) writes an insert has to do for all of the data pages involved with each index. (The data page writes happen later, asynchronously, during a checkpoint, but that’s still more work for storage, and there’s still synchronous blocking involved.)
I’ve seen so many DBAs that scream bloody murder about 15-second IO warnings on their storage, and then when we go to look at their tables, they have dozens of indexes on every table. We remove the unneeded indexes, and presto, suddenly their storage workload drops. Their storage does less work, which means it can react to other requests faster, and suddenly they have a cascading performance improvement throughout their queries.
People weren’t complaining about the speed of inserts and deletes – but those background operations were killing storage with a thousand small cuts.
To help performance tuners, I came up with Brent’s 5 and 5 Rule: aim for around 5 indexes per table, with around 5 columns (or less) on each.
This is not set in stone. It’s simply based on the fact that I have 5 fingers on one hand, and 5 fingers on my other hand, so it’s really easy to remember.

5 and 5 is just a starting point for discussion.
Sometimes, 5 indexes aren’t enough. Sometimes your users want to filter or sort by lots of different fields on a really wide table. However, the more indexes you add, the slower your inserts and deletes will go, and the more competition pages will have for precious memory space. You may have to throw hardware at it in the form of more memory and faster storage.
Sometimes, even just 5 indexes are too many. When you have a table where insert and delete speeds are absolutely critical, and select speeds don’t matter, then you can increase performance by cutting down on your indexes.
Sometimes, 5 columns are too many. If you’re indexing big VARCHAR(MAX) columns, or you’re index hot columns (columns that constantly change), you can still run into problems. And yes, included columns count against your total – if that surprises you, watch my free How to Think Like the Engine class to learn how pages are built.
Sometimes, 5 columns aren’t enough. Maybe you’ve got a query that has 3 fields in the filter, the combination of which is extremely selective, and they just need to return 4 fields in the SELECT. That’d be 7 fields. That’s completely okay – remember, Brent’s 5 and 5 Rule just stems from the fact that I have 5 fingers on my left hand, and 5 fingers on my right hand. If I’d have had an accident in shop class, we might be talking about Brent’s 4 and 5 Rule, and laughing about my lack of skill with the table saw.
Wanna learn how to pick which indexes you should build, and what columns should go in ’em? That’s where my Mastering Index Tuning Class comes in.