How to Check for Non-Existence of Rows
8 Comments
You’re writing a query, and you wanna check to see if rows exist in a table.
I’m using the free Stack Overflow database, and I wanna find all of the users who have not left a comment. The tables involved are:
- In dbo.Users, the Id field uniquely identifies a user.
- In dbo.Comments, there’s a UserId field that links to who left the comment.
A quick way to write it is:
|
1 2 3 |
SELECT u.* FROM dbo.Users u WHERE NOT EXISTS (SELECT * FROM dbo.Comments c WHERE c.UserId = u.Id); |
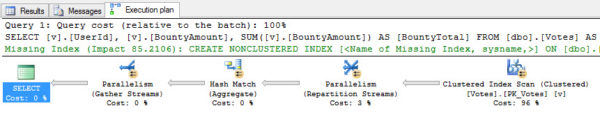
And this works fine. When you read the query, you might think SQL Server would run that SELECT * FROM dbo.Comments query for every single row of the Users table – but it’s way smarter than that, bucko. It scans the Comments index first because it’s much larger, and then joins that to the Users table. Here’s the plan:

But another way to write that same query is:
|
1 2 3 4 |
SELECT u.* FROM dbo.Users u LEFT OUTER JOIN dbo.Comments c ON c.UserId = u.Id WHERE c.Id IS NULL; |
This can be a little tricky to wrap your head around the first time you see it – I’m joining to the Comments table, but it’s an optional (left outer) join, and I’m only pulling back rows where the Comments primary key (Id) is null. That means, only give me Users rows with no matching Comments rows.
This join plan is completely different: there’s no stream aggregate, and now there’s a filter (c.Id IS NULL) that occurs after the merge join:

It’s completely different:
- The Users table is processed first
- There’s a different kind of merge join (left outer)
- There’s a filter after the join
To see which one performs better, let’s use the metrics I explain in Watch Brent Tune Queries: logical reads, CPU time, and duration. In the 10GB StackOverflow2010 database, both queries do identical logical reads and duration, but the join technique uses around 20-30% more CPU time on my VM.
But don’t draw a conclusion from just one query.
I tell my developers, write your queries in whatever way feels the most intuitively readable to you and your coworkers. If you can understand what’s going on easily, then the engine is likely to, as well. Later, if there’s a performance problem, we can go back and try to nitpick our way through different tuning options. The slight pros and cons to the different approaches are less useful when you’re writing new queries from scratch, and more useful when you’re tuning queries to wring every last bit of speed out of ’em.