Announcing “Great Post, Erik” – A Book of Erik’s Best Work
13 Comments
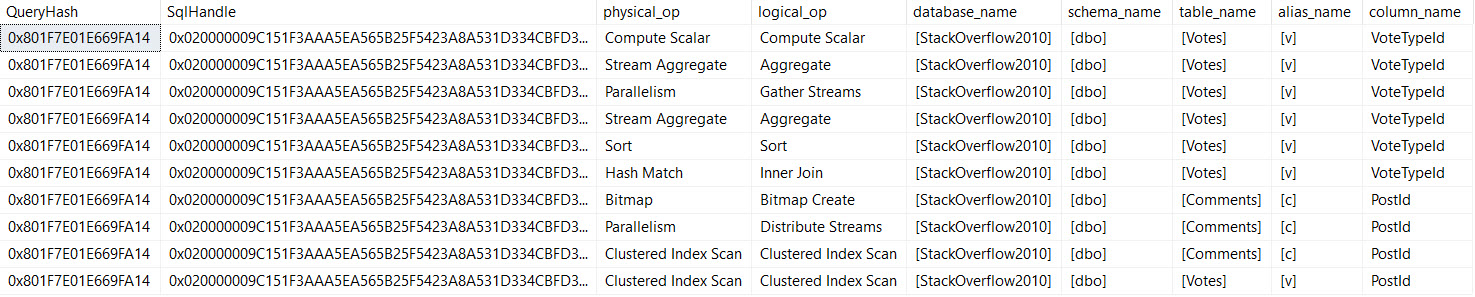
Erik Darling blogs a lot.
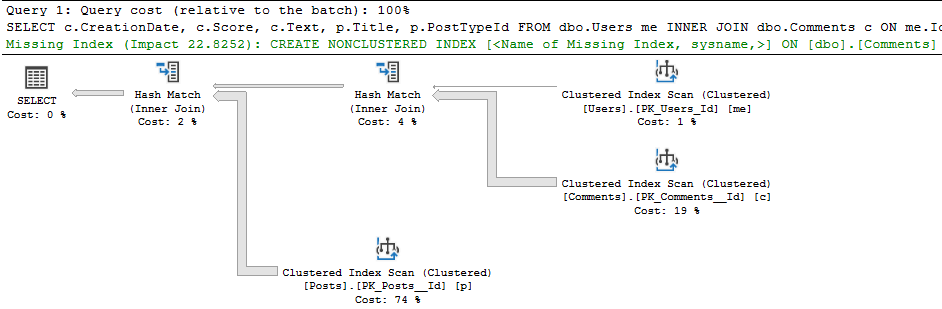
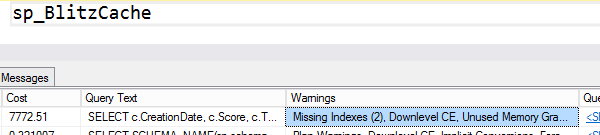
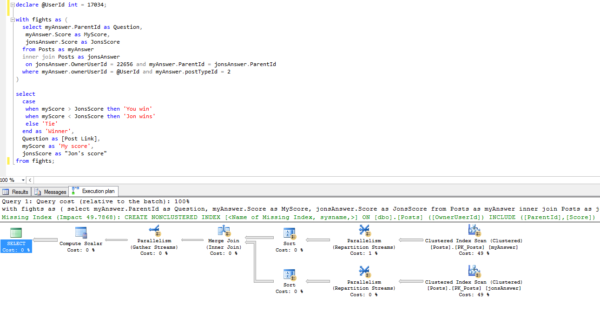
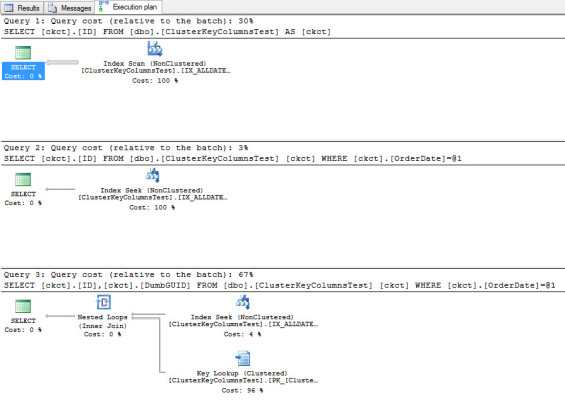
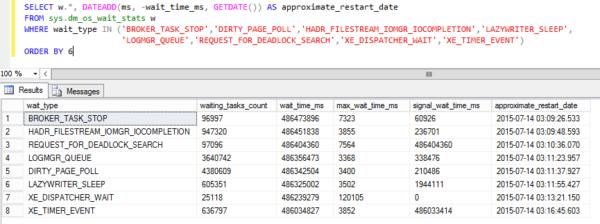
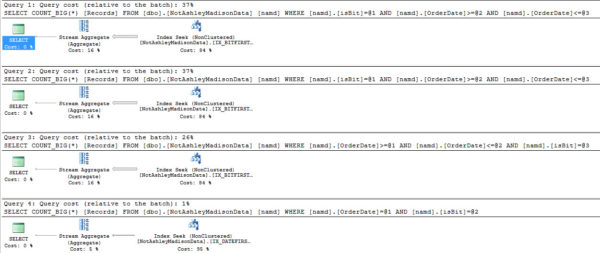
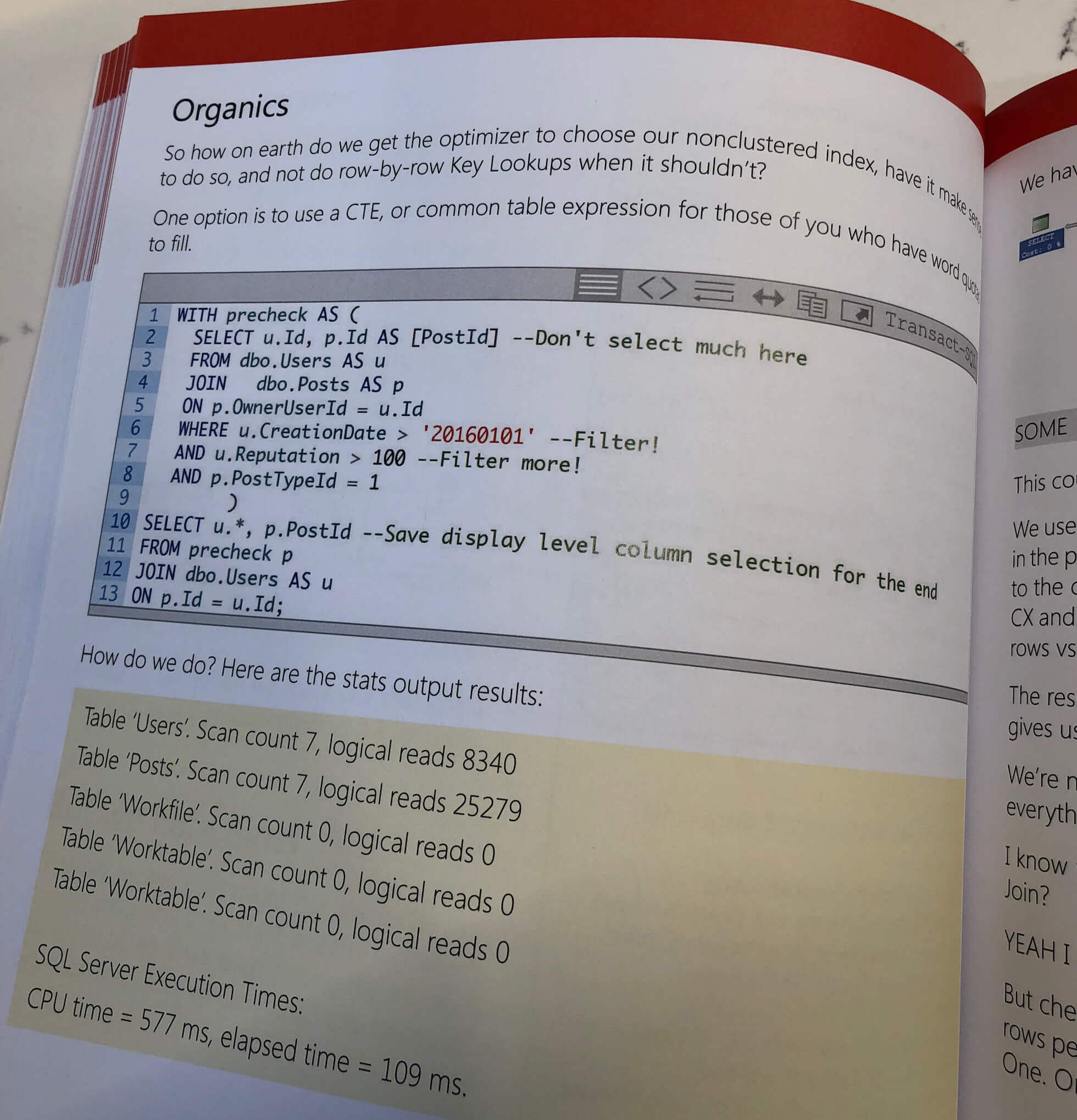
Not lightweight stuff, either, but ambitious posts with a lot of demo scripts, screenshots, and detailed explanations about why SQL Server does what it does.
 So as he approached his 300th blog post, we decided to build a best-of book with his favorites.
So as he approached his 300th blog post, we decided to build a best-of book with his favorites.
There’s no new content here: if you’ve read all of Erik’s posts, then you already know what’s in the book. But if you’re like me, dear reader, you can’t absorb Erik’s work right away, and you want a way to revisit it when you’re on a train or waiting for your friend to arrive at the bar. In that case, you’ll love this book – it’s 62 of his blog posts formatted for easier reading. The electronic forms of the book preserve the hyperlinks, too.
Each post includes a link back to the blog so you can ask questions about what you’re reading. I’m kinda excited by this because it lets you have an ongoing dialog with the author, getting clarification about what you just read.
Or, you know, tell him, “Great post, Erik.”
The title stems from a running joke here at the blog: when a good post goes out, people comment, “Great post, Brent” regardless of whoever wrote the post. I wish I was half smart enough to write some of these.
Shout-out to Eric Larsen for his awesome cover illustration and to Pankaj Runthala at Manuscript2ebook for heroically converting hundreds of pages of WordPress output to print-friendly form.


You can buy “Great Post, Erik” in Kindle or paperback, click on the book’s picture to see a preview inside it, and if you’re a KindleUnlimited subscriber, you can even read it free. Enjoy.