
New Cardinality Estimator, New Missing Index Requests
During some testing with SQL Server 2014’s new cardinality estimator, I noticed something fun: the new CE can give you different index recommendations than the old one.
I’m using the public Stack Overflow database export, and I’m running this Jon Skeet comparison query from Data.StackExchange.com. (Note that it has something a little tricky at the top – it’s using a local variable for the @UserId, which itself makes for a different execution plan. When literals are used in the query, the behavior is different, but that’s another story for another blog post.)
First, here are the two different execution plans, both of which do about 1mm logical reads:


It’s a really subtle difference in the plans – at first glance, just looks like the 2014 CE removed a single operator – but the big difference is in the number of estimated rows returned:
- Old CE estimated 82 rows returned
- New CE estimated 352,216 rows returned
In actuality, 166 rows get returned with this particular input variable – the new CE is just flat out making bad guesses on this data.
Here are the different index recommendations:
|
1 2 3 4 5 6 7 |
CREATE NONCLUSTERED INDEX NewCE_OwnerUserId_Includes ON [dbo].[Posts] ([OwnerUserId]) INCLUDE ([ParentId],[Score]); CREATE NONCLUSTERED INDEX OldCE_OwnerUserId_PostTypeId_Includes ON [dbo].[Posts] ([OwnerUserId],[PostTypeId]) INCLUDE ([ParentId],[Score]); |
And when I run sp_BlitzIndex® after doing a little load testing, both missing index recommendations show up in the DMVs:
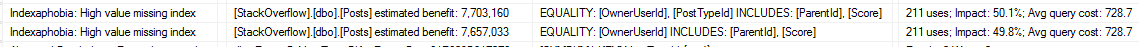
But surely the new CE’s recommendation is better. We’ll create just the one it recommends, and the resulting execution plan does 57k logical reads. Both the new CE and the old CE produce an identical plan, albeit with wildly different row count estimates (old 83, new says 37,423, actual is 166):
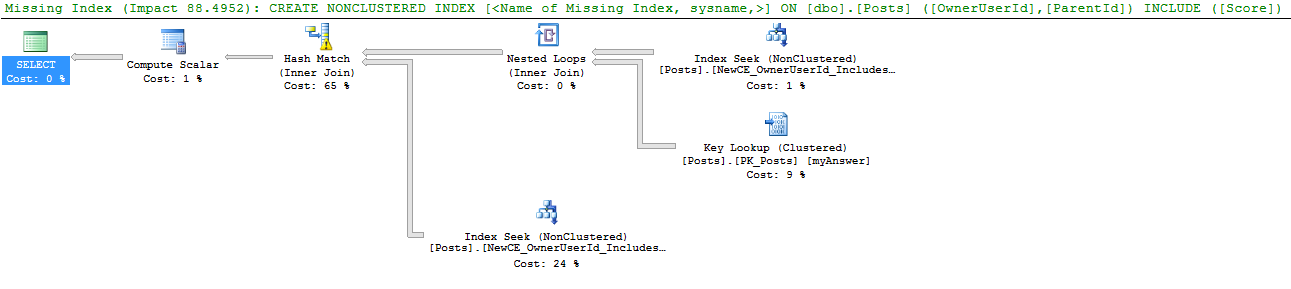
HAHAHA, now the new CE agrees that it needs the index recommended by the old CE in the first place. So let’s remove the new CE’s recommendation, and only create the old CE’s recommended index. Both the old and new CE choose to use it:

And even better, the old CE’s recommendation results in only 175 logical reads.
So what’s the takeaway? If you’re relying on the execution plan’s missing index recommendations for fast performance tuning, you’re not going to get the best results – no matter which cardinality estimator you’re using. With 2014, the recommendations are different, not necessarily better.
The real keys are knowing how to do it yourself, and we teach you how in our training classes.

3 Comments. Leave new
Well, you’d hope that 95% of your queries wouldn’t go so poorly, though I admit it’s probably tempting to assume that the DB engine and its constituent parts will know better than you if you have a few years of trying to second-guess execution plans under your belt.
It’s a great article despite brevity, especially since on your very site you have Kendra displaying the new CE eating one of her purposefully terrible queries for breakfast (a few months back now, I believe); but would you mind giving an indication of how “far” into your testing you picked up on this? As in, were you 99% sure that this CE was the Next Best Thing and then stumbled across this; or did you pick up on certain odd behaviours and then decided to lead it down your suspected path with this query; or did it come up out of the blue?
Apologies if it seems like I’m grilling you, I have mad respect for you and would love to be able to afford the course you mentioned (one day, I promise — and don’t think I’m dismissing it as a plug either; this is the first “hold up!” criticism I’ve seen of the new CE) but this is a specific area of interest while we’re transitioning to 2014. I’m aware that MMMV and that full testing should take place as always. We’ll endeavour to test just as much as we always have 🙂
Simon – great question. I wrote this when I was writing my Microsoft Ignite session demos. I wanted to show whether the cardinality estimator made a difference in a particular workload. I just happened to be looking at the plans for other reasons, and noticed the missing index difference.
Is there an across-the-board rule about which CE is better? Of course not, as I’m sure you know – you have to do your testing with your own workloads. Hope that helps!
Of course, hence my slightly sarcy comment about testing at the end 🙂 even more interesting when I think that it was the missing index recommendations that tipped you off, as I’m generally inclined to dismiss that there green text as “might be a problem, but MS will want you to include every other column in the universe; instead let’s see if we can avoid creating yet another index” (then again, sp_BlitzIndex, props).
And now you’ve got me playing with the StackOverflow database. Thanks. You realise I have to get up for work later, right?