
Update – October 2015 – You can download a Torrent of a database (rather than a data dump) now.
Most of my demos involve my favorite demo database: Stack Overflow. The Stack Exchange folks are kind enough to make all of their data available via BitTorrent for Creative Commons usage as long as you properly attribute the source.
There’s two ways you can get started writing queries against Stack’s databases – the easy way and the hard way.
The Hard Way to Query StackOverflow
First, you’ll need to download a copy of the most recent XML data dump. These files are pretty big – around 15GB total – so there’s no direct download for the entire repository. There’s two ways you can get the September 2013 export:
- Download them from Mega – which lets you pick the specific sites you’d like to download.
- Download them all at once via BitTorrent with the StackExchange torrent link at Archive.org
I strongly recommend working with a smaller site’s data first like DBA.StackExchange. If you decide to work with the monster StackOverflow.com’s data, you’re going to temporarily need:
- ~15GB of space for the download
- ~60GB after the StackOverflow.com exports are expanded with 7zip. They’re XML, so they compress extremely well for download, but holy cow, XML is wordy.
- ~50GB for the SQL Server database (and this will stick around)
Next, you need a tool to load that XML into the database platform of your choosing. For Microsoft SQL Server, I use the Stack Overflow Data Dump Importer.
The SODDI user interface expects two things:
- The XML files have to be stored in a very specific folder name: MMYYYY SITEINITIALS, like 092013 SO. SODDI will import multiple sites, and it creates a different schema for each site.
- All of the XML files for the site have to be present in that folder: Badges, Comments, PostHistory, PostLinks, Posts, Tags, Users, and Votes.
When you run SODDI.exe without parameters, this GUI pops up (assuming that you named your Stack Overflow demo folder 092013 SO):
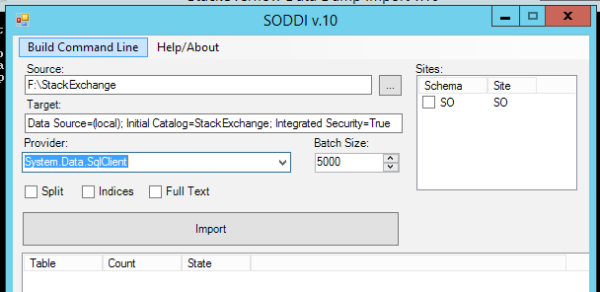
Source is the folder where you saved the data dumps. It expects to see subfolders in there for 092013 SO.
Target is the connection string for your database server. I’m using a local SQL Server (note that I picked SqlClient in the Provider dropdown) with a database named StackOverflow, so my connection string is:
Data Source=(local); Initial Catalog=StackOverflow; Integrated Security=True
If you want to use a remote SQL Server, you’d put its name in there instead of (local). You’ll also need to pre-create the database you want to use.

Click Import, and after a lot of disk churn, you’re rewarded with a StackOverflow database with tables for Badges, Comments, Posts, PostTypes, Users, Votes, and VoteTypes.
The resulting database is about 50GB. SQL Server’s data compression doesn’t work too well here because most of the data is off-row LOBs. Backup compression works well, though, with the resulting backup coming in at around 13GB.
Why Go to All This Work?
When I’m teaching performance tuning of queries and indexes, there’s no substitute for a local copy of the database. I want to show the impact of new indexes, analyze execution plans with SQL Sentry Plan Explorer, and run load tests with HammerDB.
That’s what we do in our SQL Server Performance Troubleshooting class – specifically, in my modules on How to Think Like the Engine, What Queries are Killing My Server, T-SQL Anti-patterns, and My T-SQL Tuning Process. Forget AdventureWorks – it’s so much more fun to use real StackOverflow.com data to discover tag patterns, interesting questions, and helpful users.
The Easy Way to Query StackOverflow.com
Point your browser over to Data.StackExchange.com and the available database list shows the number of questions and answers, plus the date of the database you’ll be querying:
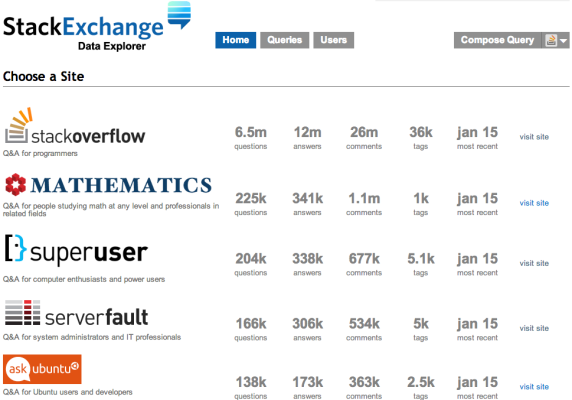
At the time of this writing, the databases are updated every Monday. If you want even more recent data, you can use the Stack Exchange API, but that’s a story for another day.
Click on the site you’d like to query, and you’ll get a list of queries you can start with, or click Compose Query at the top right. As an example, let’s look at a query that compares the popularity of tags:
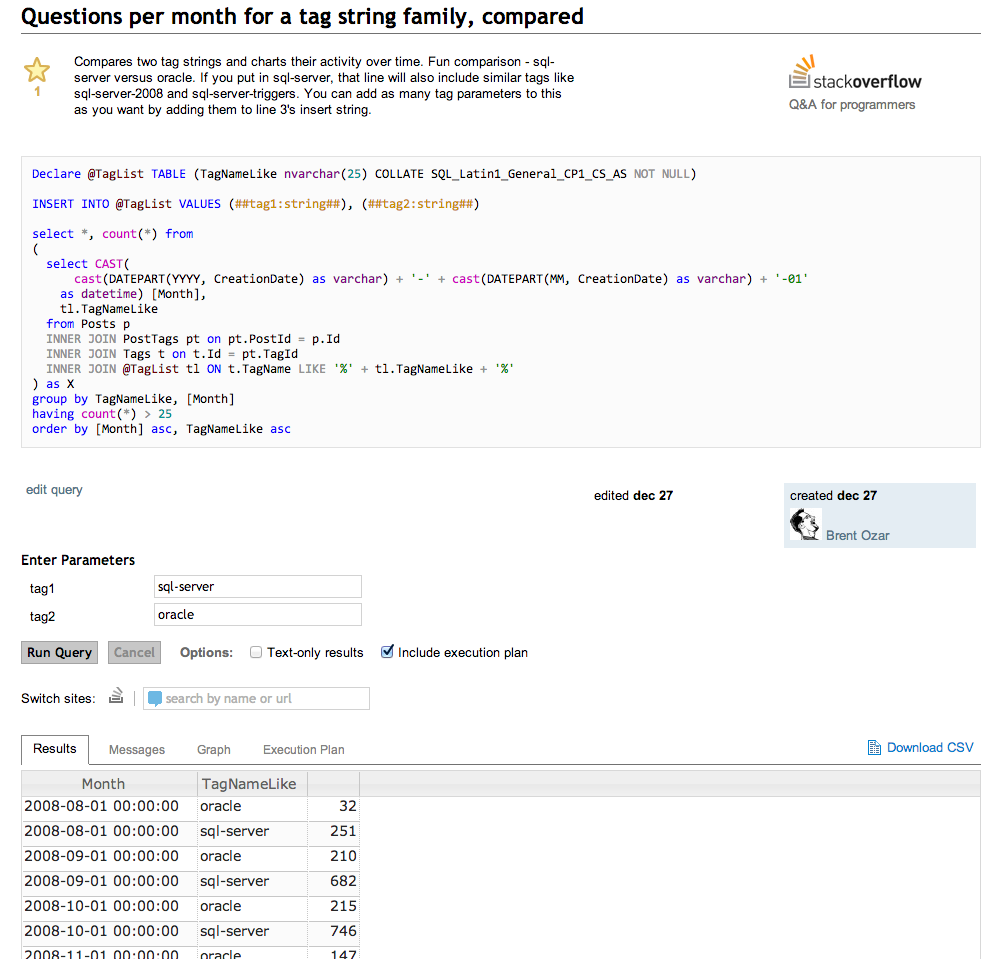
Yes, this is a lot like SQL Server Management Studio in the browser. At the top, we’ve got our query, plus space for a couple of parameters. One of the fun parts about Data Explorer is that you can design queries to take parameters to show information for different users, date ranges, tags, etc.
At the bottom, notice the tabs for Results, Messages, and Graph. If your results look graph-friendly, Data Explorer is smart enough to figure that out:
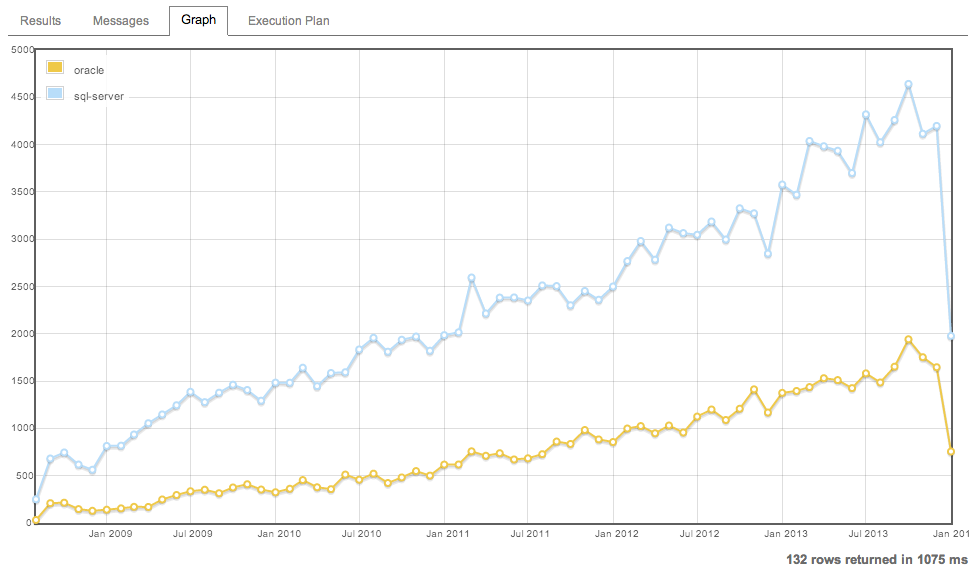
And yes, Data Professional, that last tab does indeed say Execution Plan, and it renders in your browser right down to the ability to hover your mouse over parts of the plan and see more details:
Data Explorer is really easy to use – check out the one-page documentation. It’s even open source, so to learn more about how it works, visit StackExchange.DataExplorer on Github.
Some system commands (like SET STATISTICS IO ON) are allowed, but you can’t create indexes, and there aren’t many indexes to begin with. You can also shoot yourself in the foot by writing an extraordinarily ugly query, and the system won’t stop you – for example, SELECT * FROM Posts will start running, but then may crash your browser as they start returning data. Jeremiah and I managed to repeatedly kill our Chrome browsers while tuning queries for fun.
I like using this to go poking around for unusual questions or answers. For example, I like to find questions that are viewed a lot, but don’t have any upvoted answers yet. (That’s prime territory for a SQL Server geek like me that wants to find tough questions to solve.)

27 Comments. Leave new
Thank you for the good explanation of the “hard way” to download and use the StackOverflow database!
StackStash is an iPhone app that uses compression, and brings the database size down to only 3.6 GB.
http://stackstash.com
How do they do it? I have an iPhone, but I also want to be able to access the StackOverflow database while offline on my MacBook Pro. I’m already doing this for Wikipedia using Wiki2Touch, and Google Maps using MOBAC+phpMBtilesLite.
StackDump uses a local web server, which would be suitable for cross-platform sharing.
http://stackapps.com/questions/3610/stackdump-an-offline-browser-for-stackexchange-sites
However, StackDump also takes up 30GB of space. I know that StackOverflow is large, but the English Wikipedia is only 7.5 GB when used with Wiki2Touch! Are you aware of a StackOverflow query app that allows for fast searching within a limited index, and brings the database size below 5 GB?
My 64GB iPhone is running out of space, with music (no more than 128 kbps MP3), photos (scaled down to iPhone screen resolution, I have all my 20,000 photos in 3.5 GB), Galileo Offline Maps (about 2GB per country), and Wiki2Touch. Please let me know if there’s a suitable web app that can access a compressed database! If there isn’t, would you like me to make one?
Peter – wow, you’re really enthusiastic! Here’s more questions in here than I can answer, but the short story is no, I don’t need an app. My purpose for using the Stack databases is to teach people a database product (Microsoft SQL Server, the same one we use at Stack).
Thanks though, and enjoy the journey!
By the way, I finally did write an offline compressed StackOverflow database app!
https://github.com/peterburk/stackoverflowlocal
The database can be further compressed to only 2.3GB if you run some other scripts to remove unnecessary XML, and unanswered questions.
I’ve used it a lot on my Mac for the last few weeks.
Ooo, thanks for the heads up! I’ll have to play around with that.
Hi Brent,
I tried to do import for Photo stack-exchange on 2011 data dump. Tables for Users, Posts, Badges, Comments and Votes were created successfully. However, as there is no xml file for PostLink in the dump (instead there is PostHistory.xml), so for that table I received an error. How could I modify SODDI to run successfully on other stack exchange sites besides Stack overflow for my 2011 data dump. I am using SODDI version 1.0.
PS: you could delete my previous irrelevant comments to your post!
Thanks
Smrite – unfortunately this is beyond the scope of something I can help you with in blog comments. Try posting this on http://meta.stackoverflow.com.
Hello, i’m trying to do this, but SODDI tells me this: “Cannot open database xxxx requested by the login. The login failed. Login failed for user HOST\user”.
I’m using SQL Server 2014, and VS 2010, what happens?
I just want to see a community shema, not the data, could you please send me a script of the model schema? thanks:D!
Hi Jonathan. To see the basic schema, head over to http://data.stackexchange.com. You can query it online. Enjoy!
Ok, i’ve got a question, you work at SE right?, is there any super db, i mean, for each community there’s a db, but “Users” table has a fk “AccountId” is that related to any mother db? does SE has a db to manage all others?, where’s the account of SE stored?, do we have access to that db?
Jonathan – I’m a consultant for SE, and yeah, there are other databases that aren’t included in the exports.
I ran into an issue while attempting to extract the large files using the 7Zip UI. It ate up hard drive space in my user temp folder filling up the hard drive. Changing the temp folder in the UI didn’t work. My workaround was just using the shell extension to extract directly to my destination.
Hello,
When I press the import button in the SODDI GUI, I get an error that the source path is invalid
Wow! Brent, Thank you! I’ve followed a “hard way” this year 🙂 (but anyway I needed that :)), but querying in browser with all that great tools and information, it is awesome!
Just wanted to say that you can also start the torrent download from Archive.Org, then tell your bittorrent client to ignore most files and just get the select few you’re interested in.
Hello,
When I press the import button in the SODDI GUI, I get an error that the source path is invalid
That means that your source path is invalid. It doesn’t point to where the Stack database exports live.
Hi, nice explanation.
I do not understand the difference between #1 – archive.org/details/stackexchange and #2 – https://data.stackexchange.com/stackoverflow/query/new .
For each database in #1 we only have 8 tables, while in #2, stackExchange folks, provide 27 tables.
Why do we have this difference?
Thanks
Igor – that’s a great question. Why don’t you ask it over at http://meta.stackoverflow.com/ where Stack questions are discussed?
Hello Brent Ozar,
When I press the import button in the SODDI GUI, I get an error with field “RevisionGUID” of PostHistory table.
Error Detail: The given value of type String from the data source cannot be converted to type uniqueidentier of the specified target column.
Thanks,
Gioi – hi, and welcome to the site. For support on open source tools, you’ll want to go to the Github repo for that tool, and open an issue. Include as much detail as you can, like the exact build of SODDI that you’re using, and the data dump you’re importing.
Hi All,
Thanks Brent for a very useful post! If you want an alternative way of importing the tables individually, (as mentioned above SODDI.exe requires that all the xml files are available) I have written a blog post on how to do it here, http://www.sqlserversnippets.com/2017/05/how-to-import-large-xml-file-into-sql_95.html. Hope it is of use.
Am I just stupid or is there no soddi.exe on GitHub (some thing needs to be complied perhaps). All I wanted was a large database (I am a DBA, or at least I like to think I am).
Santa – yeah, if you’re not comfortable compiling it, you’re better off just downloading the database:
https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
Wow, I can believe you replied so fast, Brent. Thanks. Also, I just installed VisualStudio and got the soddi.exe with a bit of fooling around. Thanks again 🙂
Hello Everyone,
I wanted to know if you could connect StackOverflow directly from SSMS? I think that would be helpful and easier to browse through the data.
It would be easier for you to connect to someone else’s database server? Yes, yes, I’m sure that it would. Who would you like to pay the licensing costs for that?
Thank you, I like the “Easy way” you suggested 🙂 I will also plan for the hard way.
I also saw the SPID in different tabs came same (61) and the credential was also not my ID but a common one, STACKEXCHANGE\svc_sede