How to Create Deadlocks and Troubleshoot Them
5 Comments
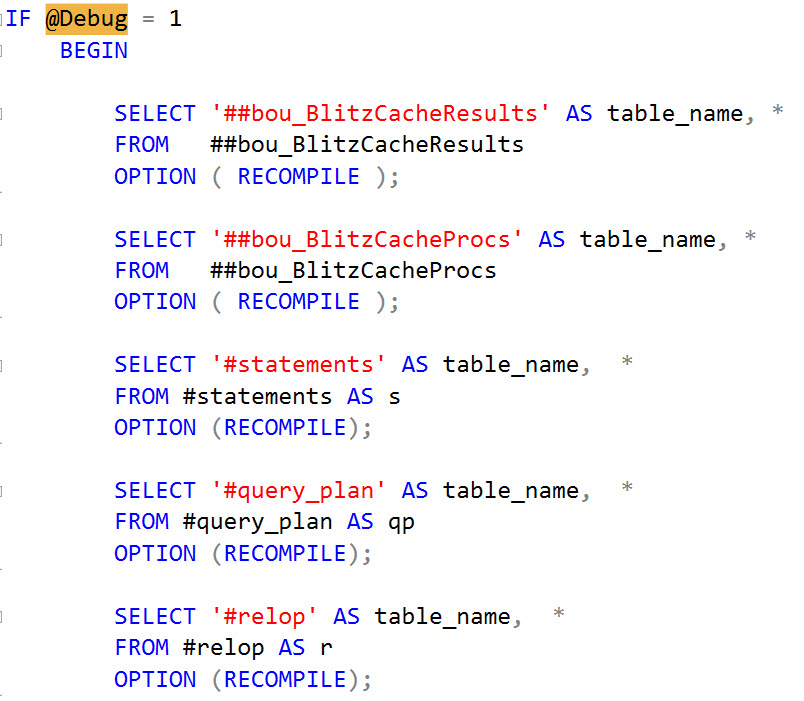
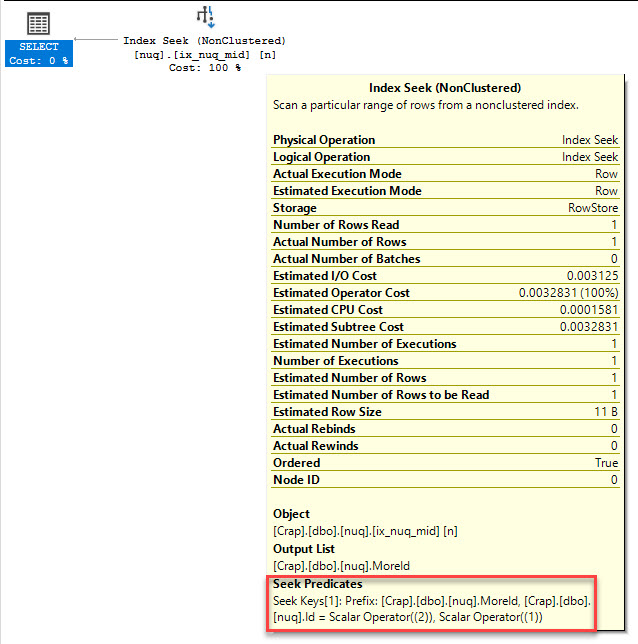
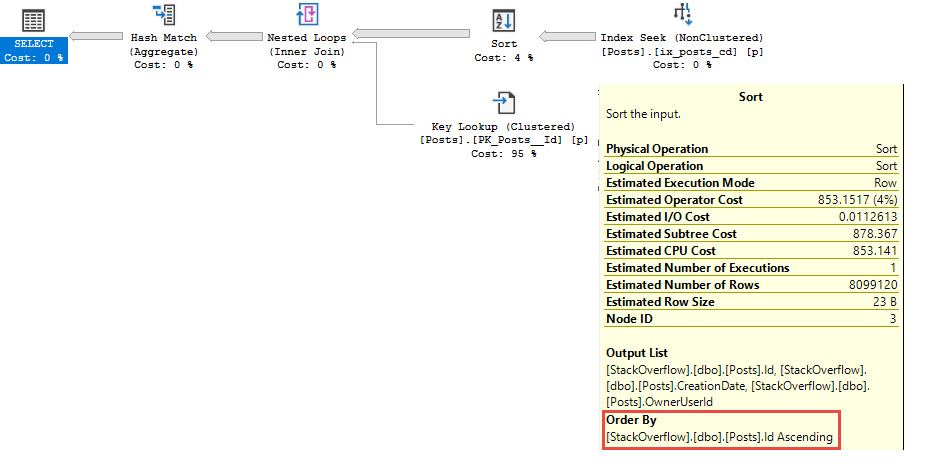
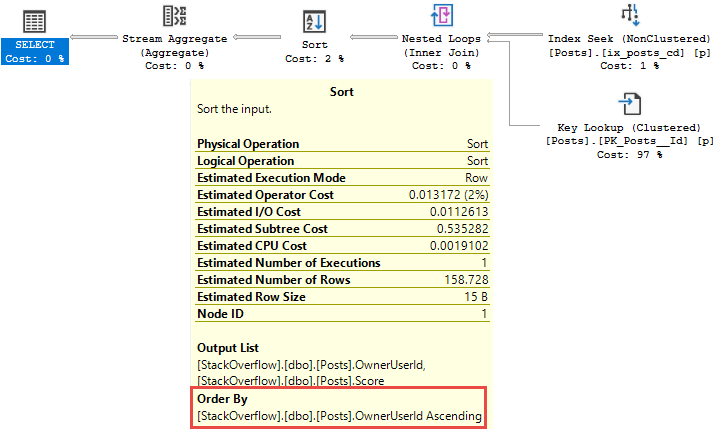
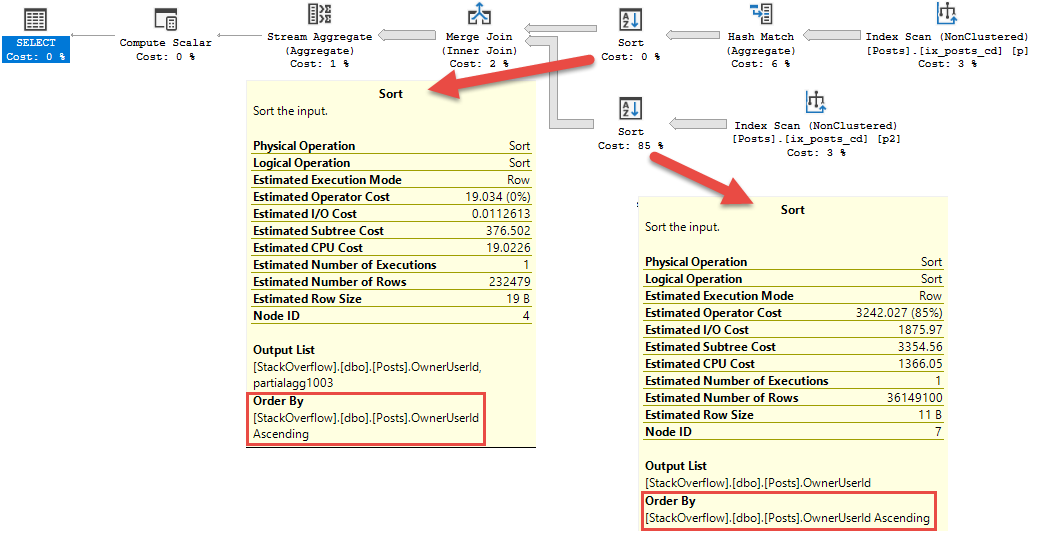
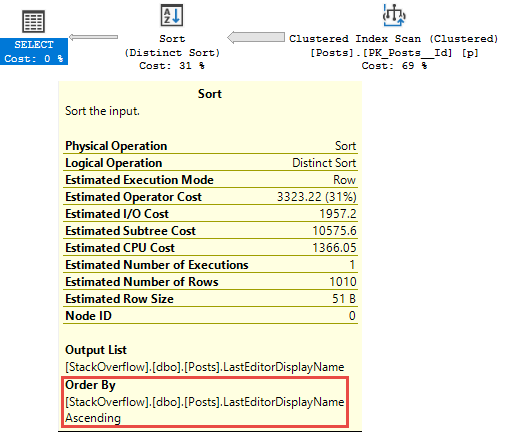
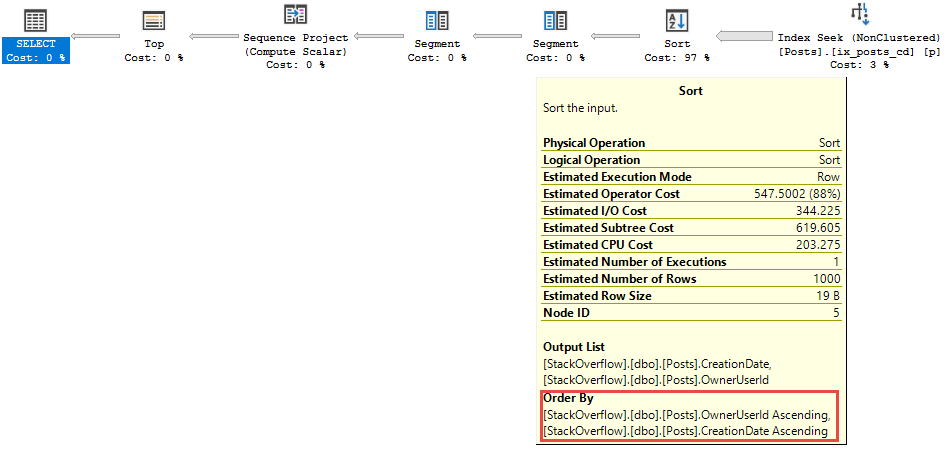
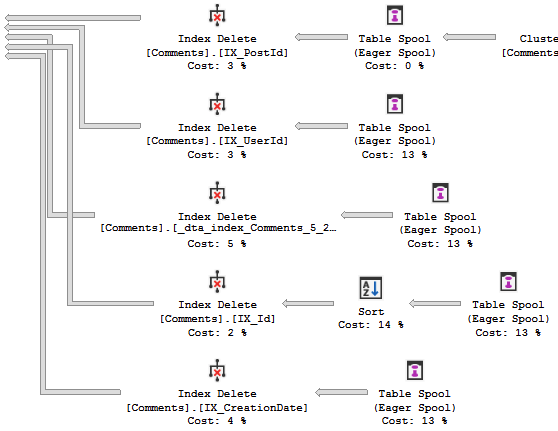
Watch in awe and wonder as I create a deadlock, then use sp_BlitzLock after the fact to show you which queries and tables were involved:
Here are the scripts to run in the left hand window:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE dbo.Lefty (Numbers INT PRIMARY KEY CLUSTERED); INSERT INTO dbo.Lefty VALUES (1), (2), (3); CREATE TABLE dbo.Righty (Numbers INT PRIMARY KEY CLUSTERED); INSERT INTO dbo.Righty VALUES (1), (2), (3); GO BEGIN TRAN UPDATE dbo.Lefty SET Numbers = Numbers + 1; GO UPDATE dbo.Righty SET Numbers = Numbers + 1; GO |
And here are the right hand window commands:
|
1 2 3 4 5 6 7 8 |
BEGIN TRAN UPDATE dbo.Righty SET Numbers = Numbers + 1; GO UPDATE dbo.Lefty SET Numbers = Numbers + 1; GO |
sp_BlitzLock is available in our free First Responder Kit.
To learn more about locking, blocking, and concurrency, check out my Mastering Query Tuning class.