Performance Tuning
Where Clustered Index Keys Dare
Colonel Clustered
We’ve blogged a couple times about how clustered index key columns get stored in your nonclustered indexes: here and here.
But where they get stored is a matter of weird SQL trivia. You see, it depends on how you define your nonclustered index.
“It Depends”
We all scream for dependencies! Hooray!
If you define your nonclustered index as unique, they get stored down at the leaf level. Depending on how you draw your indexes, that’s either the top or the bottom.
If you define your nonclustered indexes as non-unique, they get stored all throughout your index. Irregardless.
Proofs
We need a couple tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
USE Crap; /*Two aptly named tables*/ CREATE TABLE dbo.uq ( Id INT NOT NULL, MoreId INT NOT NULL, SomeJunk VARCHAR(100) DEFAULT 'X' ); CREATE TABLE dbo.nuq ( Id INT NOT NULL, MoreId INT NOT NULL, SomeJunk VARCHAR(100) DEFAULT 'X' ); /*A million rows! WOAH!*/ INSERT dbo.uq WITH(TABLOCKX) (Id, MoreId) SELECT x.n, x.n * 2 FROM ( SELECT TOP 1000000 ROW_NUMBER() OVER (ORDER BY @@SPID) AS n FROM sys.messages AS m CROSS JOIN sys.messages AS m2 ) AS x; /*PK/CX*/ ALTER TABLE dbo.uq ADD CONSTRAINT pk_uq_id PRIMARY KEY ( Id ); /*A unique index*/ CREATE UNIQUE NONCLUSTERED INDEX ix_uq_mid ON dbo.uq ( MoreId ); /*Duplicate rows into second table*/ INSERT dbo.nuq WITH ( TABLOCKX ) ( Id, MoreId ) SELECT u.Id, u.MoreId FROM dbo.uq AS u; /*PK/CX*/ ALTER TABLE dbo.nuq ADD CONSTRAINT pk_nuq_id PRIMARY KEY ( Id ); /*A non-uniqueindex*/ CREATE NONCLUSTERED INDEX ix_nuq_mid ON dbo.nuq ( MoreId ); /*Just so you know I'm not lying!*/ /*DON'T REBUILD INDEXES AT HOME!*/ ALTER TABLE dbo.uq REBUILD; ALTER TABLE dbo.nuq REBUILD; |
What we have here are two nearly identical tables. They only difference is that one has a unique nonclustered index, and one is not unique.
If I run these two queries, I get two nearly(!) identical plans.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT u.MoreId FROM dbo.uq AS u WITH (INDEX = ix_uq_mid) WHERE u.MoreId = 2 AND u.Id = 1 AND 1 = 1; SELECT n.MoreId FROM dbo.nuq AS n WITH (INDEX = ix_nuq_mid) WHERE n.MoreId = 2 AND n.Id = 1 AND 1 = 1; |
Rule The World
But if you’re paying very careful attention, there are slight differences.
In the unique nonclustered index, the predicate on the Id column (which is the PK/CX), is a residual predicate, and the predicate on MoreId is a seek predicate

That means we did a seek to the MoreId value we wanted, and then checked the predicate on Id.
In the non-unique nonclustered index, both predicates are seekable.
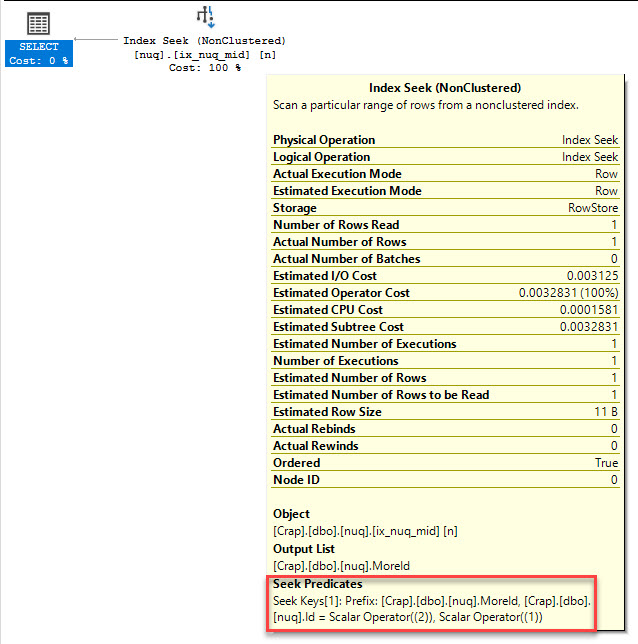
What Does This Prove?
Not much on its own, but let’s zoom in a little.
If we look at sp_BlitzIndex, we get different output, too.
|
1 2 3 |
EXEC master.dbo.sp_BlitzIndex @DatabaseName = N'Crap', @SchemaName = N'dbo', @TableName = N'uq'; |

The unique nonclustered index shoes the Id column as an Include, and is 14.1MB.
|
1 2 3 |
EXEC master.dbo.sp_BlitzIndex @DatabaseName = N'Crap', @SchemaName = N'dbo', @TableName = N'nuq'; |

The non-unique index doesn’t list the Id as an Include, but as a regular column. It’s also slightly larger, at 14.2MB.
These two things, combined with the query plans, should be enough.
Can We Duplicate It?
Here’s another example that’s a bit more explicit. Two identical tables, except for the nonclustered index definitions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/*yay*/ CREATE TABLE dbo.seeky ( id INT PRIMARY KEY CLUSTERED, b_id INT NOT NULL, c_id INT NOT NULL ); /*nay*/ CREATE TABLE dbo.scanny ( id INT PRIMARY KEY CLUSTERED, b_id INT NOT NULL, c_id INT NOT NULL ); /*both key columns*/ CREATE INDEX ix_seeky ON dbo.seeky ( b_id, c_id ); /*one included column*/ CREATE INDEX ix_scanny ON dbo.scanny ( b_id ) INCLUDE ( c_id ); /*both seek predicates*/ SELECT * FROM dbo.seeky AS s WHERE s.b_id = 1 AND s.c_id = 1 AND 1 = 1; /*residual on c_id*/ SELECT * FROM dbo.scanny AS s WHERE s.b_id = 1 AND s.c_id = 1 AND 1 = 1; |
If you examine the plans, they have a similar outcome. The two key columns allow both predicates to be seeked, and the one key/one include index results in a residual.
Say that ten times fast while you’re drunk and alone in your dark office.
What Does It All Mean?
Aside from some SQL Jeopardy points, this isn’t likely to get you much. It’s mostly an implementation point of interest.
SQL Server adds clustered index key columns to nonclustered indexes for many good reasons. It makes key lookups possible, and is probably pretty helpful when checking for corruption.
When people ask you if there’s any penalty to adding clustered index key columns, the answer is (and always has been) no, absolutely not.
They’re going to be there no matter what, but now you know exactly where they’re going to be.
Thanks for reading!
Brent says: oh wow, the predicate-vs-seek-predicate is a really good way of showing how things are ordered in an index. Nice explanation.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
Interesting… so I wonder, is the reason for putting the clustered index keys as additional keys in a non-unique clustered index (instead of at the leaf level) a way to make that non-unique index actually unique (when you include the clustered index keys too)…
And if so, what about if your clustered index is itself non-unique… I guess the uniqueifier would also be a key now in the nonclustered index, not at the leaf…
This is making me think that in reality, all indexes in SQL server truly are unique in terms of how they are stored. Mind-blower…
Thanks for the post!
Steve — yeah, and without GUIDs 😉
I wonder if it is to create an order, so that records with the same key value are not just in random order. Don’t know why that would be a problem, but… There’s always reasons for these little details – it’s figuring out what they are that’s hard though. Thanks Erik for an enlightening post!
Yes. Say you have a table with 200 million rows. You create a CI on a column with a few ten thousand unique values. SQL would need a way to identify the location of every value.
This used to be a big thing many years ago when creating a CI on an column other than a column with unique numbers was a big performance no no. Storage and memory were a lot more expensive and the extra space required for this data would have been considered wasted
Great read!! It’s an interesting take on things. Also, to add If we run DBCC PAGE command on the indexes, for non-unique clustered index we see a new column of Primary key added.
Thanks for writing!!