SUM, AVG, and arithmetic overflow
15 Comments
You Shoulda Brought A Bigger Int
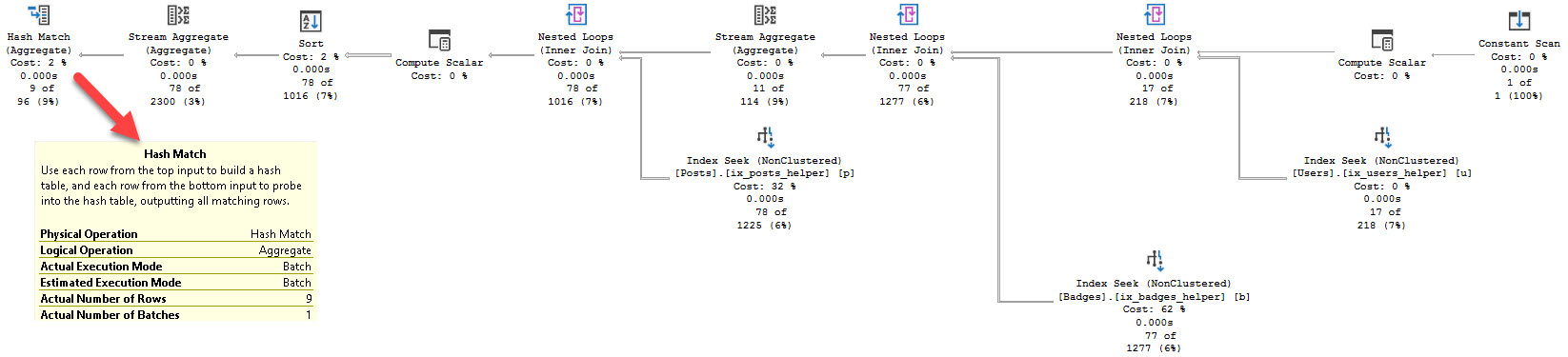
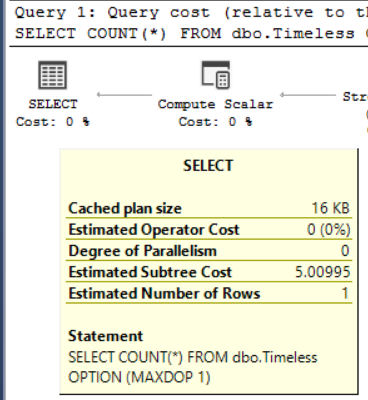
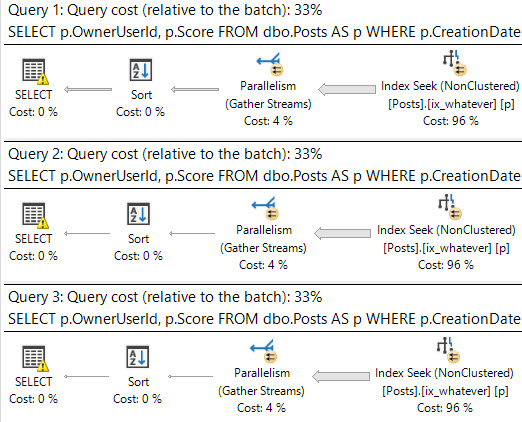
Sometimes you run a query, and everything goes fine.
For a while. For example, if I run this query in the 2010 copy of Stack Overflow, it finishes pretty quickly, and without error.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT u.Id, u.DisplayName, SUM(p.Score) AS SumPostScore, AVG(c.Score) AS SumCommentScore FROM dbo.Users AS u JOIN dbo.Posts AS p ON u.Id = p.OwnerUserId JOIN dbo.Comments AS c ON u.Id = c.UserId WHERE u.Reputation >= 10000 AND p.PostTypeId = 2 AND p.Score >= 10 AND c.Score >= 1 GROUP BY u.Id, u.DisplayName |
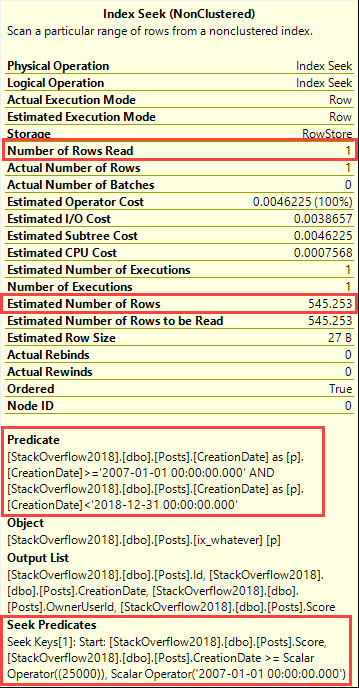
If I run this query in the full version, it runs for a minute and a half, and then returns an error:
|
1 2 |
Msg 8115, Level 16, State 2, Line 4 Arithmetic overflow error converting expression to data type int. |
They Shoot Horses, Don’t They?
Now, we’ve had COUNT_BIG for ages. Heck, we even need to use it in indexed views when they perform an aggregation. More recently, we got DATEDIFF_BIG. These functions allow for larger integers to be handled without additional math that I hate.
If one day you got an email that this query suddenly started failing, and you had to track down the error message, what would you do?
I’d probably wish I wore my dark pants and start running DBCC CHECKDB.
I kid, I kid.
There are no pants here.
Anyway, it’s easy enough to fix.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT u.Id, u.DisplayName, SUM(CONVERT(BIGINT, p.Score)) AS SumPostScore, AVG(CONVERT(BIGINT, c.Score)) AS SumCommentScore FROM dbo.Users AS u JOIN dbo.Posts AS p ON u.Id = p.OwnerUserId JOIN dbo.Comments AS c ON u.Id = c.UserId WHERE u.Reputation >= 10000 AND p.PostTypeId = 2 AND p.Score >= 10 AND c.Score >= 1 GROUP BY u.Id, u.DisplayName |
You just have to lob a convert to bigint in there.
Data Grows, Query Breaks
This is a pretty terrible situation to have to deal with, especially if you have a lot of queries that perform aggregations like this.
Tracking them all down, and adding in fixes is arduous, and there’s not a solution out there that doesn’t require changing code.
I was going to open a User Voice item about this, but I wanted to get reader feedback, first, because there are a few different ways to address this that I can think of quickly.
- Add _BIG functions for SUM, AVG, etc.
- Add cultures similar to CONVERT to indicate int, bigint, or decimal
- Change the functions to automatically convert when necessary
- Make the default output a BIGINT
There are arguments for and against all of these, but leave a comment with which you think would be best, or your own.
Thanks for reading!