
When it comes to indexes, SQL Server is really helpful. It lets you see what indexes queries are asking for both in execution plans, and missing index dynamic management views (“DMVs”). I like to look at the DMV missing index requests using sp_BlitzIndex®.
When you look at missing index requests, it’s always important to remember one of the biggest things: these missing index requests won’t ever ask for or recommend a specific clustered index.
Let’s take a look at what this might mean against a slightly modified version of the AdventureWorks2012 sample database.
Hey, we have a high Value missing index!
Let’s say we run sp_BlitzIndex® and it diagnoses that we have a high value missing index.
|
1 2 3 |
--To diagnose a database, we would run: EXEC dbo.sp_BlitzIndex @database_name='AdventureWorks' |

We scroll to the right on this line to get more info and see that the index request has an overall “benefit” over over one million. That benefit is a made up number– it’s a combination of the number of times the index could have been used, the percentage by which SQL Server thought it would help the queries generating the request, and the estimated “cost” of the requests. These factors are all multiplied together to help bubble up the biggest potentially useful requests.

We also see that the index request is really quite narrow. It only wants an index with a single key column on the “City” column! That seems really reasonable.
Scrolling over farther, we can see that this could have potentially been used about 49 thousand times. The queries that could have used it (it’s quite possibly more than one), were rather cheap– their costs were less than one on average– and it would have improved those queries a whole lot (around 93% overall). We currently don’t have ANY nonclustered indexes on the table in question, so we don’t have to worry about creating a duplicate nonclustered index.

This index seems really reasonable. It would be used a lot, and it would help those queries out.
If we keep going to the right, we see that there’s some sample TSQL to create the suggested index at the far right:
|
1 |
CREATE INDEX [ix_Address_City] ON [AdventureWorks].[Person].[Address] |
Sure enough, that syntax will create a nonclustered index. That seems really good, but hold on a second!
Always look at the whole table
Just to the left of the “Create TSQL” column is a really important helper– the “More Info” column.

Copy the command from the appropriate row out. It will look something like this:
|
1 2 3 4 |
EXEC dbo.sp_BlitzIndex @database_name='AdventureWorks', @schema_name='Person', @table_name='Address' |
This command will help you look at the whole table itself and assess if there might be something you’re missing.
When you run this command, you’ll see a big picture view of the indexes on the table, the missing index requests for the table, and the number and types of the columns in the table:

In this table, note that we don’t even have a clustered index. This table is a heap! Heaps have all sorts of wacky problems in SQL Server.
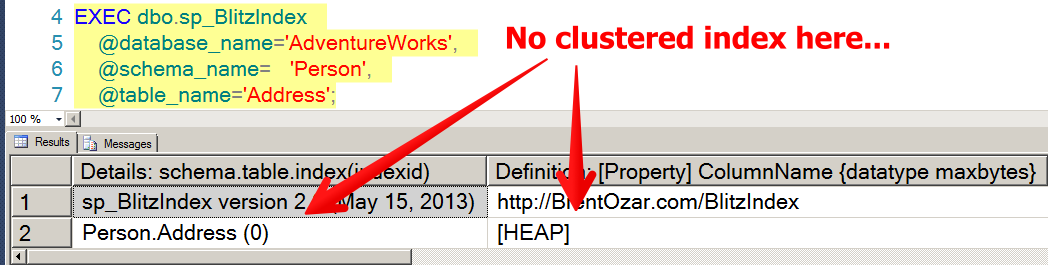
In this case, we have an OLTP database and we definitely want to avoid heaps to keep our sanity.
Our queries are requesting an index on the City column, but it looks an awful lot like our table was modeled with another clustered index in mind (AddressID). Don’t just assume that the missing index request itself will always make the best clustered index. You need to take a look at your overall workload and the queries which use the table. You need to decide based on the whole workload and overall schema what should be the clustered index, if you have a primary key, and if the primary key is the same thing or different than the clustered index. After you have that design, then make decisions for your nonclustered indexes.
The clustered index is special
The clustered index in any table has special uses and significance. This index is the data itself, and it will be used in every nonclustered index in the table. If you are defining a new clustered index or changing a clustered index, SQL Server will need to do IO on every nonclustered index on the table as well. Always make sure to test your indexing changes and choose your index definitions carefully.
Wanna learn more? Check out our indexing training.

3 Comments. Leave new
Awesome and powerful script to find all the information about the indexes.
thanks a lot!
Always have a separate RAID 10 volume for non-clustered indexes.
Hi Josh,
There’s some older advice around the internet that says you always need separate spindles and separate filegroups for nonclustered indexes, but I’ve typically found that to not help performance, and in some cases to cause significant wasted space because free space is needed in each filegroup for maintenance purposes. In your example it would also be expensive empty space!
Instead, I typically find that clustered index performance is often quite as important as nonclustered, and that selecting the right indexes and allocating enough memory is the best route.
I do like the use of filegroups for larger databases, but I don’t ever design them strictly by clustered/nonclustered index type.
Kendra