Getting Sneaky With Forced Parameterization
Silly Rules
I’ve blogged about some of the silly rules about where Forced Parameterization doesn’t work.
One rule that really irked me is this one:
The TOP, TABLESAMPLE, HAVING, GROUP BY, ORDER BY, OUTPUT…INTO, or FOR XML clauses of a query.
TOP and FOR XML, get used, like, everywhere.
TOP is pretty obvious in its usage. FOR XML less so, but since it took Microsoft a lifetime to give us STRING_AGG, lot of people have needed to lean on it to generate a variety of concatenated results.
Heck, I use it all over the place to put things together for in the First Responder Kit.
Examples
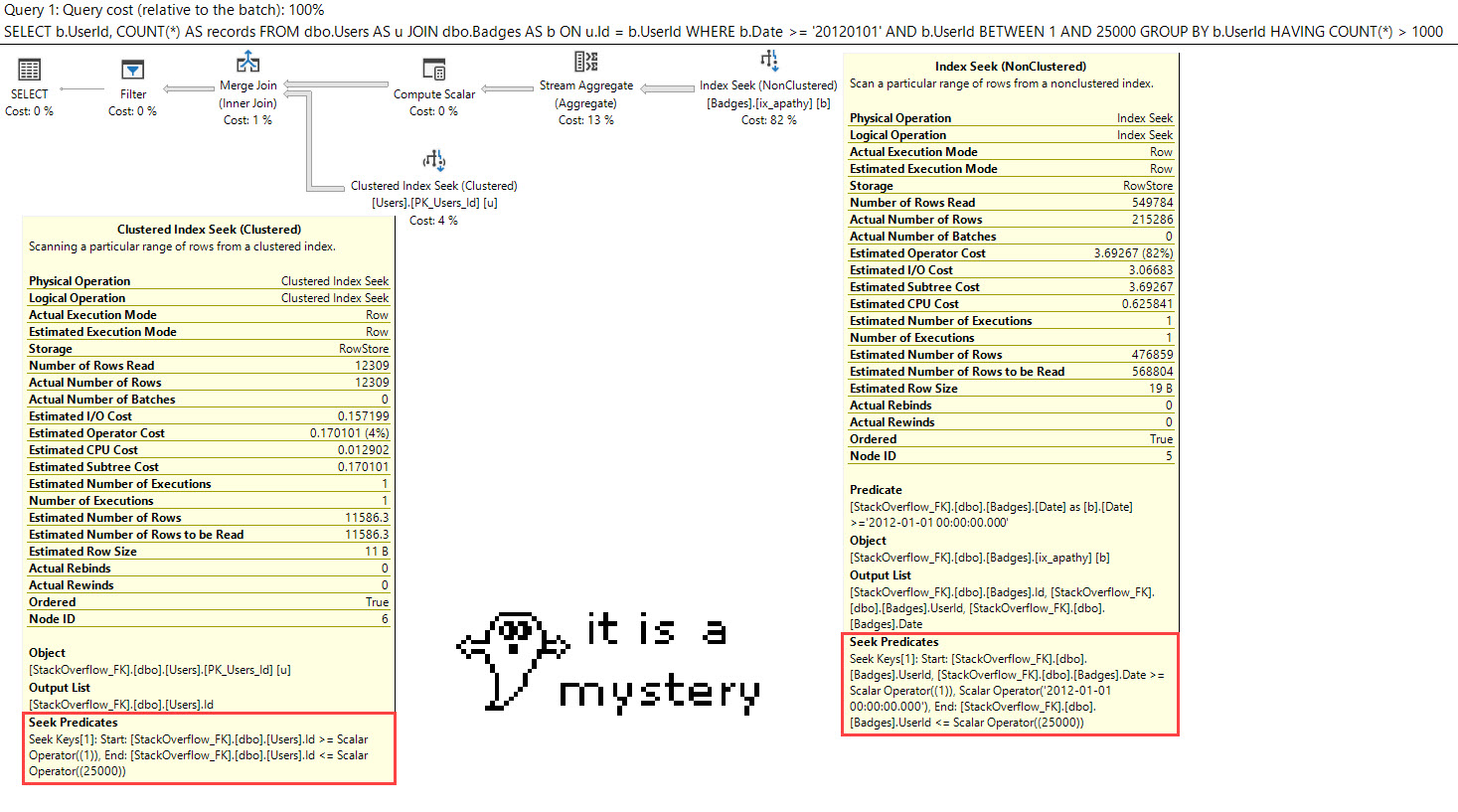
In a database with Forced Parameterization enabled, these queries cannot be parameterized.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
/*FOR XML*/ SELECT p.OwnerUserId, ids = ( SELECT RTRIM(p2.Id) + ', ' FROM dbo.Posts AS p2 WHERE p2.OwnerUserId = p.OwnerUserId AND p2.CreationDate >= '20100101' FOR XML PATH (''), Type ) FROM dbo.Posts AS p WHERE p.OwnerUserId = 8672 GROUP BY p.OwnerUserId; /*TOP*/ SELECT p.OwnerUserId, ids = ( SELECT TOP 1 p2.Id FROM dbo.Posts AS p2 WHERE p2.OwnerUserId = p.OwnerUserId AND p2.Score > 0 ORDER BY p2.Score ) FROM dbo.Posts AS p WHERE p.OwnerUserId = 8672 GROUP BY p.OwnerUserId; |
If we look at the query plans for them, we can see partial parameterization:

The literals passed into our query outside of the illegal constructs are parameterized, but the ones inside them aren’t.
Which means, of course, that we could still end up with the very plan cache pollution that we’re trying to avoid.
For shame.
The Adventures Of Irked Erik
I figured I’d try out some different ways to get around those rules, and it turns out that APPLY is just the trick we need.
For some reason, that’s not mentioned on that page.
I can’t find a newer version.
Maybe my internet is broken?
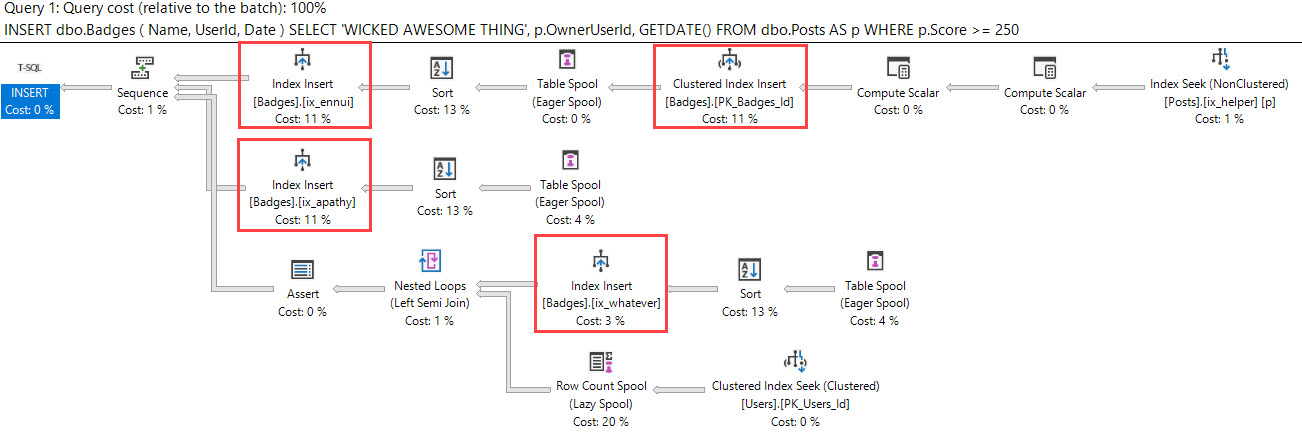
But anyway, if we change our queries to use APPLY instead, we get full parameterization:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT TOP 1 p.OwnerUserId, ca.ids FROM dbo.Posts AS p CROSS APPLY ( SELECT RTRIM(p2.Id) + ', ' FROM dbo.Posts AS p2 WHERE p2.OwnerUserId = p.OwnerUserId AND p2.CreationDate >= '20100101' FOR XML PATH (''), Type ) AS ca (ids) WHERE p.OwnerUserId = 8672; SELECT p.OwnerUserId, ids FROM dbo.Posts AS p CROSS APPLY ( SELECT TOP 1 p2.Id FROM dbo.Posts AS p2 WHERE p2.OwnerUserId = p.OwnerUserId AND p2.Score > 0 ORDER BY p2.Score ) AS ca (ids) WHERE p.OwnerUserId = 8672 GROUP BY p.OwnerUserId, ca.ids; |
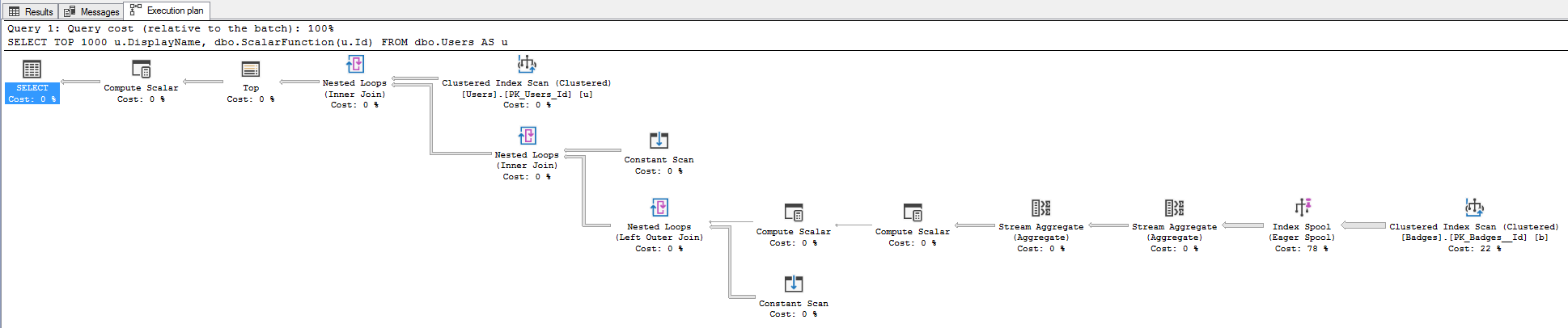
If we look at the new query plans, we can see that:

Bonkers
Partial disclaimer: I only tested this on SQL Server 2017 so far, and that’s probably where I’ll stop. Forced Parameterization is a fairly niche setting, and even if you have it turned on, you may not be able to change the queries.
It’s just something I thought was cute.
Thanks for reading!