#PASSsummit Day 1 Keynote Live Blog
Good morning, folks, and welcome to our annual live blog of the PASS Summit Day 1 keynote.
Open the free live video stream at PASSsummit.com in one browser tab, and then refresh this page every couple/few minutes. I’ll be adding my thoughts at the end of the page, in chronological order, for easier reading later.
Today’s keynote will be presented by Rohan Kumar (@RohanKSQL), GM of Database Systems Engineering.
What I’m Expecting
Microsoft marketing team will probably require Rohan’s team to spend some time shilling SQL Server 2017 even though it’s already shipped. (We’ve even got Cumulative Update 1, complete with some wild bugs.) This means a chunk of the time will be spent showing things that you, dear reader, already knew about because you’re the kind of person who stays very current on blogs and announcements. However, many PASS attendees don’t have that luxury, and they expect Microsoft to catch ’em up to speed in Day 1’s keynote. Plus, this is Microsoft’s chance to trot out customers who’ve already adopted SQL Server 2017 and seen benefits.
However, Microsoft’s showing a willingness to ship features in Cumulative Updates, not just new versions – especially DBA-friendly features that make troubleshooting and tuning easier. We’ve already discovered hidden features in SQL 2017 that aren’t enabled yet – so this would be a great time for them to surprise and delight their fan base. I bet we’ll have at least a couple of feature releases in this keynote that will involve shipping dates before the end of the year.
Let’s see what happens!
Live Keynote Blog

8:21AM – PASS President Adam Jorgensen welcoming everybody and preparing them for “the Rolling Stones of SQL Server” – that’s a great way of saying it. The Microsoft talent here is crazy.

8:26AM – Adam: “PASS is run by the community, for the community.” Talking about how local volunteers make everything possible. I have so much respect for these folks – they do an absolutely heroic amount of work, most of it unseen and unthanked. This is your week to see people speaking, guiding folks around, answering questions in the Community Zone, and take a few moments to say thank you.
8:29 – Adam’s recognizing Tom LaRock for 10 years of volunteer service in the Board of Directors, and Denise McInerney for 6 years of service. (Seriously, that’s a long time, and a lot of meetings. God bless those BoD members – they put up with a lot of flack.)
8:31 – Rohan Kumar from Microsoft takes the stage. He’s talking about how data, cloud, and AI are changing the work we do, and talking about how Microsoft has been investing in AI for a long time. I have one word for you: Clippy. Yes, he sucked, but I can see how Microsoft can say they’ve been investing for a while and trying to bring AI to consumers.

8:36 – The modern data estate allows data to be accepted from any source – structured or unstructured – and it functions across both on-premises and the cloud. “It essentially hides all the differences from the application and the infrastructure management.” That’s a great vision, but we don’t have anything remotely resembling that today. Try a cross-database query or scheduling a job, for example.
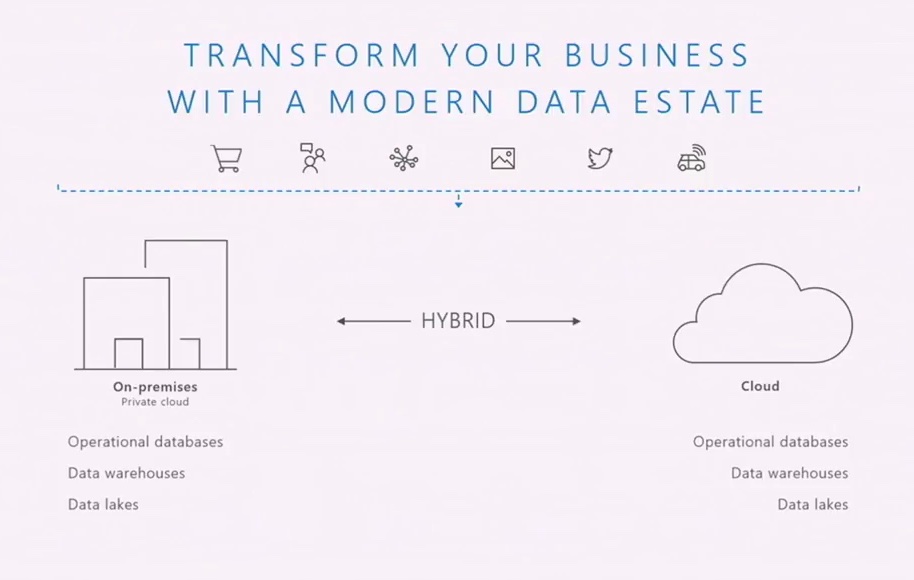
8:38 – Rohan: “Will a developer have to care whether we deploy to the cloud or on-prem? If the answer is yes, we’re not shipping that feature.”
Wait – we need to be specific, dear reader.
He’s right, but there’s one very, very critical word there: “developer.” If you build a new app from the ground up today, in 2017, and if you’re disciplined about what features you use (and don’t use), then you can do what Rohan’s describing. But for existing applications, using tons of legacy features, you cannot do this awesome trick. Try looking at the unsupported features in SQL Server on Linux, or the features not supported in Azure SQL DB.
The Modern Data Platform is absolutely amazing for ground-up new builds, but for existing apps, it’s a shimmering oasis on the horizon, unreachable without a long trek through the desert of code rewrites. Applications built before 2017/2018 are legacy in an entirely new way that really is bad. (Serverless is a similar sea-change in development.)
8:40 Talking about how containers drove a lot of adoption. I think containers was only half of it: Developer Edition is now free. If you would have had to pay to license that easily-downloaded container, adoption rates would be a different story. I bet it took a lot of hard work behind the scenes to convince the bean counters to make Dev Edition free, and it’s starting to pay off here in terms of market share on new platforms. Microsoft’s done a great job here.
8:42 – Bob Ward and Conor Cunningham talking about persistent memory storage, doing a very, very fast series of demos. Not talking about the benchmark speed – these guys are just seriously caffeinated.

8:46 – Maybe a ten second demo of automatic plan correction. Those poor guys had to have been under threat of death if they took more than 5 minutes onstage or something. It’s kinda cool that a day 1 demo goes technical, but…holy cow that was fast. It was like ShamWow but for SQL Server. It’s hard for me to let those guys go offstage once they start talking. COME BACK!
8:49 – “Basically, SQL Server is the fastest database on the planet, period.” I have no idea if that’s true, and I don’t care. I yelled, “WOOHOO!”
At both Ignite and PASS, nobody cheered when he mentioned that it’s a tenth of the price of Oracle. I bet if you surveyed the attendees to ask them what their per-core licensing cost was, and then if you double-checked with their accounting teams, less than ten percent would be within, say, 50% of the number. To database people, either they think it’s expensive (SQL Server, Oracle, DB2), or it’s free (MySQL, PostgreSQL, MongoDB), and there’s not a lot of distinguishing room in there.
8:50 – New features in SQL 2017 include graph data, machine learning with R & Python, native T-SQL scoring, adaptive query processing, and automatic plan correction.
8:53 – Paraphrasing: as data grows, hardware changes, and database features come in, it’s going to be more important for SQL Server’s query optimizer to change its behavior as it learns about the performance of the queries it executes. Given the marketing fluff in some keynotes, you’d be forgiven for thinking that this might just be hype to get people excited, but I bet this is true. Since Microsoft now hosts databases in Azure SQL DB, it’s in their own best interest to fix query plans as quickly as possible in order to reduce their own hosting costs, maximize profit, and make their database look faster than anybody else’s. This reason alone makes me adore Azure SQL DB: it drives improvements in the boxed product, too.
8:55 – Tobias Ternstrom & Mihaela Blendea doing a containers demo. A customer story of this is in Microsoft’s e-book about Linux. dv01’s developers use Docker on their local workstation, then migrate to production with continuous integration. Tobias & Mihaela is showing the new way of doing fast dev environment deployments. In the old world of SQL Server on Windows, Microsoft wouldn’t have been able to get dv01’s business because it’d just have been way too hard to integrate into dv01’s processes of CI/CD. Containers make this possible.

9:01 – Tobias very briefly shows Carbon, the new free SSMS for Linux/Mac/Windows, rendering an execution plan.
9:01 – Rohan announcing SQL Operations Studio, the new “free lightweight modern data operations tool for SQL everywhere.” No release date mentioned, and it’s not on the SQL Server downloads page yet. (Saved you a click.)
Azure SQL DB Announcements
9:04 – “SQL Server and Azure SQL DB…share exactly the same codebase. So all the innovation that you’re seeing released in SQL Server 2017 has been available in Azure SQL DB for several months – in some cases, more than a year now.”
While yes, the code base is shared, the “all the innovation…has been available” line is nowhere near accurate. Go down Microsoft’s list of what’s new in SQL 2017, and lots of this stuff isn’t available in Azure SQL DB. Even if you restrict it to just engine stuff, you’ll notice that docs pages like Using R in Azure SQL Database show limitations up in Azure that you don’t get on premises.
I get twitchy about these claims that they’re exactly the same because it hints to customers that Azure SQL DB is fully testing out everything before it ships in the boxed product. There are whole areas of the engine that just aren’t in use up in the cloud. (And that’s totally okay! I just wish marketing didn’t imply they’re identically used.)

9:07 – Streamlining your journey to the cloud – specifically, PaaS. Managed Instances are coming, lift and shift migration without code changes, and Azure SQL DB cost cuts for Software Assurance owners. I LOVE MANAGED INSTANCES. These changes are so important because they bring Azure SQL DB not just to an equivalent of Amazon RDS for SQL Server, but in most ways, beyond. Amazon RDS has always let you do bigger databases than Azure SQL DB, easier lift-and-shift migrations, and let you reuse your on-premises licensing. However, now Azure SQL DB Managed Instances give you bigger database sizes and readable replicas. There’s just two things left to learn: the exact pricing and the release dates.
9:09 – “We collect 700TB of telemetry data per day.” Yes, and you don’t let developers opt out of that. That’s a time bomb for the Linux/open-source communities – I still think the pushback on that is going to hit hard at some point, and we’re gonna have to let users opt out of SQL Server phoning home.
9:11 – Danielle Dean doing an ML demo with predictions for healthcare, figuring out how long a patient is going to stay. Inserting ~1.4M rows per second, then switching over to a Jupyter notebook, taking that logic and putting the ML model into Azure SQL DB. “Demo” is the wrong word for this pace – it’s just clicking between screens. Nobody’s really learning anything here, and this audience is way beyond the point where they buy “all you do is click and the machine learned everything.” We’re data and developer people, and we know this stuff is hard work. Try cleansing data for 1.4M rows/sec.
9:15 – The demos really feel like somebody loaded up the buzzword shotgun, fired at the screen, and took whatever combo came out. There’s no storytelling here. They’re under too much pressure to sling too many buzzwords in too little time, and it’s going to just wash over the audience. At bare minimum, I would want each demo to end with, “To see the full story on this technology, go to session X at YAM.”
9:17 – The new Azure Data Factory (preview) lets you migrate your SSIS packages as-is up to the cloud. If there’s ever been a bursty load that should be available on demand, priced by the second of consumption, it’s ETL loads. 30+ connectors. I like how they didn’t try to brand it as Flow Enterprise or something like that. Plus, SSIS in Azure, managed environment for SSIS execution. You pick the number of nodes and node size, hourly pricing, licensing costs are bundled in.
That’s pretty awesome for BI consultants who want to take their existing SSIS skills, jump into a new client that doesn’t own any hardware,
9:20 – Scott Currie (CEO of Varigence, the team behind Biml) onstage to do an Azure Data Factory with Biml, pushing from on-premises up to Azure Data Lake, do some data scrubbing, deploy with PowerShell. Announcing general availability today that Biml will have first-class support for creating Azure Data Factory objects. Just change your deployment target, and instead of deploying locally, you’re deploying to ADF.
9:22 – Paraphrasing Rohan: “Azure SQL Data Warehouse is our flagship data warehouse product.” Man, just like ETL work, data warehouses are so totally perfect for the cloud. Outside of compliance requirements (which are usually misinterpreted anyway), I don’t know why you’d wanna deploy a new on-premises data warehouse today if you could avoid it. (I don’t want you to think that OLTP is somehow different, either – if you’re building a ground-up new build OLTP app today, you should try PaaS first.)
9:25 – Julie Strauss doing petabyte data warehouse demo.

Business Intelligence Hybrid Architecture
9:31 – Christian Wade onstage to announce scale-out Azure Analysis Services. It’s another demo of mentioning five keywords, clicking on three places, and pretending like entire projects are done. This makes TV chefs look like project managers. “I just click here and switch windows because I’ve already done a bunch of other stuff.” COME ON, this is not a demo.

9:36 – Announcing scale-out Azure Analysis Services to support hundreds or thousands of concurrent users. Up to 7 read-only replicas.
Okay, I just lost it.
9:37 – Riccardo Muti demoing Power BI Premium connecting to any back end that on-premises Power BI Desktop can connect to, and how mobile reports look. This is actually a good demo, showing reporting UI. That’s a good feature set to cover in a fast demo.
9:44 – Rohan back on stage to wrap it up and explain how you are the key to making all this happen. (Also gave a really nice shout-out to Denny Cherry, who had to miss the Summit due to a medical emergency.) Now, go learn how to do it at Summit! See you around this week.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
Thank you for doing this.
Orlando – you’re welcome!
I cannot thank you enough, Brent, for this excellent summary, received for free, in the comfort of my office desk!
I appreciated the objective update and insight on Azure and many other buzz topics … a lot of hype crap demystified here 🙂
For those like myself, who cannot afford being at SQL PASS, this is the place to get your daily updates!
For a moment, I almost felt like being there 🙂
Radu – you’re welcome! My pleasure.