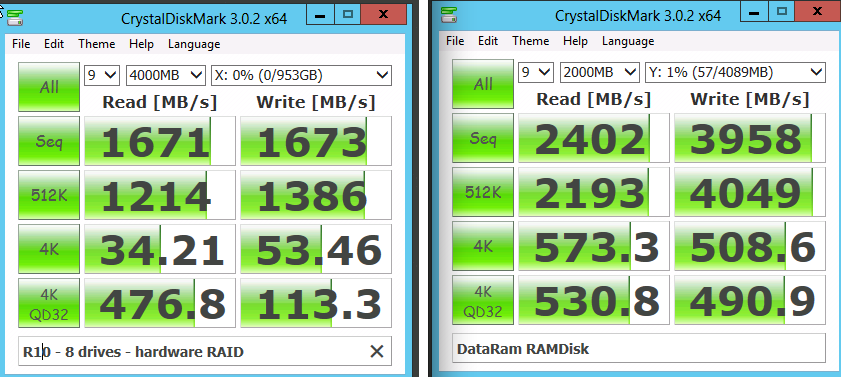
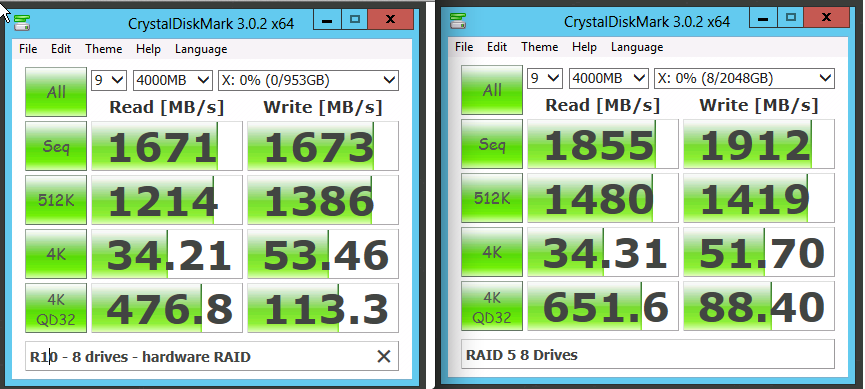
The Network and the Update
17 Comments
We work with SQL Server every day, happily sending and receiving millions of packets of data across the network. Have you stopped to think about what happens when something goes wrong?
The Situation
It’s a regular Tuesday afternoon. Users are happily submitting orders into the shopping cart. After browsing around the website for a while, the users decide that it’s time to buy something. After clicking “Check out now”, the user goes through the check out process, enters their payment information, and then clicks “Buy some stuff!” A few milliseconds later, they get a message that their order was successful and everything is zipping over to their house.
It’s something that we do every day, right? Heck, it’s simple enough that I drew a little diagram:
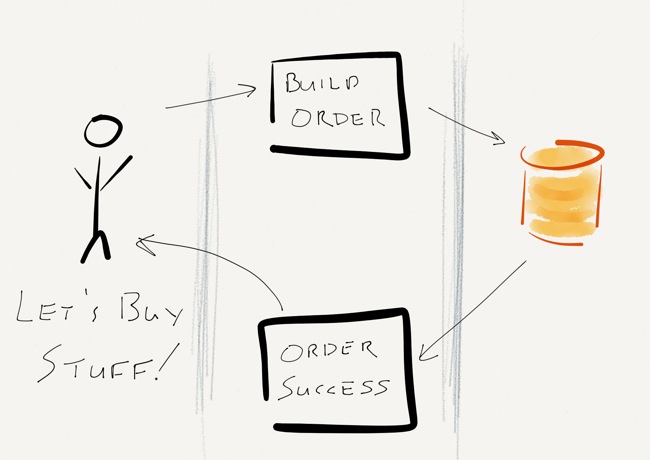
The Problem
What happens when something goes wrong?
There are a lot of places where things could go wrong – a browser bug could prevent form submission, the shopping cart application could go down, the ordering system could be down for maintenance, or SQL Server might even crash (but you’ve configured a solid HA system, so that ain’t gonna happen).
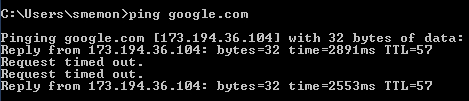
What’s left to fail? The network.
Everything works as it should – the user clicks “Buy some stuff!” and a message is sent to the application servers. The application servers do their magic, approve the credit card, build an order, and save the order in SQL Server. Immediately after SQL Server acknowledges the write and commits the transaction, but before any confirmation is sent to the user, the top of the rack switch power cycles. Randy, the operations intern, accidentally unplugged the power cord before plugging it back in.
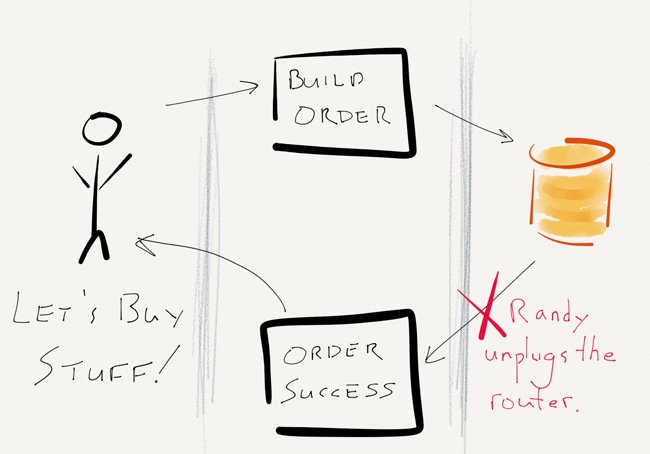
Now What?
This is the part that’s up to you. Sound off in the comments:
- Did the user’s write succeed or fail?
- What does SQL Server think?
- What does the application think?
- Did SQL Server do the right thing?
- What can you do about this sort of thing?
- How can your application handle failures like this?


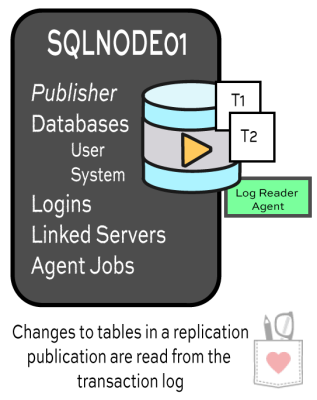

 data to subscribers can be… challenging.
data to subscribers can be… challenging.


 Allen: Board Members set the direction and future vision for the organization. In a more perfect world they might solely be responsible for the strategic direction of the organization much as a typical corporate board of directors is but, because of the unique nature of the organization if a particular director has a passion for how a certain area of PASS should be different they can become quite tactical and put in the actual work to accomplish their goals.
Allen: Board Members set the direction and future vision for the organization. In a more perfect world they might solely be responsible for the strategic direction of the organization much as a typical corporate board of directors is but, because of the unique nature of the organization if a particular director has a passion for how a certain area of PASS should be different they can become quite tactical and put in the actual work to accomplish their goals.