Is Your Code an English Garden or Ikebana?
3 Comments
Erika loves having fresh flowers around the house. Every Saturday morning, I pick up a bouquet at a farmer’s market or grocery store and put it in a vase for her. I’m slowly upping my game by learning more and more about the art of arranging flowers.
When I say flowers, I bet you think about the English Garden style: a big, complex vase with all kinds of flowers crammed into every nook and cranny. It’s an explosion of color and life.

That’s way too stuffy for us. We’re into minimalism, clean lines, and letting materials speak for themselves. I like plucking one or two of the more beautiful or unusual flowers and putting them in their own vase. This leans toward the Ikebana style of Japanese flower arrangement, specifically the Nageire type. (I don’t even want to think about how badly I’m going to mispronounce these if I ever have to say them out loud.)
Writing database code is like arranging flowers.
If you show someone your bouquet, they might not like it. They might give you a million reasons about why it’s not right or why another way is better. That’s not the point – does it produce the results you want?
If your goal is to get to market quickly and cheaply, just buy a premade bouquet from the grocery store, throw the flowers in the vase and be done with it. Use LINQ, Entity Framework, NHibernate, or whatever code tools make your job easy.
If you translate your app code into SQL code, you’re building an English Garden. You start by declaring variables at the center, then populating those variables by checking configuration tables, then spin out to more and more other tables, getting your results in loops and setting values one at a time. This is exactly how developers have always been taught to arrange their flowers, and it works just fine. Once you’re used to doing it, you can bang that code out quickly, and the results are attractive.
But if you need it to be beautifully fast, you need Ikebana. You need very clean, very minimalist code that gets the job done in as few statements as possible. In a database environment, this means set-based code that avoids cursors and loops.
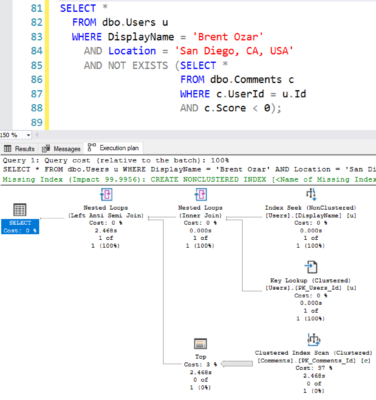
While clean, Ikebana-style database code is simple to behold, it’s deceivingly complex to build. The first step is moving as much logic as possible from the database server to the application server – starting with the ORDER BY statement. If you’re not fetching just the TOP X rows, then do all sorting in the application server. Removing just that one line from a query will often cut its cost dramatically. Your development platform (.NET, Java, Cobol, whatever you kids are using these days) is really good at scaling out CPU and memory-intensive work like sorting, and you’re already really good at splitting out your work into multiple application servers. Leverage that capability.
Think of it like pruning your code – remove all the things that database servers don’t do beautifully, and what you’re left with will be gorgeous.