
When you’re doing DUI operations against tables with millions of rows, you have to be really careful about SQL Server’s estimates. Ideally, you want your delete/update/insert (what – what’d you think I meant?) queries to be as simple as possible – even a simple join can cause SQL Server to do wildly, wildly incorrect estimates, which affects memory grants, parallelism, wide vs narrow plans, and more.
I’ll use the 50GB StackOverflow2013 database, where the Posts table has 17M rows and is 37GB in size. I’m going to put all of the Ids in a duplicate table called PostsStaging:
|
1 2 3 4 5 6 7 8 |
DROP TABLE IF EXISTS dbo.PostsStaging; CREATE TABLE dbo.PostsStaging (Id INT PRIMARY KEY CLUSTERED); GO INSERT INTO dbo.PostsStaging(Id) SELECT Id FROM dbo.Posts; GO |
Just to make it really clear: both tables have exactly the same number of rows, and exactly the same Id column contents.
When stats are up to date,
the estimates are great.
I’ve given SQL Server every possible advantage to make sure we’re dealing with known quantities here – heck, I’ll even go to SQL Server 2019 compatibility level, and update my statistics with fullscan:
|
1 2 3 4 5 |
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150; /* 2019 */ GO UPDATE STATISTICS dbo.PostsStaging WITH FULLSCAN; UPDATE STATISTICS dbo.Posts WITH FULLSCAN; GO |
Now, let’s have SQL Server join between those two tables and estimate how many rows are going to be affected. I’m only going to get the estimated plans here, not the actual, because I don’t want to delete rows yet:
|
1 2 3 4 5 6 7 |
/* All rows should match */ DELETE dbo.Posts WHERE Id IN (SELECT Id FROM dbo.PostsArchive); /* No rows should match */ DELETE dbo.Posts WHERE Id NOT IN (SELECT Id FROM dbo.PostsArchive); |
The estimated plans fill me with delight and joy. The first query, where all rows match, SQL Server accurately estimates that 17M rows will be deleted:

And in the second plan, where no rows should match, SQL Server still conservatively estimates that 1 row will match, just in case:

Woohoo! Beautiful execution plans that perfectly reflect the amount of work that’s going to happen.
Even without fullscan statistics,
estimates are still pretty good.
Let’s update statistics again, but this time let’s let SQL Server pick the sampling percentage:
|
1 2 3 4 5 |
/* Update stats again, this time with the default sampling: */ UPDATE STATISTICS dbo.PostsStaging; UPDATE STATISTICS dbo.Posts; GO DBCC SHOW_STATISTICS('dbo.PostsStaging', 'PK__PostsSta__3214EC07B17D60E3') |
On the PostsStaging table, for example, SQL Server chose to sample less than 1M of the 17M rows:

This less-detailed statistics mean our delete queries’ estimates are still vaguely accurate, but not as quite as they were before. In the first query, where all rows should match, we used to get an estimate of 17,142,200:
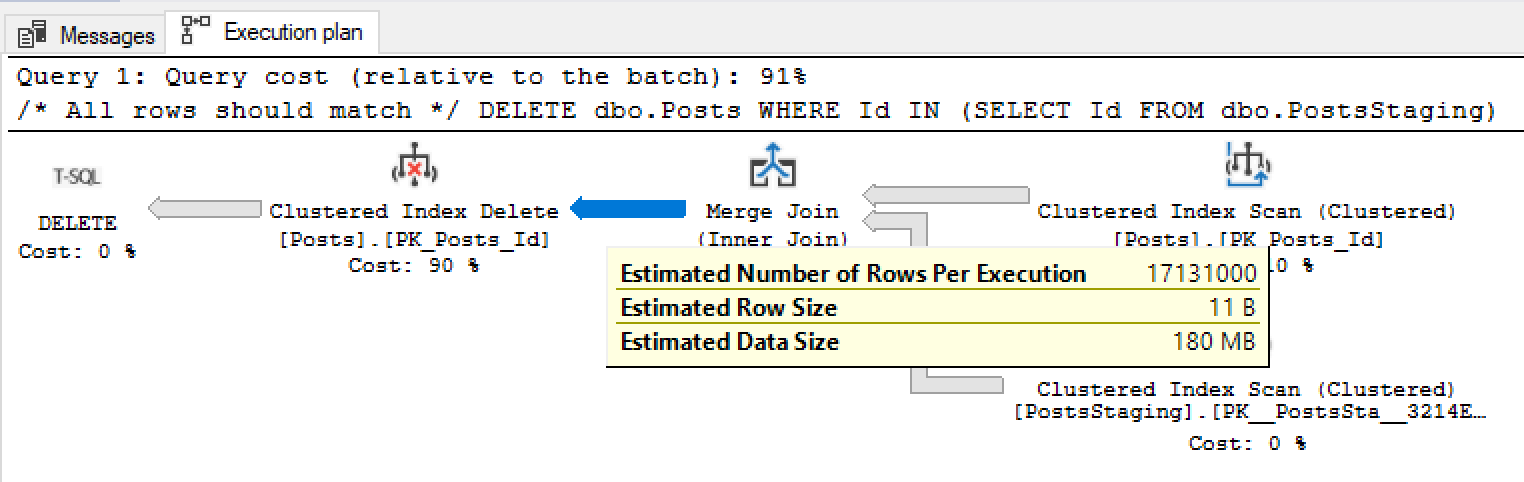
But now our estimate has lowered by 11,200 rows. SQL Server thinks 11,200 rows will still be left in the table. If you’re really deleting all of the rows in the table, this slight variance just wouldn’t be a big deal at all – but check out the second query, where no rows should match:
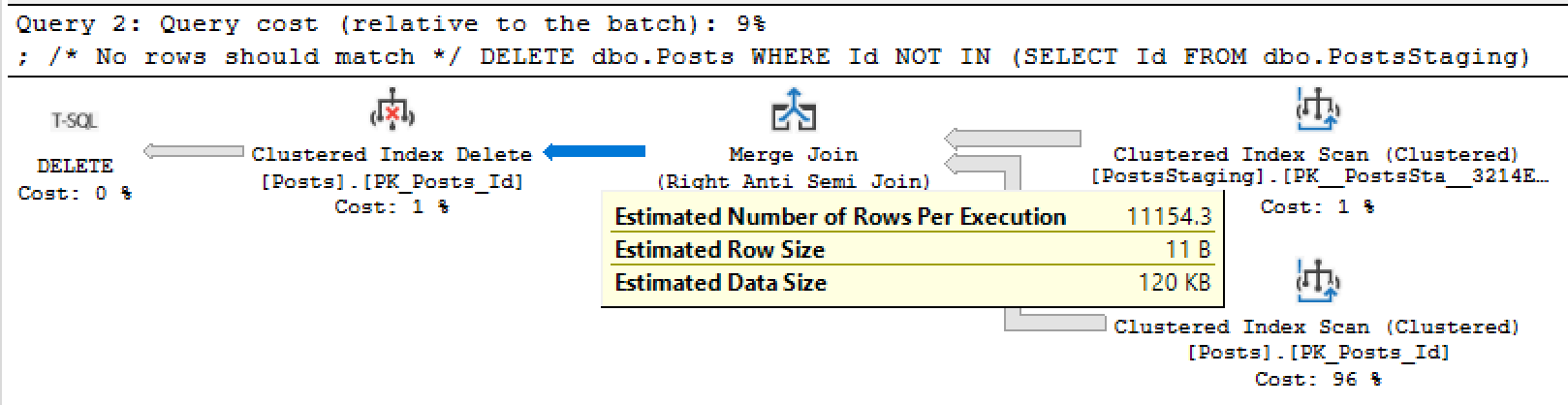
Previously, SQL Server estimated 1 row, but now it’s estimating 11,154 rows. Not bad! I’ll take it – when the data’s absolutely identical between the two tables, SQL Server stands a pretty good chance.
But that’s not how your real world data works, is it? Your tables are probably different.
Let’s show the other extreme:
no overlap between two tables.
I’m going to delete all odd-numbered Posts, and all even-numbered PostsStaging rows, and even throw SQL Server a bone by updating statistics right after our deletes finish:
|
1 2 3 4 5 6 7 8 9 10 |
DELETE dbo.Posts WHERE Id % 2 = 1; GO DELETE dbo.PostsStaging WHERE Id % 2 = 0; GO /* And give SQL Server its best chance: */ UPDATE STATISTICS dbo.PostsStaging WITH FULLSCAN; UPDATE STATISTICS dbo.Posts WITH FULLSCAN; GO |
Just to show you the proof of what’s in the tables, and that there is zero overlap:
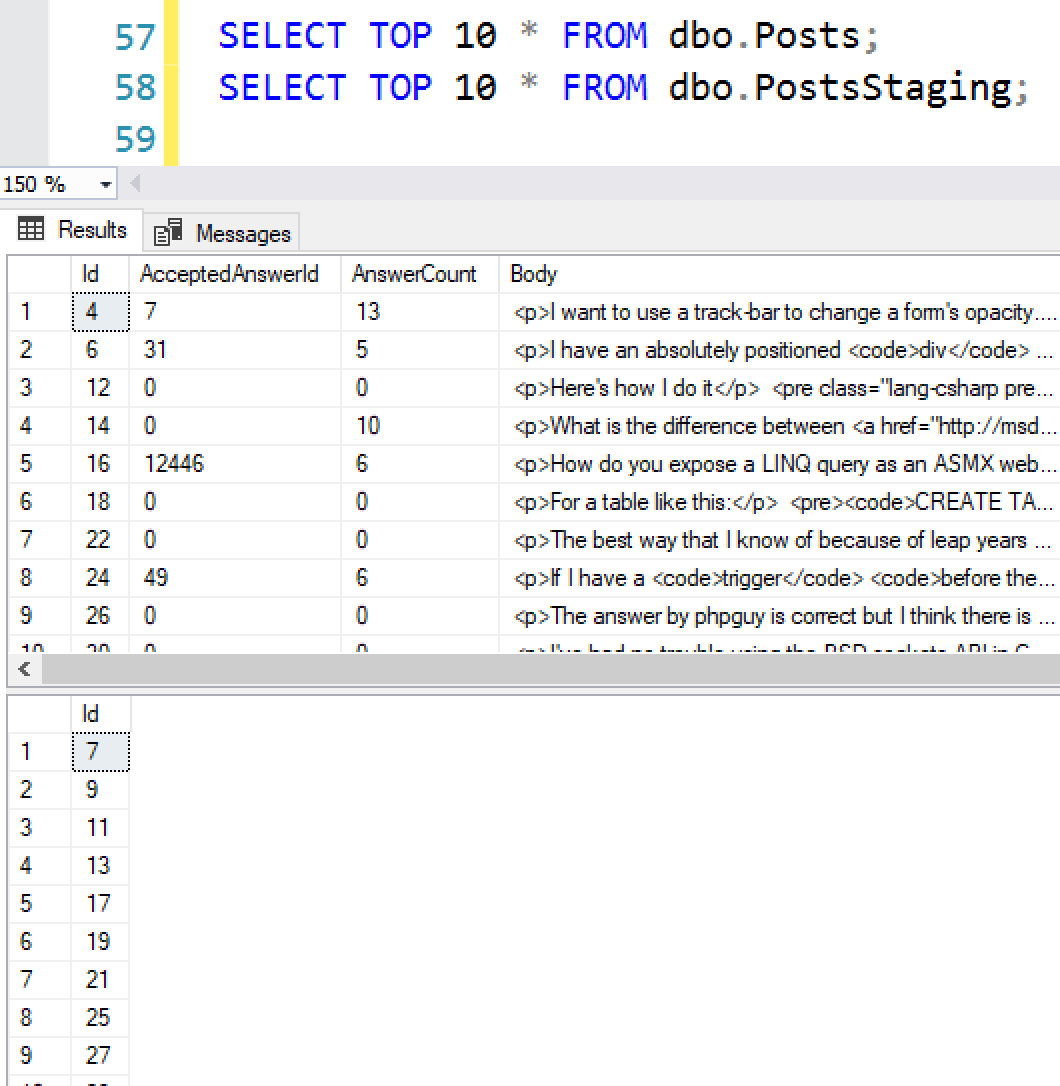
The Posts are all even-numbered, and the PostsStaging are all odd-numbered. There are no rows that overlap at all:

Now, estimates are terrrrrrible.
Absolutely no rows will be deleted by this query:
|
1 2 |
DELETE dbo.Posts WHERE Id IN (SELECT Id FROM dbo.PostsStaging); |
But the estimated plan tells a wildly different tale:
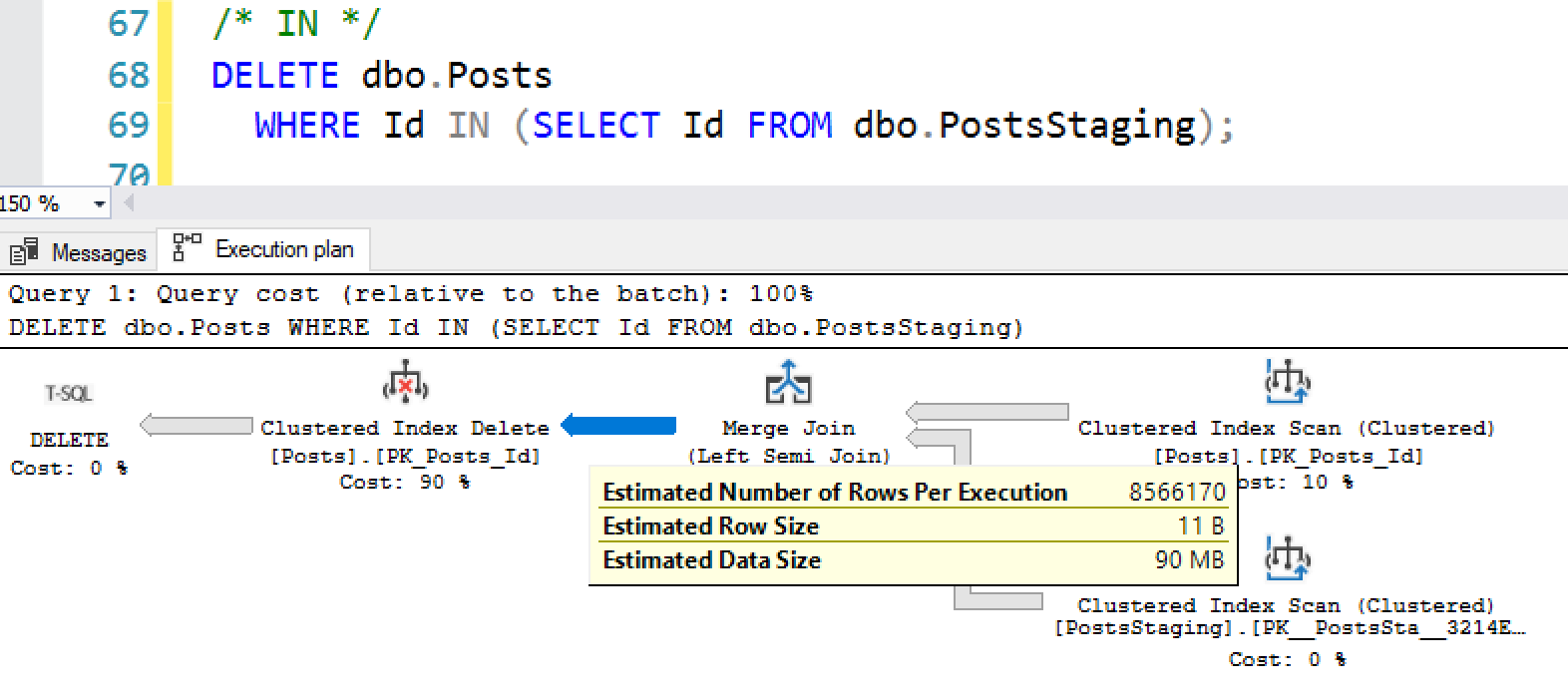
SQL Server believes that half of the Posts rows will be deleted.
And then if we try NOT IN – where all of the rows will actually be deleted:
|
1 2 |
DELETE dbo.Posts WHERE Id NOT IN (SELECT Id FROM dbo.PostsStaging); |
The estimates are completely wacko again:
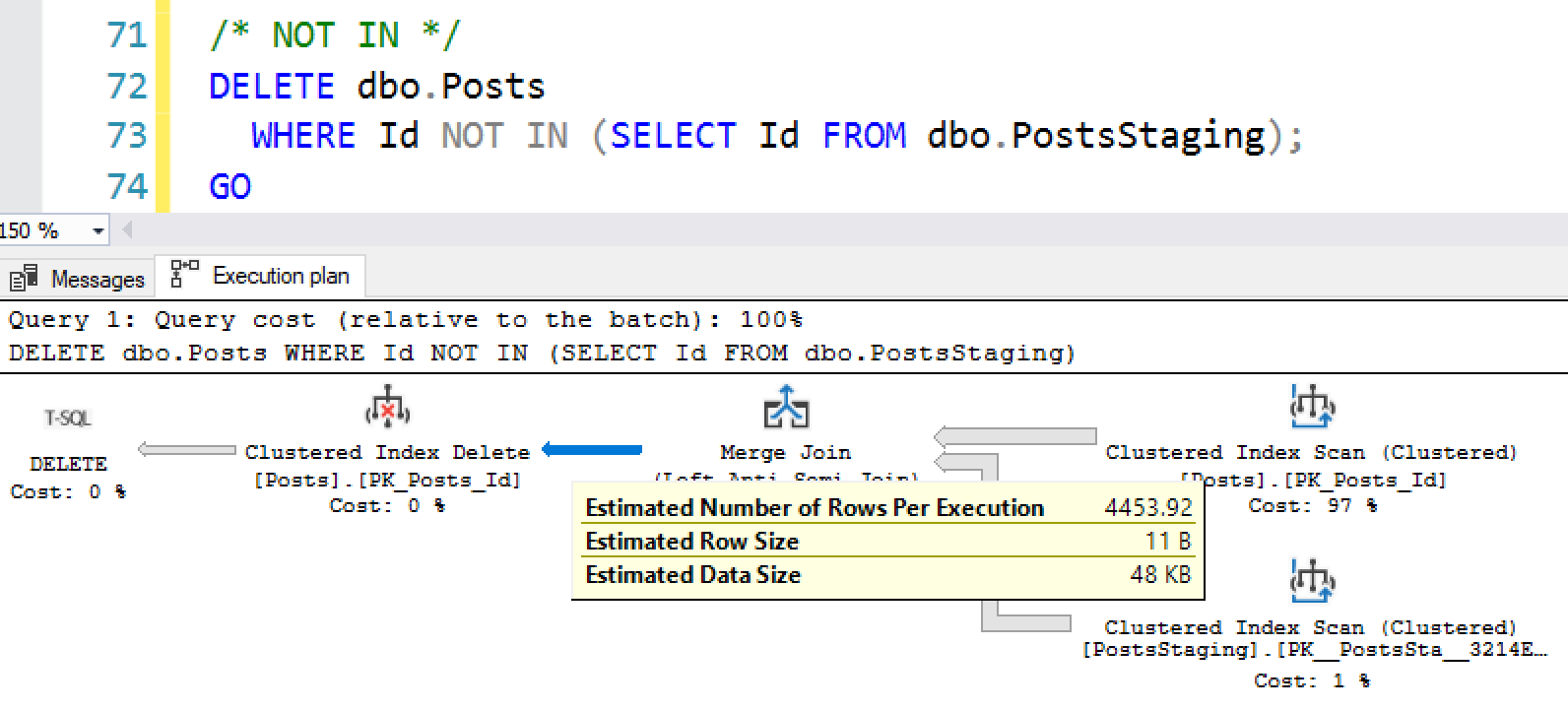
SQL Server believes only 4,454 rows will be deleted, when in actuality we’re going to delete all 17M rows!
How do we get better estimates?
By doing work ahead of time.
If you do DUI operations that join tables together, then SQL Server has to choose all of these before your query even starts executing:
- The number of CPU cores to allocate to the query
- How much memory to grant
- Whether to take out an exclusive lock on the table(s) involved
- Whether to use a narrow or wide modification plan
And at the time it makes all these decisions, all it has to rely on are its crappy estimates.
To improve your odds of getting an execution plan that reflects the amount of work that actually needs to be done, pre-bake as much of the work ahead of time as you can. In our case, breaking up the work might look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/* Get a list of the Ids that need to be deleted: */ CREATE TABLE #PostsToDelete (Id INT PRIMARY KEY CLUSTERED); INSERT INTO #PostsToDelete (Id) SELECT p.Id FROM dbo.Posts p INNER JOIN dbo.PostsStaging ps ON p.Id = ps.Id; /* Only run the delete if rows were found */ IF EXISTS(SELECT * FROM #PostsToDelete) BEGIN BEGIN TRAN DELETE dbo.Posts WHERE Id IN (SELECT ptd.Id FROM #PostsToDelete ptd); COMMIT END; |
You might be thinking, “But Brent, we still have to do all the join work in that first insert into the temp table, and SQL Server’s estimates will be terrible! All we did is move a crappy estimate from one place to another!”
To which I would respond, “Yes, but now, we don’t need an exclusive lock against the Posts table if we’re not going to actually delete any rows. In the single-query method, SQL Server takes out an exclusive (X) lock on Posts as soon as the delete starts – and that makes Mr. End User very sad.”
In my simplistic example here, it might seem like a lot of overkill. However, I’ve seen modification queries that look more like this:
|
1 2 3 4 5 6 7 8 9 |
DELETE p FROM dbo.Posts p INNER JOIN dbo.Users u ON p.OwnerUserId = u.Id INNER JOIN dbo.Votes v ON p.Id = v.PostId AND v.VoteTypeId = 12 /* spam */ LEFT OUTER JOIN dbo.PostsStaging ps ON p.Id = ps.Id LEFT OUTER JOIN dbo.Comments c ON p.Id = c.PostId WHERE ps.Id IS NOT NULL /* delete rows that have left staging */ AND c.Id IS NULL /* don't delete rows with comments */ AND u.Location = 'Antarctica' /* business rule only affects icy people */ |
And there’s just flat out no way SQL Server can predict exactly how many rows are going to match that esoteric combination. Instead, go fetch the list of Ids that need to be deleted ahead of time into a temp table, and SQL Server will do a much better job of allocating the right amount of resources to the query.

4 Comments. Leave new
what happens in these scenarios on (eg) oracle? I don’t think it’s a stupid question, and it’s absolutely not a provocative question
AleD – your best bet there would be to ask someone who uses Oracle. This here blog is about Microsoft SQL Server. Thanks for stopping by!
I’ve run into a situation where the estimates where just way off on a delete in a table which cascades into 23 tables and some of those tables had more than 1 billion of rows!
In the end I had to use query hints in order to make this delete work (LOOP JOIN and FAST 1)
If you want to see the details: https://dba.stackexchange.com/questions/262111/sql-estimates-are-way-off-on-delete-statement-with-triggers-on-huge-tables
Ouch! Yeah, that looks rough alright!