
If Your Trigger Uses UPDATE(), It’s Probably Broken.
In yesterday’s blog post about using triggers to replace computed columns, a lively debate ensued in the comments. A reader posted a trigger that I should use, and I pointed out that their trigger had a bug – and then lots of users replied in saying, “What bug?”
I’ll demonstrate.
We’ll take the Users table in the Stack Overflow database and say the business wants to implement a rule. If someone updates their Location to a new place, we’re going to reset their Reputation back to 0 points.
Here’s the trigger we’ll write:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE OR ALTER TRIGGER dbo.ResetReputation ON dbo.Users AFTER INSERT, UPDATE AS BEGIN /* If they moved locations, reset their reputation. */ IF UPDATE([Location]) UPDATE u SET Reputation = 0 FROM dbo.Users u INNER JOIN inserted i ON u.Id = i.Id; END GO |
That trigger is completely broken because it doesn’t handle multi-row updates correctly.
To see what I mean, let’s look at all of the users named Brent:
|
1 2 |
SELECT Id, DisplayName, Location, Reputation FROM dbo.Users WHERE DisplayName = 'Brent'; |
Some of them have locations set, and some don’t:
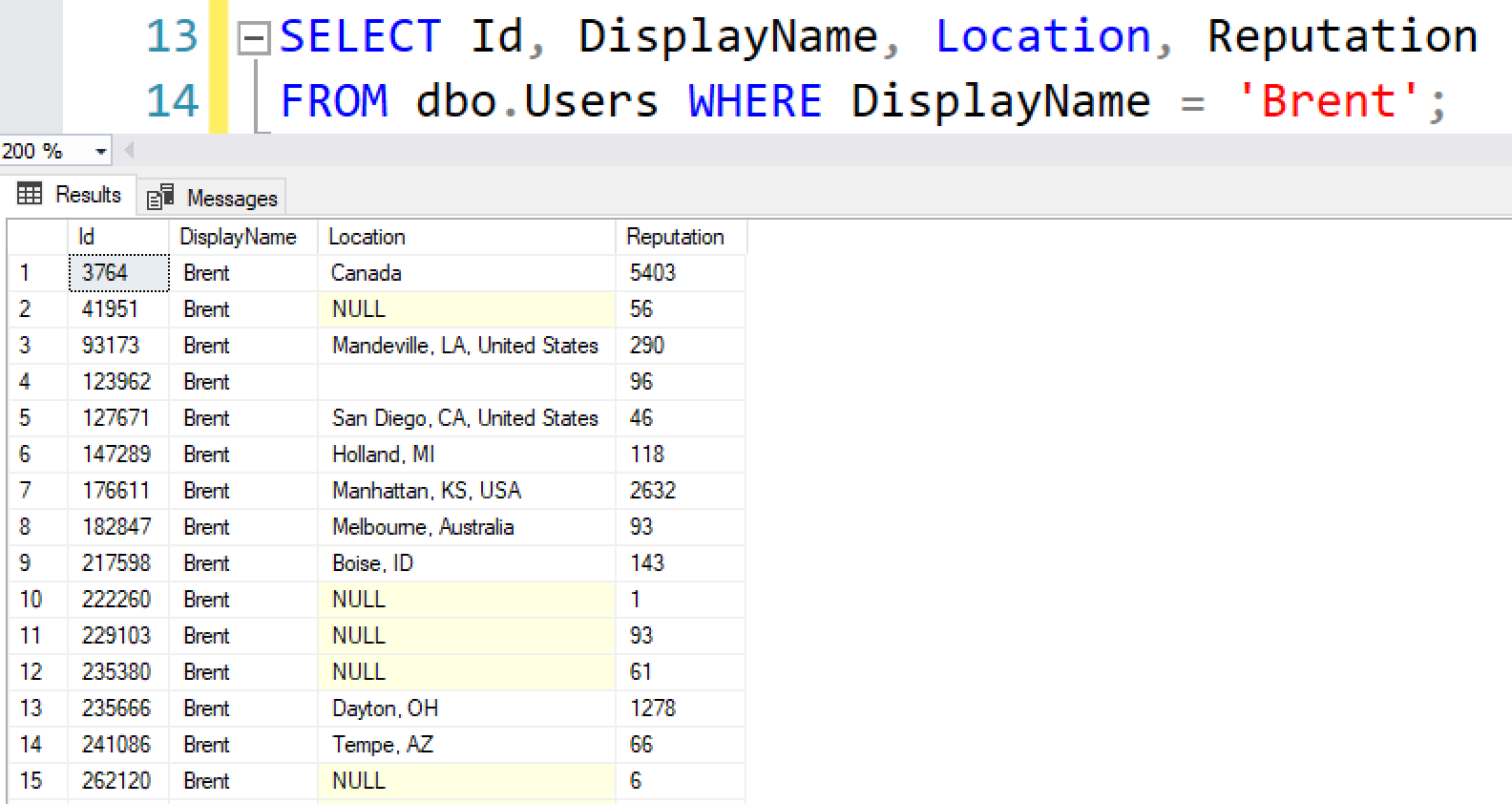
Let’s update the ones with no location, and set it to be ‘Miami’ – it’s a nice place, after all:
|
1 2 3 |
UPDATE dbo.Users SET Location = COALESCE(Location, 'Miami') WHERE DisplayName = 'Brent'; |
And now check their location & reputation again:

UH OH. Everyone’s Reputation was reset, even people who didn’t change Locations.
Now, you might be saying, “That’s because you changed the Location using a COALESCE.” Nope – let’s check Richies:
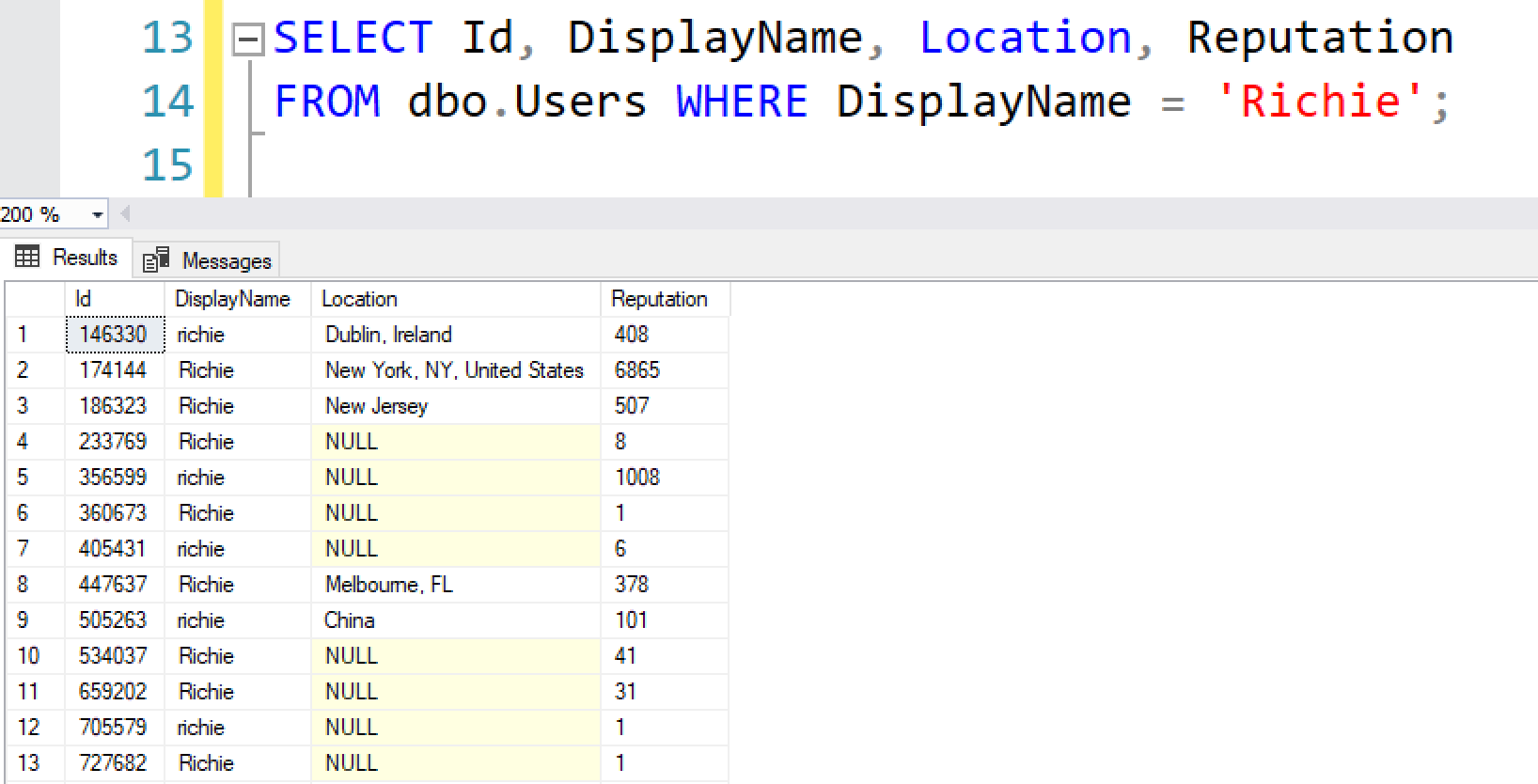
And use a different UPDATE;
|
1 2 3 |
UPDATE dbo.Users SET Location = CASE WHEN Location IS NULL THEN 'Miami' ELSE Location END WHERE DisplayName = 'Richie'; |
And they all get reset:
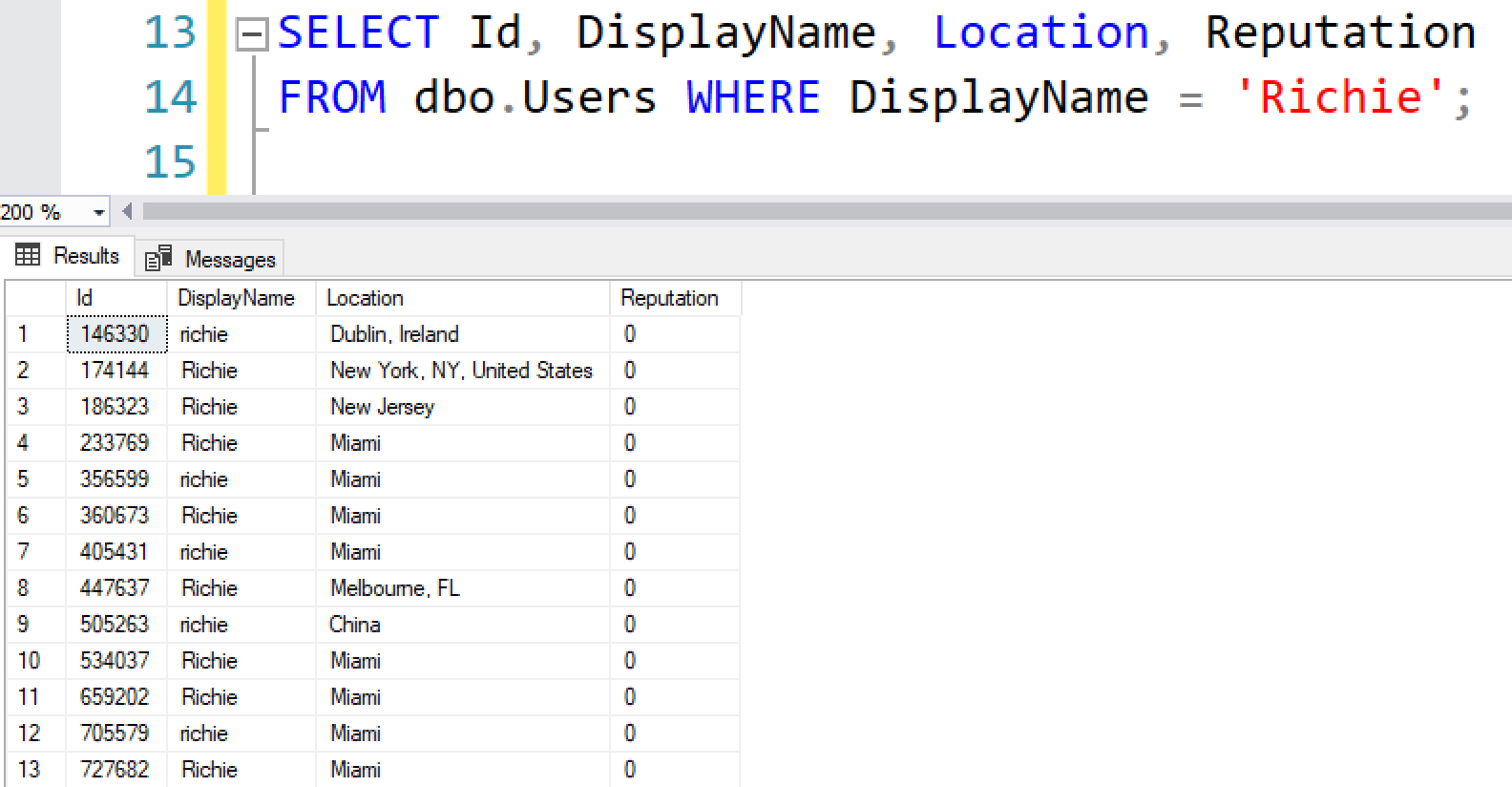
You can’t just blindly use UPDATE().
Because sooner or later, somebody’s going to do a multi-row update that affects some of the result set and not others, and your trigger will hit everything in the inserted table.
It’s up to you to figure out specifically which rows you need to process, and what you need to do to ’em.
If you think the query is the problem, watch this module of Mastering Query Tuning where I give an example of a good query, properly written, that *has* to work this way, and the trigger will fail.

96 Comments. Leave new
Still a bug in your code. COALESCE(Location,’Miami’) == CASE WHEN Location IS NULL THEN ” ELSE Location END. You wrote the same code twice, and it’s that code that does not work with a trigger which uses UPDATE()
Better code to use with a trigger that uses UPDATE() is:
UPDATE dbo.Users
SET Location = ‘Miami’
WHERE DisplayName = ‘Brent’ AND Location IS NULL;
The misconception here is that UPDATE() is supposed to tell you when a column value has been altered. It doesn’t. It tells you when a column has been the target of an UPDATE, EVEN IF THAT UPDATE IS TO THE SAME VALUE.
The better code filters the ROWS to be updated so that it’s not touching Location in rows where it doesn’t need to.
The trigger with UPDATE() is then useful because other code which doesn’t alter Location won’t run the bulk of the trigger’s code.
This is still a good message because you need to be AWARE of the code in use when writing triggers, and of the triggers in use when writing the code, but it’s not a bug in UPDATE().
And a bug in my comment.
COALESCE(Location,’Miami’) == CASE WHEN Location IS NULL THEN ” ELSE Location END
s/b
COALESCE(Location,’Miami’) == CASE WHEN Location IS NULL THEN ‘Miami’ ELSE Location END
Steven – I strongly, vehemently disagree.
When you write update queries, you can’t be expected to know what triggers will be later added (or are already present in the table.) Organizations often add triggers to third party apps to do things like change tracking or auditing.
The trigger needs to correctly handle queries – not the other way around.
Any code needs to be tested in its environment. This goes for both application SQL and trigger SQL.
Awareness is necessary for any developer:
1. The Application SQL developer needs to know what triggers currently exist, and how their code will interact with them.
2. The Trigger developer needs to know what SQL Code exists, and how their code will interact with it.
3. The Trigger developer also needs to know what UPDATE() is DESIGNED to do.
Your description of UPDATE() and your use of it in this scenario shows that you were NOT aware of what UPDATE() is designed to do. It’s designed to identify the target columns of an update, NOT whether or not those columns had their data changed.
You may argue that this is a DESIGN FLAW, and I won’t entirely* disagree with you, but it’s not a BUG, and since the design is clearly documented (https://docs.microsoft.com/en-us/sql/t-sql/functions/update-trigger-functions-transact-sql?view=sql-server-ver15) I can only conclude that you were unaware of the design.
* UPDATE would be much more useful if it efficiently determined if the value was CHANGED. However, my guess is that it can’t be done efficiently (and what would you return for multiple-row results anyway?). Maybe an updated() function at the row level, but that would probably be no more efficient than joining INSERTED to DELETED and comparing the value anyway.
HAHAHAHA
HAHAHAHAHAHAHAHA
HAHAHAHAHAHAHAHAHAHAHAHA
I would keep reading but I’m going to need to take a nap from all this laughing. Thanks for the comic relief, Steven.
This response just made my day. I always love that you’re in sync with reality, Brent. Thank you!
Jason – hahaha, thanks!
Everyone has a test environment.
Some of us are lucky enough to have a separate production environment.
Hi Brent, if you update the column value only in 1 of the N rows updated by the SQL,
what value should have the “UPDATED()”? what should be the content on the “inserted” table?
I personally agree with Steven, UPDATE() is only a “global” information that you’re hitting that column, not that you changed that value inside one/some of the rows. Now I’m worried about reaction about this comment.
The behavior of UPDATED() needs to be noted, however your UPDATE statements are a more basic bad-practice. Its simple: ALWAYS filter your where clauses to ONLY AFFECT/RETURN THE ROWS YOU NEED. That’s Data Access Law #1. If I caught someone in my environment running wide UPDATEs and using either Coalesce or a Case Statement like you did here, I would have their access revoked. Anyone touching a prod database or developing code for one should know better and if they don’t that’s why we all have jobs. 😉
Brent, Steven is 100% correct in this case… the Update statement should only Update the fields that need to be changed. This is unrelated to the UPDATED() function, just to general good programming practice.
Why would you update the fields that already have the Location set correctly ?
Even without Trigger issues, SQL will be doing extra updates and there will be more transaction logs as a result and the number of updates done will not match the number of changes made.
Any Update statement should include criteria determining which records are being changed. This is simply good programming practice.
There are times when you need to update multiple fields and, in this case, the number of records which have field 1 updated may differ from the number with field 2 being updated, even though it is necessary or more efficient to use a single Update statement to perform them both.
In this case, the criteria for the update should include both of the fields with an OR condition – we will know the total number of records updated without knowing how many of each update were done. But we still wouldn’t update any record that did not need to be updated.
Update statements are perfectly allowed to do non-updating updates. For example, think code that issues updates without knowing if columns have been changed by other sessions.
They are ALLOWED to do non-updating updates, but people are also allowed to fart loudly in an elevator. That doesn’t make it good policy !
Indeed, I would argue that best programming practice would be to reject an update if the column HAD been changed by another session since we do not know which update was the “correct” one. And that is IF the second update was actually a real update.
But, if the second update is setting the field back to its original value because you are making updates to data that you haven’t changed, you are erasing a genuine change.
How is this a good thing to do ?!?
If only everything were built according to best practices. That would be pretty awesome.
BWAAAA-HAAAA-HAAA!!! While I agree that things should be done the “right way”, I’ve found that what people call “Best Practices” is frequently the wrong way. Here’s my “Dirty Dozen” list (It’s actually a “Baker’s Dozen) of supposed “Best Practices” that have long been and continue to be touted as “Best Practices” that are actually “WORST Practices”. You’ll have a real appreciation for some of these, Brent, because you know a lot (if not all) of these . 😀
1. Replacing Cursors with While loops.
2. Replacing While loops with incremental rCTEs. (A well written While loop will easily beat them and use 1/8th the amount of resources)
3. Index Maintenance that follows the rules of Reorganize between 5 and 30% logical fragmentation and Rebuild above 30%. (People REALLY need to read footnote #1 of that “recommendation” in the documentation!)
4. Using Reorganize in general. (No… although it’s correctly documented, it doesn’t actually work the way most people think it does).
5. Using Rebuild with the Online option (Better than Reorganize but you have bigger issues if you think you have to use it).
6. Avoiding the use of GUIDs only because of supposed fragmentation problems and memory waste. (It’s actually the use of Reorganize that causes these issues and Random GUIDs are actually 2nd best at avoiding fragmentation for weeks and months!)
7. Partitioning as a panacea for better query performance. (BWAAAA-HAAAAA-HAAAA!!!! ‘Nuff said!)
8. Lowering the Fill Factor of fragmented indexes as a panacea to reduce or avoid fragmentation (it usually doesn’t help at all and wastes tons of memory… you have to fix the underlying cause of the fragmentation, which is usually “ExpAnsive” updates).
9. Not documenting code because you can just “read the code”.
10. Believing in row LOBs have any benefit and (it’s near cousin) believing that it’s ok to use large variable width columns because they’ll go out of row if they need to.
11. Denormalizing for “performance”.
12. Thinking that Knuth’s parable concerning “pre-optimization” means you can ignore datatype right-sizing, etc, etc.
13. Avoiding extended/proprietary features of an RDBMS because you believe in the myth of easily migratable code.
Jeff – I am laughing, but at the same time I’m moaning, because I literally just finished the first call with my weekend emergency client and we hit about half of those. (sigh)
The good part for you is that you don’t have to fix things for free. I would have to because I’m an FTE (and, yeah… I’m a poet and don’t know it) 😀
Brent– I strongly, vehemently disagree. Steven, Simon, and Grasshopper have the right idea on this one.
The update queries you use to demonstrate this bug are the source of the bug. Any update that can factor down to “UPDATE Table SET Column1 = Column1;” for some portion of the targeted rowset is objectively bad and smells to high heaven. Based on the example queries, *THAT* is what this article should have been written about. (Maybe a better example where the updates aren’t objectively bad is in order?)
I don’t understand how lack of a concurrency strategy is a valid excuse here, either. If you were properly filtering by WHERE Location != @NewLocation (handle NULL however you want, not the point) any records that have already been updated to the new location would not be included in the set and would not have their rep reset.
You have highlighted an important issue, though. The function of UPDATE() may not be obvious and clearly is misunderstood by some.
Sorry, the UPDATE statements are completely valid. They’re legit T-SQL, and they work fine.
It’s only the trigger that breaks in this case: their query worked fine before the trigger, and would work fine if the trigger was removed.
The trigger has to be written to handle all valid update statements, full stop.
The valid syntax of the UPDATE is irrelevant. Yes, it is valid. Yes, it does indeed do what it is written to do: something that is an objectively bad practice. If proper syntax prevented us from authoring bad code we wouldn’t have static analysis, TDD, or the concept of code smells in the first place.
By your logic the example trigger is also entirely valid. Totally legit T-SQL and works just fine. Doesn’t throw or otherwise fail ungracefully. It is doing exactly what one should expect it to do on inspection given they understand the features in use.
I suspect the problem here is with failing to call out the intention of the trigger author. If the author intends some conditional behavior in a situation where DML could SET [ColumnN] = [ColumnN] (even though it shouldn’t) then yes, the author needs to do more than just check UPDATE(). If this business rule isn’t stated up front it can’t be known the intention wasn’t captured by the script given. (Couldn’t there be cases in other examples where SETting [ColN] = [ColN] *is* intended to effect UPDATE()ed rows that haven’t actually been changed? Yes, of course there could be.)
Using bad UPDATE examples gives the appearance that the change in trigger logic is a preventative measure against bad UPDATEs rather than fixing a failure to implement a business rule due to misunderstanding how UPDATE() works. These are two separate issues and conflating them has muddied the waters a bit.
Okay, you lost me when you said valid syntax is irrelevant. We’re going to have to agree to disagree. Thanks for stopping by.
This comment is SO wrong, but Brent already said that.
I think the last comment was about that IF UPDATE([Location]) condition can increase the speed of your trigger. If you add it, the triger will not be called at all if Location is not presented in the UPDATE statement(for example you change a display name for many users)
PS: why screenshots are from SSMS, the latest trend is to use Azure Data Studio
Denis – interesting, so you think that the trigger won’t have to evaluate whether the locations were changed in order to run? Interesting.
if they want to implement a business rule “If someone updates their Location to a new place, we’re going to reset their Reputation back to 0 points.”, you need to adjust the text of your trigger, currently it just check that Location is presened in UPDATE.
So the final ‘proper’ implementation should contains both:
1) IF UPDATE(LOCATION) condition – it removes some unnessesary checks and selects
2) check that the value actually changed
That is how I see it
Denis – exactly, now you’ve gotten the point of the post. Good!
That’s also what we do – a combination of checking UPDATE and then comparing rows in the inserted and deleted tables to see what has *actually* changed, if anything.
You can just add
“and inserted.location != users.location”
inside join and this would filter out rows that have not changed their values.
“You can just fix the bug and then it doesn’t have a bug”
Correct. Congratulations, you win a prize!
mmmh… location is nullable…
AND ISNULL(inserted.Location, ”) ISNULL(users.Location, ”) ?
No, that’s bad practice also. Try:
AND EXISTS (SELECT inserted.location EXCEPT deleted.location)
Paul White documents this:
https://www.sql.kiwi/2011/06/undocumented-query-plans-equality-comparisons.html
One of my bosses wrote a trigger with exactly this defect. As a result, invoices for years were created incomplete,, missing line items.
The cost to the company over the decade of the use of this trigger code is staggering, likely in the millions. Of course when I disovered it ,explained the problem and corrected the trigger, the consequences of it’s existence for a decade were concealed. No higher ups ever learned about it 🙂
You’re not alone in that scenario.
There is a golden rule where I work, which is “no one touches anything to do with invoicing if you can possibly avoid it” 😀
Hi Brent,
Well, it depends whether you read and understood the documentation correctly.
You could well rename your post “If your trigger uses UPDATE(), and you also misunderstood what the UPDATE() function does, then it’s probably broken.”
You could well replace UPDATE() in the above statement by anything else.
Ben
Benjamin – yes, if you read the documentation, understood it, and remembered it, you’re good.
How does that work out for you in your organization? Does everyone read the documentation, understand it, and remember it?
And if so, are you hiring? I suspect a lot of folks might be interested in applying.
Heh… my turn, Brent…
“How does that work out for you in your organization? Does everyone read the documentation, understand it, and remember it?”
BWAAAAA-HAAAAA-HAAAAA-HAAAA!!! HOOOOOOOOOOOOIIEEEEEEE!!!
You almost killed me with that one! 😀 😀 😀
No no, what I meant was that, by reading your post, it feels like the UPDATE() function should always be avoided. I have seen situations where the use of the UPDATE() function has been very handy. If I remember correctly, it was used as a switch within a trigger: if a column is part of the update statement (e.g. “where dummy=1”), then the trigger would run otherwise it wouldn’t do anything and just exit. Of course you need to know how the trigger is designed, but then if you add a “dummy=1” to an update where clause, then you knew the trigger wouldn’t execute.
So the INSERTED table within the query has extraneous columns because the update statement didn’t include ‘and Location is null’..
So the trigger has a bug because an update statement can update items that do not update. Which is corrected by the comment above in the trigger..
that would be nasty to track down.
Daryl – that was just a simple example of an update statement that doesn’t update every field in every row that it touches. In the real world, update statements are a lot more complex than that. I don’t reproduce full blown real world queries in every blog post. Hope that’s fair.
“an update statement can update items that do not update”
More correctly, an update statement will update records whose values do not change.
Take Brent’s original trigger code, then run “UPDATE Users SET Location = Location” – ALL rows in the table are UPDATED (because there’s no WHERE clause) but no record has its VALUE for Location CHANGED. In the trigger, IF UPDATE(Location) returns True because the column is in the UPDATE statement, and the trigger code sets the Reputation to 0 for ALL the records in the table. Because all the rows are in the Inserted magic table, because the UPDATE is running against all rows, because there’s no WHERE clause, even though the SQL LOOKS like it doesn’t “change” anything. The “records affected” of the UPDATE will be the row count of the table.
Think of it this way – UPDATE() checks the statement, not the data.
9/10 People don’t want the result of the UPDATE() function. What they want the trigger to operate on is if the value changed, not if the row was updated. You get that by comparing inserted to deleted.
The UPDATE function is a trap in and of itself. Testing to see if value of a column on a given row was the target of an update isn’t the same thing if the requirements were to reset the value if the Location changed.
Many applications take all the values in the form and update the entire record. Even if only a single column changed because most development tools work that way. Otherwise a table with 30 columns would need 30 seperate update stored procs to allow for updating each column. That’s insane.
Mark – bingo, exactly, and most folks don’t know to compare inserted vs deleted, as we saw in the other blog post’s comments as well.
I’m going to have to agree with Brent on this one. I totally understand both sides. however, writing something that requires total knowledge by others that aren’t aware of it is a bad idea. Coming from the mind of the dev, how could rando randy dev know about how the trigger was written and even if they did, how it would affect what they are intending?
Tl;dr
Never assume your devs will write code a certain way. Always account for everything.
I’m never the type to go as far as to disagree…but will venture out and say “maybe I’ve internalized this bug when told to think like SQL Server”, or even say “I have some learning to do”.
Both of Brent’s example update statements should issue an update to each row qualified by the predicate, which is either DisplayName = ‘Brent’ or DisplayName = ‘Richie’. (The COALESCE vs. CASE logic doesn’t change the expected behavior of the update statement, as I understand it – it just changes how the target value is set for each row subject to the update statement.)
So, I’d interpret/expect the inserted virtual table to include all rows that meet the update statement’s predicate…which means all rows with DisplayName = ‘Brent’ or DisplayName = ‘Richie’, depending on which example is used. (Said conversely, I would not expect the inserted table to only include those rows where Location was previously NULL.)
Personally, I vomit in my mouth just a little anytime I’m forced to use a trigger. Because, yuck.
But, here, I’d have written the trigger differently out of the box to account for this possibility, viewing it more as “how SQL Server works” than a bug.
(That said: I totally agree it would be better if the inserted table only referenced data that was, you know, actually changed. But, I’m guessing this bug is more a symptom of how SQL Server handles the originating update calls, particularly when values are not actually being changed in certain rows, and is less about the inserted table itself.)
CREATE OR ALTER TRIGGER dbo.ResetReputation ON dbo.Users
AFTER INSERT, UPDATE AS
BEGIN
/* If they moved locations, reset their reputation. */
IF UPDATE([Location])
UPDATE u
SET Reputation = 0
FROM dbo.Users u
INNER JOIN inserted i ON u.Id = i.Id
LEFT OUTER JOIN deleted d ON u.Id = d.Id
WHERE COALESCE(i.[Location],”) COALESCE(d.[Location],”);
END
GO
Meh, the good ole “escape SQL injection characters” thing removed my “does not equal” sign comparing location values. (:
Scott – yep, it’s easy to fix. It’s just a dang shame I almost always see triggers with the broken version I show in the post – and as I wrote in the post, the very blog post yesterday had folks putting a broken trigger in the comments.
Scott – if the trigger fires on an insert, then your LEFT OUTER JOIN fails to produce a row. Then the WHERE clause is true, as it is a new location. Then your Reputation will be set to zero?
Yup UPDATE() is a rather “blunt” function, but if you understand what it’s telling you, you should be OK.
That most folks don’t know to compare inserted vs deleted is frankly, scary. I suppose I shouldn’t be surprised, Triggers have been getting a bad rep for years. And without widespread adoption and practice, lack of familiarity leads to mistakes.
I think Triggers got a bad rep in the 90’s when we are doing 3-tier design (or often what some people thought was) with things like VB and PowerBuilder. And there was a tendency to put way too much business logic the T-SQL code. Working “close” to the data is powerful and easy, but limiting. We misused or overused some of the tools we had. And the tools got the blame.
Hi Brent,
Just an observation but even without the IF UPDATE(), is this Update trigger example flawed – presumably you’d only want to update Reputation if the location actually changed?
I have some similar code in triggers that use IF UPDATE() but I will always join Inserted & Deleted and check that inserted.Column != deleted.column for this particular type of scenario.
By doing so then without the IF UPDATE(), the trigger code runs on every update on the table and only rows where the Location value is changed get the reputation reset, as you would expect.
By adding the IF UPDATE(), nothing changes – I’m not relying or expecting it to determine which row(s) get updated, but for all updates to the table that don’t include the Reputation column in the list of updated columns, the trigger code is not run – surely that’s a good thing?
I’m always learning so appreciate I might be overlooking something here?
Thanks and really enjoy your blogs 🙂
Stuart – I really wish users would only update values when things change, but that hasn’t been my experience out in the real world.
Ha I remember this from back in.. 2002 or so.. the problem is that UPDATE() is true if the column is in the update statement regardless if the value changes or not You need to do what Artashes proposes but you also need to check for null values.. So this “and inserted.location != users.location” might not be true if the value was null or is being updated to null
I don’t miss these kind of triggers haha
I think we are missing the point that the update statement does update every row.
It sets a new location or the same location to every row. If that was not what the author wanted he neded to add WHERE DisplayName = ‘Brent’ AND Location IS NULL. It is a bug in update, not the trigger code.
Denis – not really. The update statement *doesn’t* update every row, as Paul White shows:
https://www.sql.kiwi/2010/08/the-impact-of-non-updating-updates.html
That a disconnect between the query engine and the storage engine.
You can also see a similar disconnect with Transactions, with the query engine saying that it’s started a transaction and the storage engine (DBCC OPENTRAN I think) denying it.
No, it really *does* update every row — logically. What it does or does not do physically is entirely irrelevant. The “rows affected” message is all you, as a user, need to think about here. It shows the number of rows that were logically impacted, and that includes downstream calls to triggers. So there’s really nothing special happening here, except a lack of understanding about how SQL is supposed to work. I’m not convinced that this “bug” is even remotely common. Not a lot of people use UPDATE() in triggers and despite your laughing elsewhere at the idea of testing, plenty of people do test their stuff. Perhaps you should try it, you might like it.
jfgi – I understand that you haven’t seen it, but *I* have seen it all over the place, thus the blog post. I might get around more than you do, though. 😉
And if you think a lack of understanding about how SQL is supposed to work is something special, again, I’ve got some heartbreakingly bad news for you about the world at large. Stay in that bubble as long as you can, friend.
jfgi, I hope you’re some prodigy coder…because you’ve made a lot of assumptions.
jfgi – I couldn’t agree more… If the UPDATE() function had a different behaviour than it does, I think it would confuse people more than it does today.
even if the value changed to the same it was still a change
is knowledge at the junior dev level
Brent, usually your blog posts makes a lot of sense, but I think you were drunk while writing this one…
The UPDATE() function is mostly useful to skip a section in the trigger if it’s not applicable (ie. the column is not present in the update statement). I have never seen anyone misuse it as if it had row-level smartness, but hey, you do see a lot more code written by others. Just felt I had to elaborate, hence my rude comment above… Love your blog posts by the way!
First of all, i’m not a full-time DB developer… but i ran into this problem awhile back where i didn’t want the trigger replacing data with the same data. Seemed a waste of CPU. I replaced it with this.
IF EXISTS(
SELECT * FROM inserted
EXCEPT
select * from deleted
)
Are you saying that the update() function is completely not necessary in practice if used with something like the above snippet? I mean, you raise a good point, i don’t see how it’s relevant if we have already determined something is already being updated, but maybe there is something i can’t think of…???
btw, that snippet solved a different problem at the time. I found it online and not taking credit.
That’s kinda creepy but thanks for the feedback. ?
?haha
HA! No creepiness intended – that’s Trixie Mattel, and I love her to death.
Maybe what you’re really demonstrating here is a failure of arriving at an implementation that accurately represents the intention… Case in point: that’s legit creepy AF.
That trigger doesn’t even necessarily handle single row updates the way you want. If you have an SP to handle when someone changes some details, you might have code that looks a bit like this:
UPDATE dbo.Users
SET
DisplayName = @DisplayName
, Location = @Location
WHERE Id = @Id
Now the trigger fires for every user that changed their display name.
I’d probably not call it a bug though, because by itself it doesn’t mean the app behaves incorrectly. I think it becomes a bug once there’s one of those update statements in the code, but until then it’s more like a trap for future developers. That’s just semantics though, it’s definitely something to be avoided.
As mentioned above, the issue is not with the UPDATE().
It’s just that whoever wrote the trigger should be put on the naughty list and lose their keyboard privileges until the release of SQL 2025, which is going to have built-in stupidity control.
A trigger, or any piece of code for that matter, is supposed to handle whatever input is thrown at it and apply its designated business logic to that input.
This trigger fails in that regard.
Adi – yep, agreed. I sure do wish everyone knew how to use SQL Server correctly.
But they don’t – and that’s why I blog.
Thanks for stopping by!
I use UPDATE() all over my DB for perf reasons, it has a ton of triggers for logging tables and denormalizations, some of these are nested. Obviously as everyone mentions, I also check inserted vs deleted.
I found the perf benefit is effectively not having to run the statement at all, ergo not going through the various processes of running that statement like statistics lookup etc, and also not firing the nested triggers.
The one thing annoying with it is it doesn’t work in delete triggers, it just returns false. So you can’t generalize triggers.
The trigger isn’t broken, the T-SQL statement is. Update() is doing exactly what you are telling it to. It doesn’t care that you are setting the value of location to itself; you are making an update to all of those rows.
The statement from the engine’s point of view does not do this: “Let’s update the ones with no location, and set it to be ‘Miami’ ” The statement is updating ALL of the rows limited by the where clause.
Just look at the “number of rows affected” messages on the update. I’m betting it matches your select statement.
ISNULL() and COALESCE() are not substitutes for proper filters in WHERE clauses.
did not see this exactly in above comments .. but to make the trigger code multi-Row aware ….
If Update(col1) ..
only confirms if at least one row was updated ….
( could have been changed even to the exact same value ) ……
so within if update(col1) … need to check EACH row … if the value ACTUALLY CHANGED on that row from deleted value to inserted value
if update(col1)
BEGIN
if inserted.col1 deleted.col1
begin ………..
end
END
I don’t see the problem here.
The documentation says that UPDATE() operates on the set, not the individual rows.
If the column in the UPDATE() at all is part of the UPDATE command, the UPDATE() function will be true for all rows in the inserted/deleted virtual tables.
You may need to read through the post again more slowly, paying more attention to the demo code this time.
The trigger isn’t broken, it did exactly what it was told to do, it updated every record, and therefore, updated the reputation. Regardless if you the location changed, you updated the record with the same value, hence you updated the record. You should write the update statement to only affect the row that need updated, and not every row in the table.
Ah, cool – so we just have to tell everyone that they’re not allowed to write UPDATE queries like that, eh?
It’s like “you’re holding it wrong”, but for databases. 😉
Just saying it isn’t broken, it’s doing what they told it to do. If you update a record in the database with the same values already being used, you still updated the record. SQL doesn’t go, oh, the values didn’t change, so no need to update it. If you only wanted records who values changed, you need to compare the values from old and new to decide if you really want to update the retention value.
Exactly – we agree. If the trigger only wants records whose values changed, it needs to compare the values from old to new to decide if they really want to update it.
The trigger is broken if it can’t handle a perfectly fair update statement.
If you disagree with that, we’ll need to agree to disagree. Thanks!
Yes, we agree, just wording it differently.
I Would say both are wrong.
The Update statement is wrong and So it the trigger.
In the trigger you have this statement.. /* If they moved locations, reset their reputation. */
Which means it should be checking Old vs New value.
Which is where the trigger is Wrong.
In the update you have
UPDATE dbo.Users
SET Location = COALESCE(Location, ‘Miami’)
WHERE DisplayName = ‘Brent’;
This is Wrong also .. for any data update of this nature you should always consider if the data needs to change,
and should have included the something like the following logic
AND Location is null — since you are only updating the null values and not the non null values with the coalesce.
I don’t want the overhead of having to update 10 mil rows which are correct. when I might only be targeting a small subset. This will also greatly impact transaction log .. replication etc.. That’s why the above statement is Wrong.
Over all this scenario is 2 Wrongs. and we know 2 wrongs don’t make a right.
They are both Correct Syntax but from a Business perspective they are wrong.. Why should I create CDC record when the record did not change .. these are false positives and this type of stuff should be nipped from code review.
Same scenario Happens in multiple system that predate CDC or other methods .. Where we created triggers for LastUpdateDatetime etc. We only want to capture the date where the value changed and not where the value was updated to the same thing. these types of triggers are used to Make sure we capture and can Sync data between system.. I don’t want to send data to another system if there was no Updates .. its not cost/performance effective.
Another point to note .. If you had used UPDATE() vs UPDATE([Location]) you would be stuck in a recursive loop .. since your trigger would cause another trigger call..
Chris – the problem is, you don’t know ahead of time if the data has changed. There can be several update queries that are all running simultaneously, and they just want to set the value to a new target – regardless of what the old value was. This is a fairly common business need.
/* If they moved locations */ IF UPDATE([Location])
UPDATE([Location]) just informs you that colum [Location] was part of set-part of update statement.
So update() gives no info about any data.
So all records are still in the game even there was no change on [Location].
Then you set Reputation = 0 on all *updated* records without any further restriction.
It’s normal that all records are updated then second time.
You should have added restriction “and i.Location is null” here (as others already put it).
For me, this trigger works fine. I’don’t see any issues.
Check out the query in this training module to understand situations where the query is legit, but this trigger will still fail: https://training.brentozar.com/courses/1337725/lectures/30700117
thx for your answer: the linked content is locked.
again: there is no problem with the update statement, it’s the trigger which is nonsense.
just as I understood.
Yep, I do have to make a living. 😀 Wish I could teach everybody everything for free, but when you go deep enough into the content, that’s where the credit card comes in handy.
Hope you enjoy the free stuff I put out for the public though!
I get the error, that the UPDATE function always returns TRUE when AFTER INSERT.
I tested for single line and multiple.
I solved it with the fn_IsBitSetInBitmask function, but it is more demanding on performance.
Hey, Brent – I’ve come back to this post after you linked to it in a recent post. After reading through the comments, I think at least some of the argument is not over the fact that the trigger is broken, but possibly over your statement of “That trigger is completely broken because it doesn’t handle multi-row updates correctly.”
The trigger is broken, but it’s broken for single-row updates as well as multi-row updates. Consider this SQL:
UPDATE dbo.Users SET Location = Location WHERE ID = 3764;
Only updates one row, right? But it still causes that one row to have 0 set as the Reputation, because the trigger is broken. The trigger is broken because it does not exclude row(s) with same-value Location updates from the update to Reputation in the trigger.
Whether that happened because the SQL Dev / DBA / Bozo the Clown that created the trigger didn’t understand how the UPDATE() function actually works, or they forgot the (NULL-handling) check on Location change in the trigger’s internal update SQL, I can’t know. But hey – we’ve never messed up the WHERE in an UPDATE we ran, right? Certainly never in production, right? 😉
Can you give me a tl;dr? I’m not exactly sure what you’re saying.
TL;DR –
“That trigger is completely broken because it doesn’t handle multi-row updates correctly.”
should be
“That trigger is completely broken because it can update Reputation to 0 for rows that don’t change location.”
Gotcha – yeah, we both agree that the trigger is broken. Good!
So, are we saying that, in SQL Server triggers, the “Update()” [function] might be better named “ColumnPossiblyUpdated”?
What good is that? Ha….
I just happen to be playing with MS Access’ poor attempt at something ‘trigger-like’ (data macros), and although it has been unnecessarily painful, at least the “Updated()” function works exactly as you’d expect. It only reflects when a change was actually made, per row, etc. At least it looks that way to me. This is interesting… (Makes me scared to even try to use triggers in SQL Server if it has functions named like this. 🙂 )
[…] I didn’t use the UPDATE() function because it doesn’t handle multi-row changes accurately […]
Although it is critical tomexplain to the sql developer that using UPDATE() FUNCTION does not mean that the value has actually changed, it does help for performance to discard all other updates that were on different columns.
I think implementing the logic to first check whether they were any “technical” update to the field and then do the dml query WITH checking the value before and after (especially easily with the Inserted amd deleted temporary tables dontue whole thing well.
So Brent is right in saying that the update() function can be misleading functionaly but I feel he is misleading the reader by thunking the function is a risk.
It is for me an important function helping to improve the trigger performance.
Thanks to this function , if 90 % of my update to the table is not done on the very column, then the trigger does not even go into doing a query tonupdate things , it just skip the entire dml operation thanks to the function with the IF statement.
Trigger code is not easy because of all the possibilities and if you can define such IF statement, you make your overall database perform much better.