
No, You Can’t Calculate the Tipping Point with Simple Percentages.
This morning, Greg Gonzalez (who I respect) posted about visualizing the tipping point with Plan Explorer (a product I respect), and he wrote:
The tipping point is the threshold at which a query plan will “tip” from seeking a non-covering nonclustered index to scanning the clustered index or heap. The basic formula is:
- A clustered index (or table) scan will occur when estimated rows exceeds 33% of the number of pages in the table
- A non-clustered seek plus key lookup will occur when estimated rows is below 25% of the pages in the table
- In between 25% and 33% it can go either way
I’ve heard a few varieties of this over the years, but it’s fairly easy to disprove. Let’s take the Users table in the 50GB Stack Overflow 2013 database, and create a skinny version with a few NVARCHAR(MAX) columns that we’re not actually going to populate:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP TABLE IF EXISTS dbo.SkinnyUsers; CREATE TABLE dbo.SkinnyUsers (Id INT PRIMARY KEY CLUSTERED, Reputation INT, AboutMe NVARCHAR(MAX), DisplayName NVARCHAR(MAX), Location NVARCHAR(4000), WebsiteUrl NVARCHAR(MAX)); GO INSERT INTO dbo.SkinnyUsers(Id, Reputation, Location) SELECT Id, Reputation, Location FROM dbo.Users; GO |
Then let’s see how many pages are in our newly created table:
|
1 2 3 4 5 |
/* How many pages are in the table? */ SET STATISTICS IO ON; GO SELECT COUNT(*) FROM dbo.SkinnyUsers; GO |
It has 7,795 pages:

Let’s create an index, and then run a query that could use it, but has to make a tough decision about the tipping point. I’m using 1 = (SELECT 1) to avoid questions about autoparameterization:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX Location ON dbo.SkinnyUsers(Location); GO SELECT * FROM dbo.SkinnyUsers WHERE Location = N'Paris, France' AND 1 = (SELECT 1); GO |
The actual execution plan does an index seek plus thousands of key lookups:
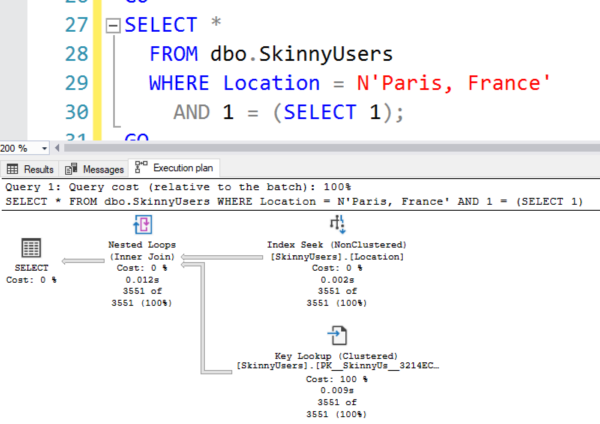
So how does the math work out on that:
- Pages in the table: 7,795
- Estimated number of rows: 3,551 (45.6%)
That’s why I get so fidgety when I see someone give a black-and-white rule like “a clustered index scan will occur when estimated rows exceeds 33% of the number of pages in the table.” It’s just not true, and in some cases – like this one – SQL Server pursues key lookups way, way beyond the point where it makes sense. We’re doing more reads than there are pages in the table:
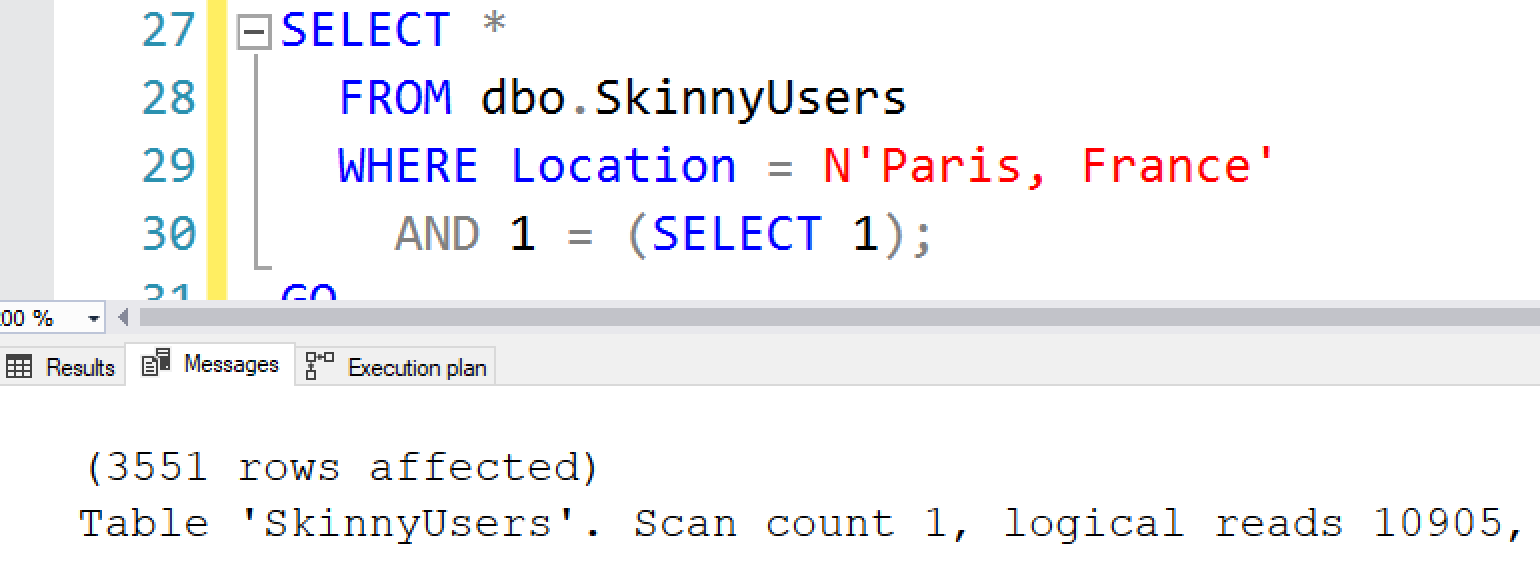
Ouch. So two things: first, that “rule” is just an urban legend, and two, when you hear a rule – no matter who the source is, me included – stop to ask yourself, “If I had to disprove that rule, how would I do it?” Then go grab the Stack Overflow database and do some critical thinking for yourself. Write a demo script. Bust a myth. It’s how you learn, and it’s how you make sure that what you’re learning from is actually right.
Update 2020/05/07 – Greg responded in the comments and he’s corrected his blog post. It now says “will often occur” rather than just “will occur.” Thanks!

21 Comments. Leave new
A good rule of thumb is that rules of thumb are usually wrong.
Hahaha, I love it.
From my Oracle guru Tom Kyte: “ROT – rules of thumb. One persons ‘best practice’ is another persons nightmare.”
Brent, in my testing it actually does hold true much of the time, enough to merit the new functionality.
As with most things in SQL Server it’s certainly not a hard and fast rule, and I will add some more qualifying text in case folks don’t read through the posts I referenced by Kimberly Tripp where she repeatedly emphasizes that “It depends.”
I’ll also look into the example in your post to see if there is more we need to do here. If you have others please share.
The functionality is totally fine – it’s your wording of it as a rule that concerns me. This is going to confuse folks:
“A clustered index (or table) scan will occur when estimated rows exceeds 33% of the number of pages in the table”
You might wanna reword it more tentatively, like “might occur” or “often occurs”.
Fair enough, will do. Thanks for the feedback. If it’s any consolation, in the Plan Explorer Index Analysis documentation which I also referenced, we’ve always said this with regard to the the Estimated Operation:
“This isn’t an exact science, and should be used as a rough guideline.”
You should be fine then. Everyone reads the documentation. 😉
lol, this aged well
Heh… a very wise man once said something to the effect of “In theory, theory and practice should be the same. In practice, they are not”.
In other words, “It Depends”. 😀
Next you’ll be telling us not to reorganize indexes with between 5% and 30% fragmentation and rebuild above 30%.
How does one begin to understand what can influence the various “tipping points” that the SQL Engine uses?…from my research it sounds like a very complicated and non-static threshold used that can vary from query to query. But from your example Brent, it seems like you have some understanding of how to influence it. If you have any recommended resources on this concept, I’m all ears. ?
Indeed I do, and we discuss it in my Mastering Query Tuning class. See you there!
Fair enough. 🙂
I ended up buying your suite of classes a few years ago and life sidetracked me from using any of them lol. Guess it’s time to re-up, see you in the next one!
So what is your opinion about this post:
https://www.sqlskills.com/blogs/kimberly/the-tipping-point-query-answers/
Would you say that Kim’s article agrees with mine, or disagrees, and how?
Nothing. I apologize.
I apologize again, but:
The data type size for the SkinnyUsers column is incorrect! Either use the correct data type size for the columns or enable page compression for the table and nonclustered index. This will cause the tipping point to occur between 25% and 33%.
What do you mean a data type is not correct? I’m confused. Aren’t people allowed to use whatever data type they want? What specifically makes a data type wrong?
Your demonstration is appreciated. However, the data size of the columns is very large. I mean, their size is unusual. Reviewing the column sizes in the original table might be beneficial. If you’re confident in your current column sizes, consider table and index compression.
Gotcha. The data types were just used to show a quick demo. Unfortunately I’ve got bad news for you: compression doesn’t work on off-row data like NVARCHAR(MAX) columns that end up off the 8KB page. But thanks for stopping by!
Thank you!
I’ve tested your demo by compressing the table and its index; the resulting query plan showed a clustered index scan.
Have a good time!