I’m ThatExcited about ThatConference

I about to head out to a vast waterpark in the Midwest to ThatConference, where I’m going to hang out with 1000 developers, their families, and some wild animals.
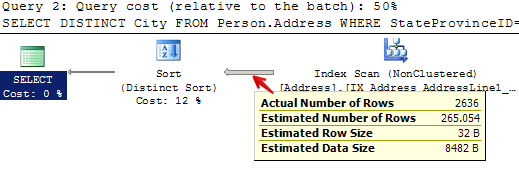
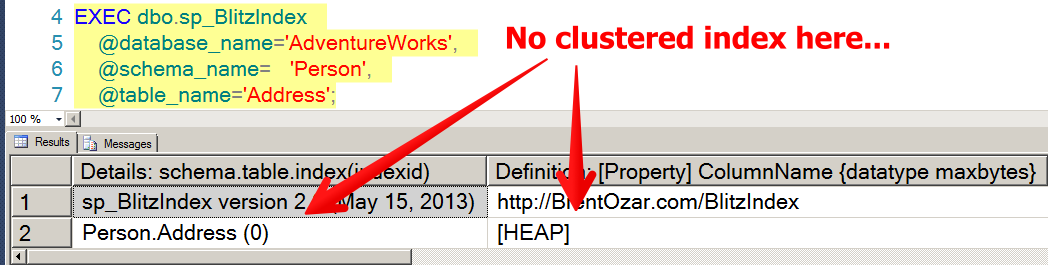
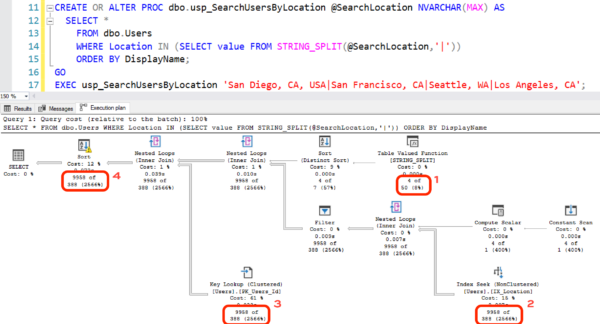
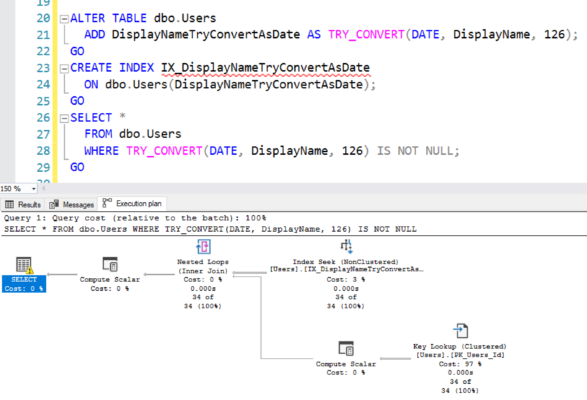
I’m giving a session Monday called “How to Make Deploying Database Changes Fun Again”. I’ve had a blast distilling everything I’ve learned over the years about how to to take the pain out of making changes to databases.
ThatConference isn’t platform specific, so I’m looking forward to meet lots of new people who face similar challenges managing data, but use a variety of tools. I’m looking forward to Game Night. And I’m looking forward to learning a lot.
If you’ll be in the Wisconsin Dells next week, I’d love to meet you! Holler at me on the Twitters or stop by my session!



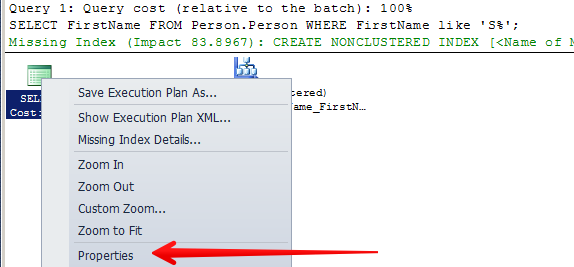
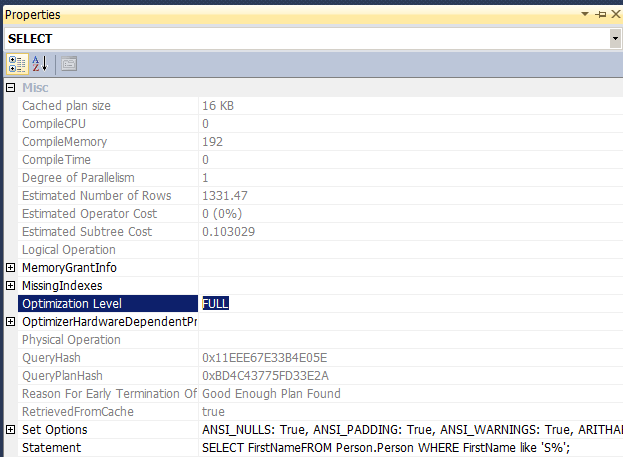
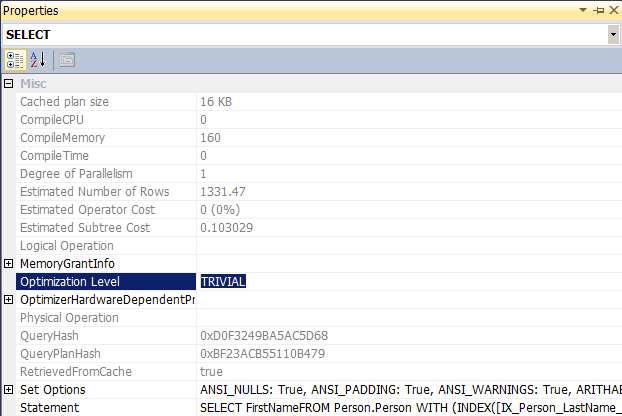
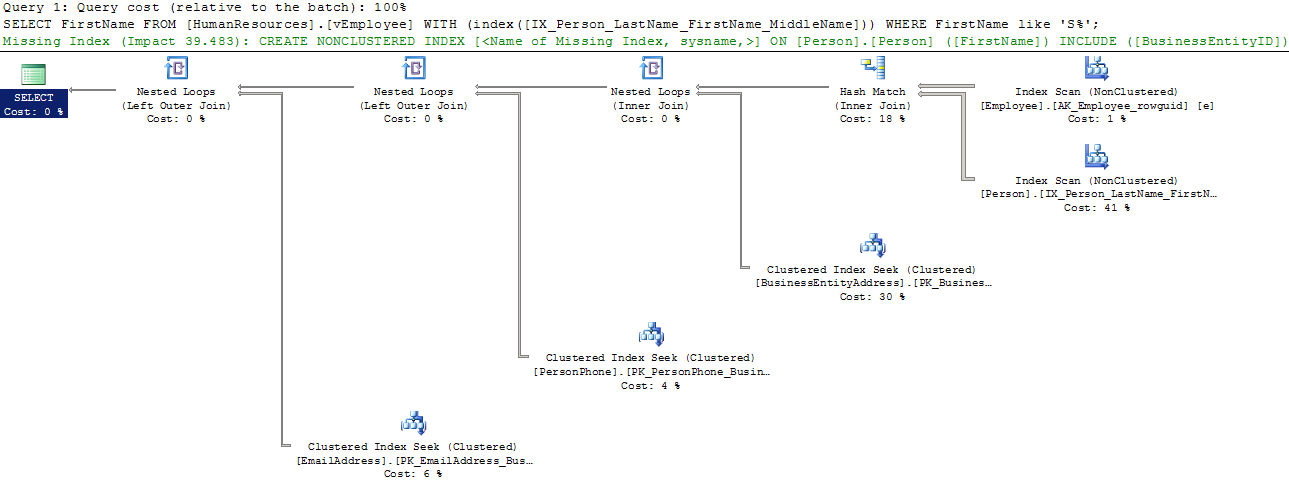
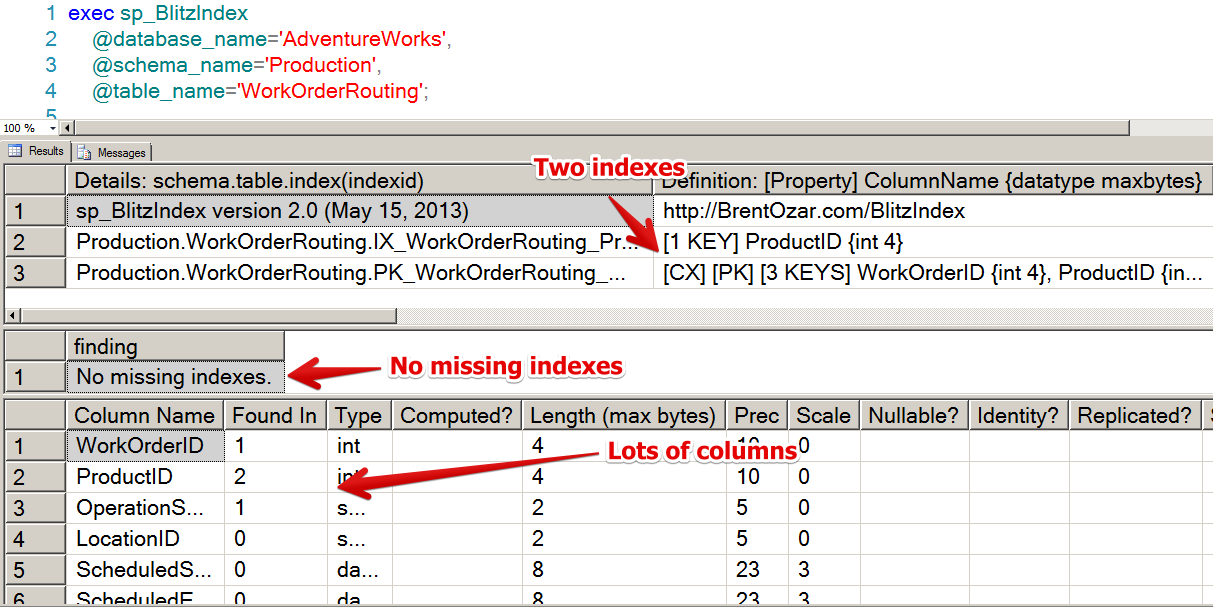







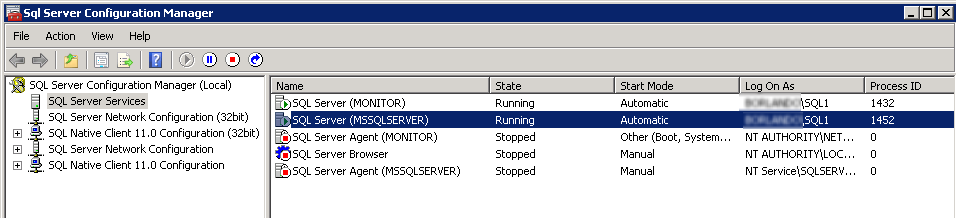




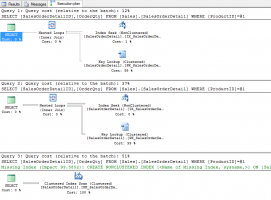
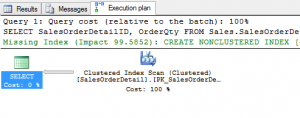
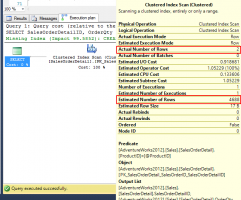


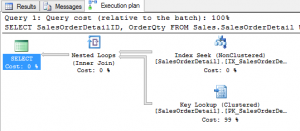
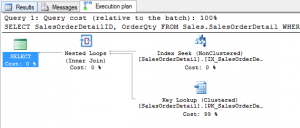
 When you download and start playing with
When you download and start playing with