T-SQL & Development
How to Pass a List of Values Into a Stored Procedure
Say we have a stored procedure that queries the Stack Overflow Users table to find people in a given location. Here’s what the table looks like:

And here’s what my starting stored procedure looks like:
|
1 2 3 4 5 6 7 |
CREATE OR ALTER PROC dbo.usp_SearchUsersByLocation @SearchLocation NVARCHAR(40) AS SELECT * FROM dbo.Users WHERE Location = @SearchLocation ORDER BY DisplayName; GO EXEC usp_SearchUsersByLocation 'San Diego, CA, USA'; |
It works:

And the actual execution plan isn’t bad, although it manages to overestimate the number of people who live in San Diego (est 1264 rows for the top right index seek), so it ends up granting too much memory for the query, and gets a yellow bang warning on the SELECT because of that:

No big deal though – it’s fast. But now my users say they wanna find soulmates in MULTIPLE cities, not just one. They want to be able to pass in a pipe-delimited list of users and search through a few places:
|
1 |
EXEC usp_SearchUsersByLocation 'San Diego, CA, USA|San Francisco, CA|Seattle, WA|Los Angeles, CA'; |
Method #1, no good:
Joining directly to STRING_SPLIT.
SQL Server 2016 added a very nifty and handy STRING_SPLIT function that lets us parse a string with our delimiter of choice:
|
1 2 3 4 5 6 7 |
CREATE OR ALTER PROC dbo.usp_SearchUsersByLocation @SearchLocation NVARCHAR(MAX) AS SELECT * FROM dbo.Users WHERE Location IN (SELECT value FROM STRING_SPLIT(@SearchLocation,'|')) ORDER BY DisplayName; GO EXEC usp_SearchUsersByLocation 'San Diego, CA, USA|San Francisco, CA|Seattle, WA|Los Angeles, CA'; |
The good news is that it compiles and produces accurate results. (Hey, some days, I’ll take any good news that I can get.) The bad news is that the execution plan doesn’t look great:
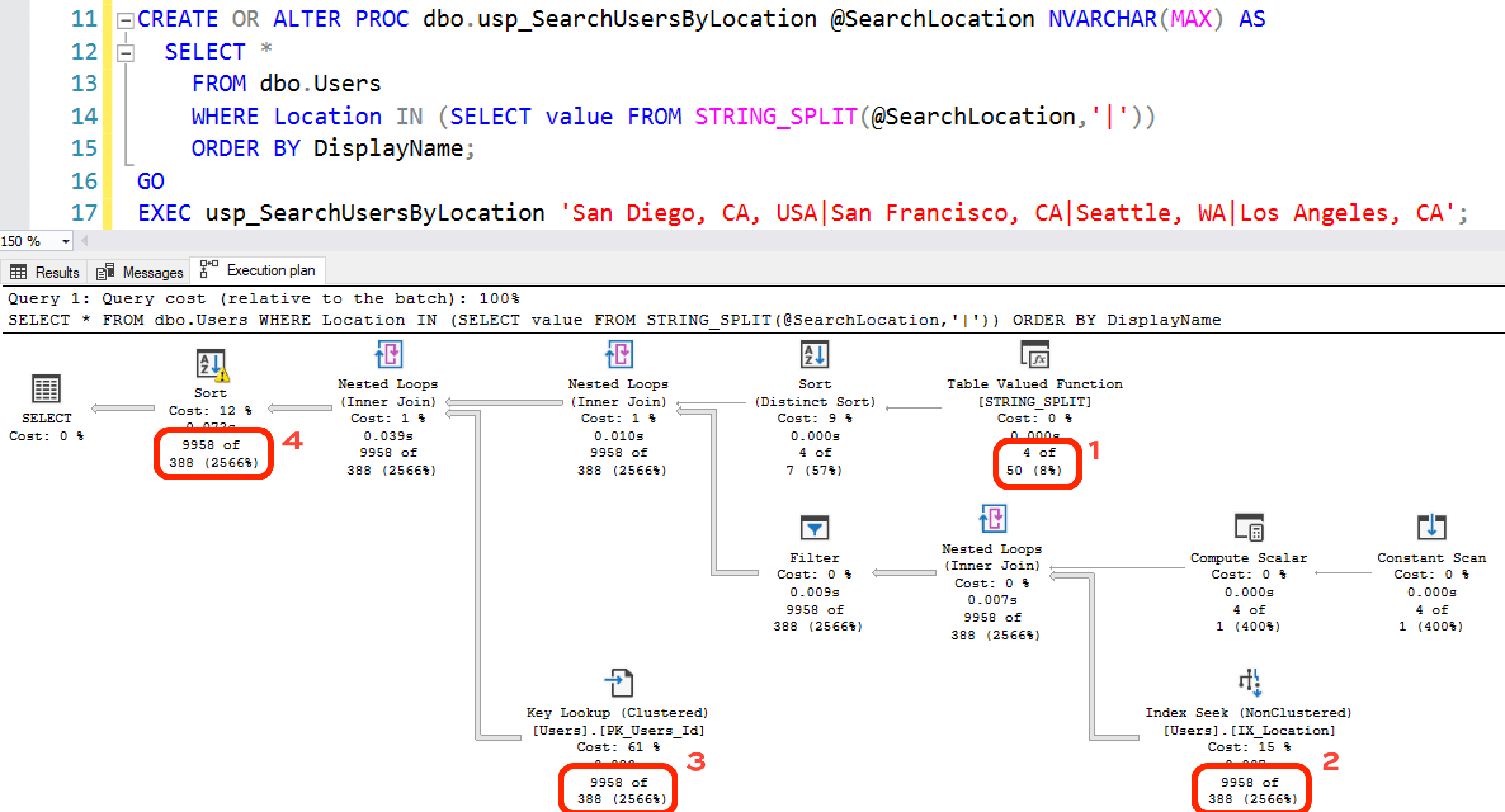
- SQL Server starts by estimating that the STRING_SPLIT will produce 50 values. That’s a hard-coded number that has nothing to do with the actual contents of our @SearchLocation string.
- SQL Server estimates that it’s going to find 388 people in our locations – and that also has nothing to do with the contents of our string. Eagle-eyed readers will note that this 388 estimate is lower than the original estimate for San Diego alone!
- SQL Server does thousands of key lookups, and this plan gets even worse fast when you use bigger locations. It quickly reads more pages than there are in the table itself.
- Because of the original low 388 row estimate, SQL Server didn’t budget enough memory for the sort, which ends up spilling to disk.
The root problem here: STRING_SPLIT doesn’t produce accurate estimates for the number of rows nor their contents.
Method #2, better:
dump STRING_SPLIT into a temp table first.
This requires a little bit more work at the start of our proc:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE OR ALTER PROC dbo.usp_SearchUsersByLocation @SearchLocation NVARCHAR(MAX) AS BEGIN CREATE TABLE #Locations (Location NVARCHAR(40)); INSERT INTO #Locations (Location) SELECT value FROM STRING_SPLIT(@SearchLocation,'|'); SELECT * FROM dbo.Users WHERE Location IN (SELECT Location FROM #Locations) ORDER BY DisplayName; END GO EXEC usp_SearchUsersByLocation 'San Diego, CA, USA|San Francisco, CA|Seattle, WA|Los Angeles, CA'; |
By dumping the string’s contents into a temp table, SQL Server can then generate statistics on that temp table, and use those statistics to help it better estimate the number of rows it’ll find in the various cities. Here’s the actual plan:

Now, the bad 50-row estimate for STRING_SPLIT has a small blast radius: the only query impacted is the insert into the temp table, which isn’t a big deal. Then when it’s time to estimate rows for the index seek, they’re much more accurate – within about 5X – and now the Sort operator has enough memory budgeted to avoid spilling to disk.
Method #3, terrible:
dump STRING_SPLIT into a table variable.
I know somebody’s gonna ask, so I have to do it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE OR ALTER PROC dbo.usp_SearchUsersByLocation @SearchLocation NVARCHAR(MAX) AS BEGIN DECLARE @Locations TABLE (Location NVARCHAR(40)); INSERT INTO @Locations (Location) SELECT value FROM STRING_SPLIT(@SearchLocation,'|'); SELECT * FROM dbo.Users WHERE Location IN (SELECT Location FROM @Locations) ORDER BY DisplayName; END GO EXEC usp_SearchUsersByLocation 'San Diego, CA, USA|San Francisco, CA|Seattle, WA|Los Angeles, CA'; |
In SQL Server 2017 & prior, the query plan on this manages to be even worse than calling STRING_SPLIT directly:

SQL Server now only estimates that 1 row is coming out of the table variable, so now its estimate on the number of users it’ll find is down to just 55, and the sort spills even more pages to disk.
Thankfully, as you may have heard, SQL Server 2019 fixes this problem. I’ll switch to 2019 compatibility level, and here’s the actual plan:

Okay, well, as it turns out, no bueno. We just get a 4 row estimate instead of 1 for the table variable, and we still only get 110 estimated users in those cities. Table variables: still a hot mess in SQL Server 2019.
The winner: pass in a string, but when your proc starts, split the contents into a temp table first, and use that through the rest of the query.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
What about passing in an XML string or a JSON string and joining to that? I have some older procs which pass in the XML string and then process against the xml.nodes for inserts or updates. This allows passing in multiple rows of structured data.
You can go ahead and use the testing methods shown in this post to see how they perform in comparison.
Isn’t better to pass the values in a table and receive it in user define table type with just one column?
Go ahead and use the testing methods shown in this post to see how it performs in comparison. (Your first hint is how the table variable performs in the post.)
I’ve used the iter_charlist_to_tbl (I think that’s how he spelled it). It is very fast.
https://www.sommarskog.se/arrays-in-sql.html
I have done this. It is difficult to make it work for XML with arbitrary/unpredictable heirarchy, depth, and node names, although I did it. Much easier to count delimiters in a string!
It was not easy and performance was not the primary consideration, since it was an automated process (parsing execution history logs to track performance and identify error messages and respond accordingly). And of course parsing xml has it’s own idiosyncrasies since there are so many “reserved” characters that must be escaped – or not -depending on context.
I was tasked with accepting input from a 3rd party app that allowed users to enter in a search string of comma delimited values where any, all, or none of the individual values should return matching rows..
I performance tested a number of methods of parsing the comma delimited string passed into the stored proc, and after _extensive_ performance testing, ended up doing exactly what you described (although I used a UDF to do the parsing). The performance difference vs. other methods was significant. I doubt the solution would have been acceptable with the poorer performing methods. Believe it or not, sometimes the strings could represent characters, sometimes date values, sometimes numeric values. And the users were even allowed to enter mathematical and comparison operators in the strings! (so the parsing functions could get a bit hairy). App has been running for years now in Law Firm, irreplaceable by any outside vendors…
p.s. Kudos to you Brent for this blog that addresses day to day practical DB programming problems as well as content on some of the deeper sql server internals.
Ken – glad you enjoy it! I have a good time writing this kind of stuff up. Everything here is based on problems I run into at clients or questions from training class students, so it tends to be a fun mix of issues.
Hi Ken, is that parsing UDF available anywhere? I think I saw something on SO comparing methods in older versions of SQL Server, pre- SPLIT_STRING but I never implemented them because they all seemed to have some caveats. We have a similar feature in our application but I’m not happy with it.
Sorry, the law firm owns it since I developed it when working as a contractor for them. My boss at the time in the finance dept. of the firm tried to convince me we should market it to all the other law firms in the world that are using that 3rd party app we were enhancing.
The basic idea of the parsing was to pass in enough info the the function so it would know what the delimiter was, what the data type was (character, date, or numeric). And then also look for a certain limited number of “operators” that might be found in the user’s string, depending on the data type.
I had to take it one step at a time, first parsing, then looking for operators, then in the calling stored proc, placing the parsed data elements into temp tables.
OK, totally understand. And thanks for the additional details. I dig around for that original SO post… I’m sure I can cobble up something for my 2008-2012 customers of which there are many.
This is awesome, thanks so much for taking the time to perform this experiment. I would love to convert all my legacy code to STRING_SPLIT against a temp table, if only I could get my customer base off 2008 R2 or 2012 servers and onto 2016. On the bright side, that gives me plenty of time before I have to do the actual refactor itself. 😉
Jeffrey – you can still do the string splitting technique in prior versions. Google for string splitting Jeff Moden, or string splitting Aaron Bertrand, and there are a bunch of ways to do it.
Right… that’s it, Moden’s approach. Thanks.
I[‘ll have to dissent on that on what Brent stated. Aaron tested using repeating “grooved” data with a cardinality of something like 5. I tried to warn him but he got all huffy and closed the post. The low cardinality tests make it look like the XML splitter is actually better than Tally method (which he also did incorrectly in the article). Nothing could be further from the truth. The DelimitedSplit8K function blows the XML method of splitting away and I’m happy to prove it as many times as needed. If you have 2012 or above, Eirikur Erikson made a tweak using LEAD and it runs almost as fast as a CLR splitter and enumerates the split out elements.
You can also create a Type “CREATE TYPE cities_list AS TABLE (Location NVARCHAR(40) NOT NULL PRIMARY KEY );”
And then you pass a parameter of that type in your stored proc.
It’s a solution I’ve used in the past in order to pass a list of values to a stored proc.
That definitely feels cleaner than a delimited string, especially if your data has more than one column. It does mean you’re using a table variable, with all the problems discussed above.
If your motivation for avoiding csv is that have a *lot* of data, you’re possibly better off just using bulk insert into a temp table. But that’s uglier to maintain.
Danielle & Brian – yeah, but you run into the same row estimation problem that I talk about in the post.
From SQL docs “SQL Server does not maintain statistics on columns of table-valued parameters.” I’m guessing that’s the cause of the row estimation issues?
That’s why I then dump the table variable into a temp table. Don’t need to mess with splitting strings, but still use the temp table for better performance.
Because temp tables can be cached don’t you also might need to follow the pattern where after the inserts into Temp table you update it’s statistics, and where you consume the contents of the temp table you use OPTION RECOMPILE.
This comes from reading https://www.sql.kiwi/2012/08/temporary-tables-in-stored-procedures.html
Bill – yep, just only so much I can teach in one blog post. Thanks!
Got to that “Dump to a table variable” part and had to laugh when it said “terrible”. I was fully expecting this to go in order to “best” and when table variables showed up there, I did a double-take, then laughed. Thanks for the heavy research on this. I typically do that “dump to temp table with index” option. It’s good to know that I’m not crazy. 🙂
Hi Brent, I can see 2 other methods:
– build a dynamic sql (sql injection risk)
– use tally (numbers) table to parse the string – that used to be the fastest way to split string
Radek – OK, cool, go ahead and write those up in a blog post. Thanks!
Hi Brent, why is the temp table better than the table variable – what’s the reason the sql server estimates so badly in method #3?
Timon – you can learn more in my Mastering Query Tuning class in the estimations module.
Just a random thought: There might be a slightly different fourth way I thought about first when glancing the title….pass a table variable to a stored procedure as an input variable rather than the string. It’s conceptually a bit different and takes populating the table variable back to the user of the stored procedure. Given performance I guess it would be as bad as method #3 and you could trick a bit with “OPTION (RECOMPILE)” in older SQL versions. I have done that once for sharing table results between two stored procedures. Performance was not the main consideration as I was only dealing with metadata about foreign key constraints on one table in an ETL context. Following that approach you could even get fancy as defining your own table type.
Martin – you can’t use a table variable as an input variable without defining your own table type. It’s called table valued parameters, and yes, the performance is as bad as method 3, plus it comes with even worse surprises.
What if #Locations temp table was given a clustered index? Certainly a binary search as an index scan would help. Does the Users table have any indexing on the location field?
Another approach I’d be curious about – Full Text Search. Split the input into a query producing ‘or’ search clauses.
By all means, give ’em a shot! Go for it. That’s the great thing about my demos – everything’s open source, so you can try your own ideas.
Brent, In Method #2, would you expect a JOIN in the SELECT to perform better than the IN() if the number of delimited locations passed in was large, say over 50?
Mark – feel free to give it a shot to find out! That’s the great thing about my demos – everything’s open source, so you can try your own ideas.
Brent, I understand. 🙂 I was just curious about what you would expect. I’d read elsewhere that IN(SELECT foo FROM bar) can have performance issues when there are more than some number of values over a tipping point (I think it was something like 17 values).
Mark – I wish I could answer every edge case and scenario in every blog post, but I try to do as good of a job as I can do for free in a short period of time. Hope you enjoy it! Now, it’s your turn to pick up and do some work too. Hope that’s fair.
Of course. Thanks for all you do!
Several years ago, I did a series of articles (see references) on using a long parameter list to pass a set of values. The second article shows the advantages of not writing your own parser in SQL, a language that was never meant for text handling or compiler writing.
https://www.red-gate.com/simple-talk/sql/learn-sql-server/values-and-long-parameter-lists/
https://www.red-gate.com/simple-talk/sql/learn-sql-server/values-and-long-parameter-lists-part-ii/
Good to hear from you, sir! Thanks for the note.
[[ the advantages of not writing your own parser in SQL, a language that was never meant for text handling ]]
How right you are! I almost soiled my drawers when my boss told me I had to do this to enhance a 3rd party accounting app (part of building a custom reporting solution for that app).
Believe me I tried to get out of it. But being a contractor, it was do or goodbye- it was basically what I was hired to do. I was actually quite surprised at how well it worked out. Still in use – business critical functionality – since 5 years. And I am long gone from that firm although I maintain contact with colleagues still there.
It is very strange that no one in the comments provided a link to a brilliant article by Erland Sommarskog: How to Share Data between Stored Procedures (http://www.sommarskog.se/share_data.html) Erland Sommarskog
good one
Method #4: Stop breaking 1NF. Use a TVP with an index and Trace flag 2453
I have a question for you concerning stored procs in SQL Server 2016. Is there a limit to the number of parameters that can be passed into a stored proc?
I’m asking because we’re looking at a possible project where an external app may be calling a stored proc
For general Q&A, hit a Q&A site like https://dba.stackexchange.com.
Heh… first stop should be a search engine to find the documentation.
How can I use multiple primary keys in this stored procedure?
See, in the below table the Primary Key column will hold the primary keys of the table.
ID | ORACLESCHEMA|ORACLETABLE|DEVDWSCHEMA|DEVDWTABLE|COLUMNLIST|PrimaryKeys
1 | APPS | SAMPLE | DEVDW | SAMPLE | NULL | ID, NAME
2 | AP | SAMPLE2 | DEVDW | SAMPLE2 | NULL | ID,NAME,ORDER
I’m not sure what you mean by multiple primary keys – you’ll probably want to post a question over at https://dba.stackexchange.com or https://sqlservercentral.com with the specifics of what you’re trying to do.
Set @Query1 = N’DELETE STG.[‘ + @StageTable + ‘] FROM STG.’ + @StageTable + ‘ a INNER JOIN LANDING.’ + @LandingTable +
‘ b ON a.’ + @PrimaryKeys + ‘ = b.’ + @PrimaryKeys
?
Like, you have multiple “locations”, I have multiple “primary keys” and i am trying to delete using this in a condition
You’ll probably want to post a question over at https://dba.stackexchange.com or https://sqlservercentral.com with the specifics of what you’re trying to do. Thanks!
https://stackoverflow.com/questions/67412932/how-can-i-use-multiple-primary-keys-in-this-stored-procedure?noredirect=1#comment119155651_67412932
here I have posted this question…please see
I’m going to be honest: you’re having a tough time over there because you didn’t follow the instructions shown onscreen during the ask-a-question process.
Try reading these:
https://codeblog.jonskeet.uk/2010/08/29/writing-the-perfect-question/
https://codeblog.jonskeet.uk/2012/11/24/stack-overflow-question-checklist/
How can I use this in inner join? I have multiple primary keys which i want to use in on condition of join and i think this method will be used. Can you help me?
How can I use this in inner join? i want to use this method in on condition of join and i think this method will be used. Can you help me?
I have repeatedly told you where to go. Further comments here will not be productive. Thanks for understanding.
Sorry, but I have commented for the first time. was hoping to get some help but sorry, guess you don’t want to help
Correct, I don’t want to do free personal query troubleshooting in the blog post comments. I wish I could, but I need to maintain a work/life balance, and I need to steer you somewhere that will work better for you long term. Nothing personal.
Hi! I have a dynamic variable @PrimaryKeys which can have single or multiple value.
Set @Query1 = N’DELETE STG.[‘ + @StageTable + ‘] FROM STG.’ + @StageTable + ‘ a INNER JOIN LANDING.’ + @LandingTable +
‘ b ON’+'(‘ +’a.’+@PrimaryKeys+ ‘ = b.’ + @PrimaryKeys+’)’
This Query works for the case when @PrimaryKeys has one column, but what if it has multiple columns. Can You help?
You’ll probably want to post a question over at https://dba.stackexchange.com or https://sqlservercentral.com with the specifics of what you’re trying to do. Thanks!
If you are comparing an INT there is a CardinalityEstimate warning when casting the value string. Is this a concern fo any kind? The input string is a list of int IDs.
CREATE TABLE #GameIds
(
Id INT
)
INSERT INTO #GameIds
SELECT CAST(value AS INT) FROM STRING_SPLIT(@GameIds,’,’);
CREATE NONCLUSTERED INDEX IX_GameIds_Temp ON #GameIds (Id);
Great tips. Thanks for considering us compat mode 120 luddites.