SSMS Trick: Edit Large Procedures with the Splitter Bar
11 Comments
Here’s a SQL Server Management Studio trick that comes in super handy when you’ve got long pieces of code. I almost never see anyone use this, and I think the reason is that few people know about it.
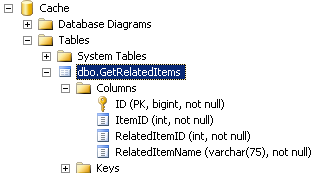
When I’m working on a stored procedure, sometimes I want to add in a new variable or a temp table. I declare ’em all at the top of the procedure, but I’m working much farther down in the proc than that.
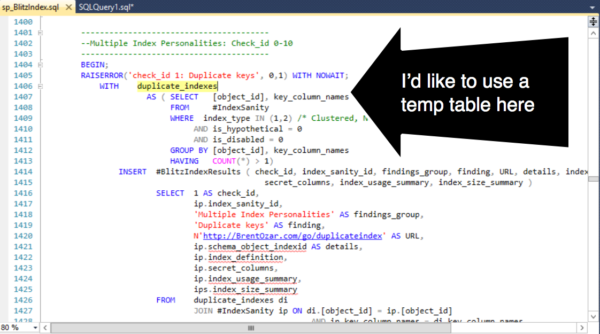
I don’t have to lose my place. I can split the window using a cool, but hard to see feature known as the “splitter bar”.

Drag the splitter bar down. I now have two synchronized views into my procedure.
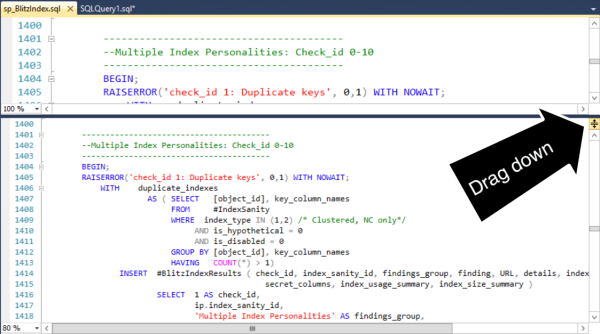
Voila, I can add my temp table in the right area without losing my place.

This feature isn’t specific to SQL Server Management Studio– it exists in lots of other products. (Including Word!) But the feature is hard to spot and most folks just never seem to learn about it. (I had no idea it was there myself until Jeremiah showed it to me a while back, and now I’m addicted to it.)
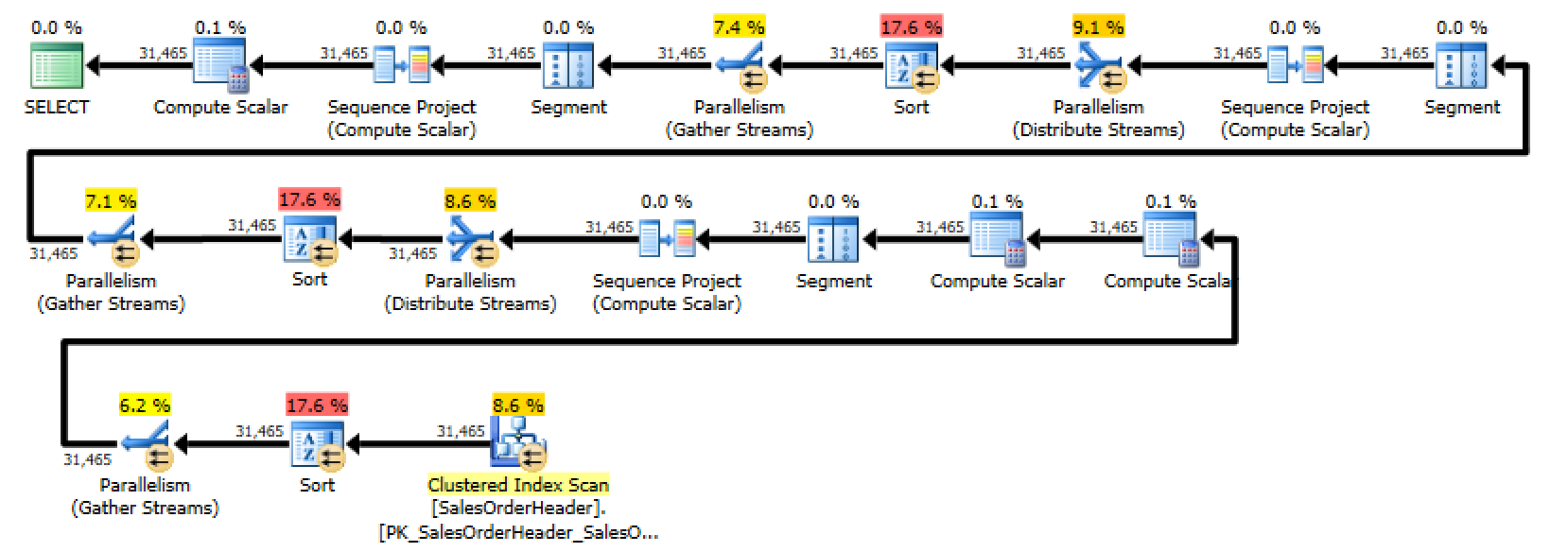








 SQL Server has amazing instrumentation. Dynamic management views and functions give you great insight into what’s happening in your SQL Server and what’s slowing it down. Interpreting these views and functions takes a lot of time, but with practice and skill you can use them to become great at performance tuning.
SQL Server has amazing instrumentation. Dynamic management views and functions give you great insight into what’s happening in your SQL Server and what’s slowing it down. Interpreting these views and functions takes a lot of time, but with practice and skill you can use them to become great at performance tuning.