How to count the number of rows in a table in SQL Server
50 Comments
“How many rows exist in a table?”
It seems like such an innocent request. It isn’t too hard to get this information out of SQL Server. But before you open SSMS and whip out a quick query, understand that there are multiple methods to get this information out of SQL Server – and none of them are perfect!
COUNT(*) or COUNT(1)
The seemingly obvious way to get the count of rows from the table is to use the COUNT function. There are two common ways to do this – COUNT(*) and COUNT(1). Let’s look at COUNT(*) first.
|
1 2 |
SELECT COUNT(*) FROM dbo.bigTransactionHistory; |
The STATISTICS IO output of this query shows that SQL Server is doing a lot of work! Over 100,000 logical reads, physical reads, and even read-ahead reads need to be done to satisfy this query.
|
1 2 3 4 |
(1 row(s) affected) Table 'bigTransactionHistory'. Scan count 5, logical reads 132534, physical reads 3, read-ahead reads 131834, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
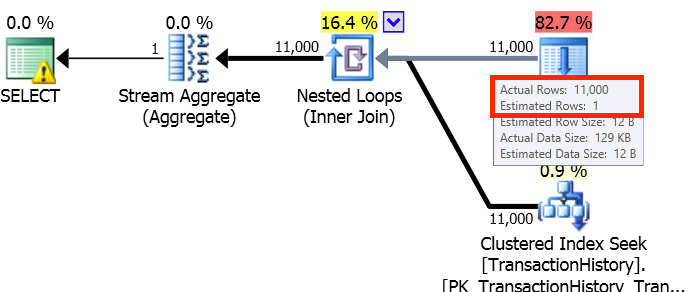
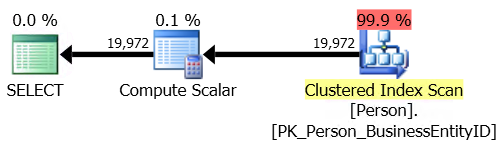
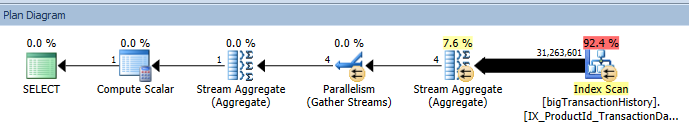
Looking at the execution plan, we can see an Index Scan returning over 31 million rows. This means that SQL Server is reading every row in the index, then aggregating and counting the value – finally ending up with our result set. The cost of this query? 123.910000.

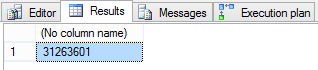
The query results: 31,263,601 rows.
Now, let’s look at the behavior of COUNT(1).
|
1 2 |
SELECT COUNT(1) FROM dbo.bigTransactionHistory; |
We can see from STATISTICS IO that we have a large number of logical reads – over 100,000.
|
1 2 3 4 |
(1 row(s) affected) Table 'bigTransactionHistory'. Scan count 5, logical reads 132531, physical reads 3, read-ahead reads 131849, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The execution plan again shows an index scan returning over 31 million rows for processing. The query cost is the same, 123.910000.
The results here are the same – 31,263,601 rows.
The benefit of using COUNT is that it is an accurate indicator of exactly how many rows exist in the table at the time query processing begins. However, as the table is scanned, locks are being held. This means that other queries that need to access this table have to wait in line. This might be acceptable on an occasional basis, but I frequently see applications issuing these types of queries hundreds or thousands of times per minute.
sys.tables + sys.indexes + sys.partitions
We can join several SQL Server catalog views to count the rows in a table or index, also. sys.tables will return objects that are user-defined tables; sys.indexes returns a row for each index of the table; and sys.partitions returns a row for each partition in the table or index. I am going to query for the table ID, name, and count of rows in all partitions.
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @TableName sysname SET @TableName = 'bigTransactionHistory' SELECT TBL.object_id, TBL.name, SUM(PART.rows) AS rows FROM sys.tables TBL INNER JOIN sys.partitions PART ON TBL.object_id = PART.object_id INNER JOIN sys.indexes IDX ON PART.object_id = IDX.object_id AND PART.index_id = IDX.index_id WHERE TBL.name = @TableName AND IDX.index_id < 2 GROUP BY TBL.object_id, TBL.name; |
The output of STATISTICS IO here shows far fewer reads – 15 logical reads total.
|
1 2 3 4 5 6 7 8 9 |
(1 row(s) affected) Table 'syssingleobjrefs'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'sysidxstats'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'sysrowsets'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'sysschobjs'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The execution plan is more complex, but much less work – the query cost here is 0.0341384.

The results of the query are also the same – 31,263,301.
![]()
The benefits of using this method are that the query is much more efficient, and it doesn’t lock the table you need the count of rows for.
However, you need to be cautious when counting the rows on a table that is frequently inserted into or deleted from. The TechNet documentation for sys.partitions.rows says it indicates the “approximate number of rows for this partition”. How approximate? That information isn’t documented. Understand, though, that if you use this method, you potentially sacrifice up-to-the-moment accuracy for performance.
sys.dm_db_partition_stats
A third option is to use the dynamic management view sys.dm_db_partition_stats. This returns one row per partition for an index.
|
1 2 3 4 5 6 7 8 |
DECLARE @TableName sysname SET @TableName = 'bigTransactionHistory' SELECT OBJECT_NAME(object_id), SUM(row_count) AS rows FROM sys.dm_db_partition_stats WHERE object_id = OBJECT_ID(@TableName) AND index_id < 2 GROUP BY OBJECT_NAME(object_id); |
The STATISTICS IO output of this query is even lower – this time, only two logical reads are performed.
|
1 2 3 |
(1 row(s) affected) Table 'sysidxstats'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The execution plan is less complex than our second example involving the three system views. This query also has a lower cost – 0.0146517.

The query results are the same as the previous examples – 31,263,301 rows.
Using this DMV has the same benefits as the system views – fewer logical reads and no locking of the target table. The query is also simpler to write, involving only one object.
But again, the TechNet documentation for sys.dm_db_partition_stats.row_count says it is “the approximate number of rows in the partition”, and when this information is updated is not documented. Here, you are also potentially sacrificing accuracy for performance.
Time to do some digging
The questions that you need to work with the business to answer are, “How up-to-date must the row count be? What is the business purpose? How often do you insert into or delete from that table, and how often do you count the rows?” If the accuracy of the row count is crucial, work to reduce the amount of updates done to the table. If performance is more important, and the row count could be approximate, use one of the system views.
Wanna learn more tricks for free?
Check out our free T-SQL Level Up online class – we guarantee it’s the best T-SQL training trailer you’ve ever seen:
https://www.youtube.com/watch?v=5RrUSn_qViA