
Dynamic Sorting
While working on some DMV scripts, I came up with a lazy way to have a user definable sort order in the query that seemed like pure genius. I showed it to the team and they’d never seen anything like it before.
The Situation
Users like to be in control. They want to define custom columns, sort orders, and basically drag, drop, and pivot chart their way to victory. While I’m not going to show you how to build custom everything, we can look at a custom sort order.
Let’s start with a simple query:
|
1 2 3 4 |
SELECT SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM Sales.SalesOrderHeader |
Possible Solutions
Our users want to be able to define a custom sort order on this query. We could solve this in a few ways:
- Writing several stored procedures
- Use dynamic SQL to build an
ORDER BY
Writing several stored procedures is tedious and error prone – it’s possible that a bug can be fixed in one of the stored procedures but not the others. This solution also presents additional surface area for developers and DBAs to test and maintain. The one advantage that this approach has is that each stored procedure can be tuned individually. For high performance workloads, this is a distinct advantage. For everything else, it’s a liability.
We could also use dynamic SQL to build an order clause. I wanted to avoid this approach because it seemed hacky. After all, it’s just string concatenation. I also wanted to work in the ability for users to supply a top parameter without having to use the TOP operator.
The First Attempt
My first attempt at rocket science looked like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
DECLARE @SortOrder VARCHAR(50) = 'OrderDate'; SELECT rn, SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM ( SELECT CASE @SortOrder WHEN 'OrderDate' THEN ROW_NUMBER() OVER (ORDER BY OrderDate DESC) WHEN 'DueDate' THEN ROW_NUMBER() OVER (ORDER BY DueDate DESC) WHEN 'ShipDate' THEN ROW_NUMBER() OVER (ORDER BY ShipDate DESC) END AS rn, SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM Sales.SalesOrderHeader ) AS x ORDER BY rn ASC; |
Why do it this way? There are a few tricks with paging that you can perform using ROW_NUMBER() that I find to be more readable than using OFFSET and FETCH in SQL Server 2012. Plus ROW_NUMBER() tricks don’t require SQL Server 2012.
Unfortunately, when I looked at the execution plan for this query, I discovered that SQL Server was performing three separate sorts – one for each of the case statements. You could generously describe this as “less than optimal”.
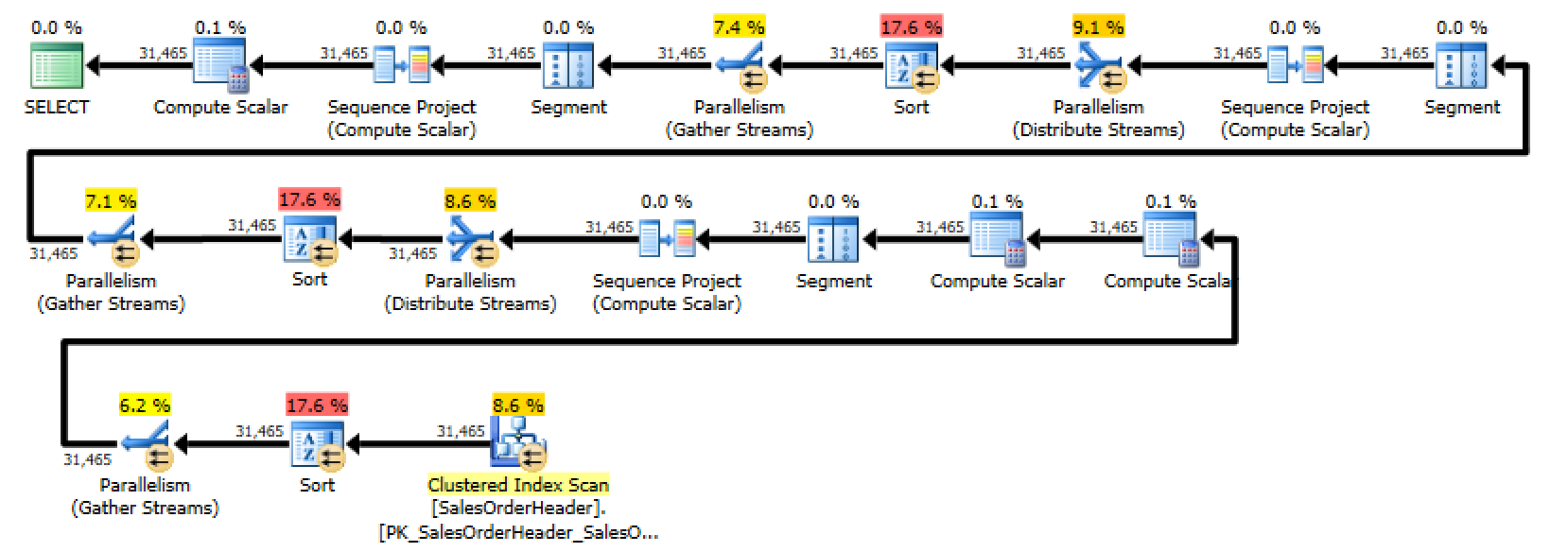
Even though it seems like SQL Server should optimize out the CASE statement, the obvious thing doesn’t happen. SQL Server has to compute the ROW_NUMBER() for every row in the result set and then evaluate the condition in order to determine which row to return – you can even see this in the first execution plan. The second to last node in the plan is a Compute Scalar that determines which ROW_NUMBER() to return.
I had to dig in and figure out a better way for users get a custom sort option.
Moving the CASE to the ORDER BY
My next attempt moved the custom sort down to the ORDER BY clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DECLARE @SortOrder VARCHAR(50) = 'OrderDate'; SELECT SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM Sales.SalesOrderHeader ORDER BY CASE @SortOrder WHEN 'OrderDate' THEN ROW_NUMBER() OVER (ORDER BY OrderDate DESC) WHEN 'DueDate' THEN ROW_NUMBER() OVER (ORDER BY DueDate DESC) WHEN 'ShipDate' THEN ROW_NUMBER() OVER (ORDER BY ShipDate DESC) END ASC |
This ended up performing worse than the first attempt (query cost of 8.277 compared to the original query’s cost of 6.1622). The new query adds a fourth sort operator. Not only is the query sorting once for each of the possible dates, it’s then performing an additional sort on the output of the ROW_NUMBER() operator in the ORDER BY. This clearly isn’t going to work.
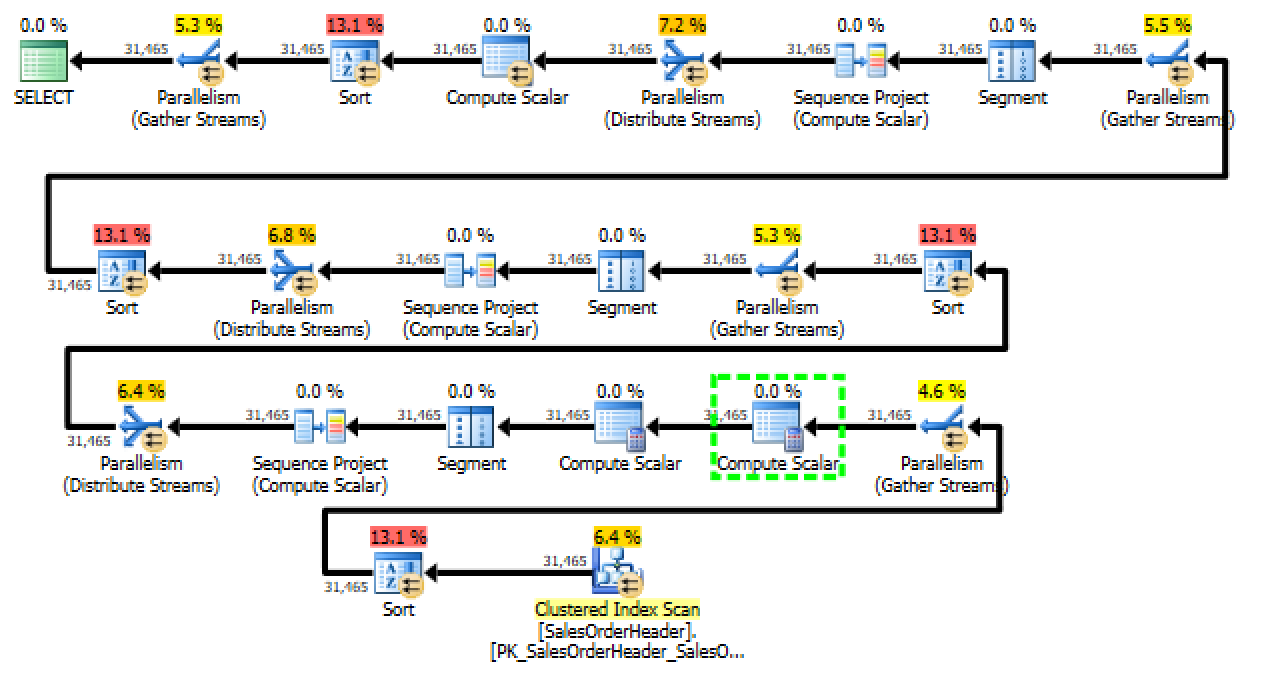
Getting Rid of ROW_NUMBER()
It seems like ROW_NUMBER() really isn’t necessary for our scenario. After all – I only added it as a trick if so I could potentially add paging further down the road. Let’s see what happens if we remove it from the query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DECLARE @SortOrder VARCHAR(50) = 'OrderDate'; SELECT SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM Sales.SalesOrderHeader ORDER BY CASE @SortOrder WHEN 'OrderDate' THEN OrderDate WHEN 'DueDate' THEN DueDate WHEN 'ShipDate' THEN ShipDate END DESC |
Right away, it’s easy to see that the query is a lot simpler. Just look at the execution plan:

This new form of the query is a winner: the plan is vastly simpler. Even though there’s a massive sort operation going on, the query is still much cheaper – the over all cost is right around 2 – it’s more than three times cheaper than the first plan that we started with.
There’s one downside to this approach – we’ve lost the ability to page results unless we either add back in the ROW_NUMBER() or else use FETCH and OFFSET.
Bonus Round: Back to ROW_NUMBER
While using my brother as a rubber duck, he suggested one last permutation – combine the ORDER BY technique with the ROW_NUMBER() technique:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
DECLARE @SortOrder VARCHAR(50) = 'OrderDate'; SELECT rn, SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM ( SELECT ROW_NUMBER() OVER (ORDER BY CASE @SortOrder WHEN 'OrderDate' THEN OrderDate WHEN 'DueDate' THEN DueDate WHEN 'ShipDate' THEN ShipDate END DESC) AS rn, SalesOrderNumber, OrderDate, DueDate, ShipDate, PurchaseOrderNumber, AccountNumber, SubTotal, TaxAmt, Freight, TotalDue FROM Sales.SalesOrderHeader ) AS x ORDER BY rn ; |
This ended up being almost as fast as the ORDER BY approach; this query’s cost is only 0.00314 higher than the ORDER BY. I don’t know about you, but I would classify that as “pretty much the same”. The advantage of this approach is that we get to keep the ROW_NUMBER() for paging purposes, there is only one sort, and the code is still relatively simple for maintenance and development purposes.
Check out the plan!

What Did We Learn?
I learned that trying to be smarter than SQL Server can lead to pretty terrible performance. It’s important to remember that the optimizer reserves the right to re-write. In the first and second case, SQL Server did me a favor by re-writing the query. Our third case is fairly obvious. The fourth example is somewhat surprising – by shifting around the location of theCASE, we’re able to eliminate multiple sorts and gain the benefit of using ROW_NUMBER().

36 Comments. Leave new
A couple of remarks:
1. If the columns that we need to sort on have different types, the above case…when syntax won’t work; but the following does work:
ORDER BY
CASE @SortOrder WHEN ‘OrderDate’ THEN OrderDate END,
CASE @SortOrder WHEN ‘DueDate’ THEN DueDate END,
CASE @SortOrder WHEN ‘ShipDate’ THEN ShipDate END
2. I use a small trick for bidirectional sorting:
CASE @SortOrder WHEN ‘OrderDate’ THEN OrderDate END,
CASE @SortOrder WHEN ‘OrderDateDESC’ THEN OrderDate END DESC,
3. When paging, don’t forget to place the WHERE clause inside the sub query/CTE query.
4. I prefer writing the query with a CTE, as I find it more readable.
This technique is a great time saver for situation when constrained to query the db only through stored procs.
Can you please explain how your *victorious* query guarantees a sort order? The only ORDERing is in the OVER clause which returns an ordered number but doesn’t necessarily affect the order of the resultset. Right?
Great question and good catch.
It turns out that I left the ORDER BY off of the query that I pasted into the blog post. When you run the query in SSMS against AdventureWorks2012 (or, in my case, AdventureWorks2012_CS) you get the same execution plan either way – the sort is already performed for the ROW_NUMBER() and there’s no extra cost for adding an ORDER BY.
I’ll update the sample code to be, you know… right.
Thanks for posting this article, Jeremiah. It would be so nice if SQL Server offered a function or macro that would allow “punches” of dynamic SQL for situations like this. It’s still so very awkward and anti-DRY to have to do what you’ve suggested versus something like:
ORDER BY {{@SortField}}
Doesn’t it just seem a bit insane that there’s not a way to dynamically sort results in SQL Server without writing your query twice (or doing the dreaded SELECT *)? Even if the statement required something like “WITH OPTION REWRITEMACROS” or something…
Steve, I totally agree with that suggestion. Even if it came with a lot of warnings about possible poor performance. I have a lot of small recordsets (less than 10K rows) that need to be sorted by many different fields in the UI. ORDER BY @Variable would ease the coding tremendously.
If your results are that small, I suggest sorting in the application. It’s easy enough to do, and app server CPU is vastly cheaper than SQL Server CPU.
Interesting. Your third attempt, using the CASE in the ORDER BY is how I’ve solved this in the past. It was what seemed logical to me back in the old days and worked well. However, I’d never seen anyone slide the row_number up into the select list as a CASE and order by that. It looks like it would be inefficient to me, but I bet there’s a use for that technique some where.
Nice writeup.
Thanks, Steve.
This came about from messing around with dynamic sorting and trying to find ways to be slightly lazier about the way I wrote queries. I didn’t think it would work either, but it turned out that it wasn’t that bad after all.
I tried this on SQL2008R2 and the performance of the SQL is really bad….
It’s worse than executing the ordering on an non indexed nvarchar(500) column.
Hi nadav,
On SQL Server 2008 R2 (RTM), using AdventureWorks2008R2 I get nearly identical query plans to the plans I see from SQL Server 2012. The only difference seems to be because of cardinality estimates produced by data differences.
When I run the final “fast” sample and compare it against a plain order by, the plan costs are nearly identical (2.72105 vs 2.7179).
Could you provide some example code or more details about the poor performance you’re seeing?
The code I’ve used is at the end of the post (including the schema of the table)
I’m running this on windows XP SP3 with 4GB ram.
The sql is 2008R2.
The table has 241000 rows (total size 467.961 MB)
The computer is a test computer with nothing else running on it.
Ihe inner filtering (where TraceID<3800000) filters it to around 50000 rows and then I use the Row_Number() column to take the top 20000 rows.
Looking at results more closely, I see that the performance using case is same as the queries without its, that is the query runs just as quickly, but the COST of the queries with the case is MUCH higher.
I've executed all the queries in a simple sql window in the management studio and looked at the execution plan and I see that the queries that work directly on the indexed columns have 0% query cost relative to the whole query, the queries on the non index column have 14% query cost and the queries that use the case in the sort have 43% query cost each.
The query on the non indexed colunm have a clustered index seek with estimated cost of io:9/cpu:0.27 & a sort with estimated cost io:50/cpu:8
The queries with the case have a clustered index seek with estimated cost of io:9/cpu:0.27 & a sort with estimated cost io:198/cpu:8
Nadav
————————————–
The schema of the table is:
CREATE TABLE [dbo].[Traces](
[TraceID] [int] IDENTITY(1,1) NOT NULL,
[TraceTime] [smalldatetime] NOT NULL,
[App] [char](20) NOT NULL,
[Host] [char](20) NOT NULL,
[TraceType] [char](10) NULL,
[Remark] [nvarchar](500) NOT NULL,
CONSTRAINT [PK_Traces] PRIMARY KEY CLUSTERED
(
[TraceID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY]
— where on rn
select * from (select ROW_NUMBER() over (order by TraceID) as rn, TraceID,TraceTime,Remark from traces where TraceID<=3800000) as x
where rn<=50000
order by rn
select * from (select ROW_NUMBER() over (order by TraceTime) as rn, TraceID,TraceTime,Remark from traces where TraceID<=3800000) as x
where rn<=50000
order by rn
select * from (select ROW_NUMBER() over (order by Remark) as rn, TraceID,TraceTime,Remark from traces where TraceID<=3800000 ) as x
where rn<=50000
order by rn
DECLARE @SortOrder VARCHAR(50);
set @SortOrder = 'TraceID';
SELECT *
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY CASE @SortOrder WHEN 'TraceTime' THEN TraceTime END,
CASE @SortOrder WHEN 'TraceID' THEN TraceID END)
AS rn,
TraceID,TraceTime,Remark
FROM traces
where TraceID<=3800000
) AS x
where rn<=100
ORDER BY rn ;
set @SortOrder = 'TraceTime';
SELECT *
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY CASE @SortOrder WHEN 'TraceTime' THEN TraceTime END,
CASE @SortOrder WHEN 'TraceID' THEN TraceID END)
AS rn,
TraceID,TraceTime,Remark
FROM traces
where TraceID<=3800000
) AS x
where rn<=100
ORDER BY rn ;
Interesting. When I do the same thing (with no data), I get equal costs per plan. This is most likely due to stats on the underlying data that exist for you but not for me.
If you’re going to be dynamically sorting, it’s best to have indexes in place to support the sort. Otherwise, there’s no chance for good results. Especially when you’re using comparison operators in the query.
I do have indexs on the columns
Hi,
Could this be a good candidate to be a Dynamic SQL in order to accommodate, Paging + Bi-directional sorting of any returned columns?
Thank you,
Lester
You could certainly use this to accommodate paging or bi-directional sorting.
If you’re going to be doing a lot of sorting, re-sorting, and paging it might be better to store results in a middle-tier and perform the sort in memory in an application server after you retrieve the entire result set.
Hi Jeremiah,
Could that be a potential cause for concurrency issue and eventually performance issue right? I am assuming the unpaged resultset will be in Session.
Thanks
All of the above.
SQL Server does not cache results, so as you page through the data, SQL Server has to keep recalculating the results for delivery to the user. The cost of paging becomes more apparent the future into the results the user goes.
I’ve had a lot of luck just using a simple cache server like memcached or AppFabric Cache to hold results for pagination and re-sorting. We just stored a binary representation of the .net DataTable.
I’ve been using the ORDER BY CASE trick myself…I use it in a report so I can pass a parameter to get the top 10 rows by variable criteria. I think I tried it not expecting it to work, but just on the off-chance…was pleased to see it works!
“I learned that trying to be smarter than SQL Server can lead to pretty terrible performance.” –a lesson I continue to learn on a regular basis…somebody slap me before I use that index hint…
Interesting write up, especially for me as I quite often have to tackle dynamic sorting and paging for customers. While dealing with this very topic recently, I thought to myself –
“What if SQL is having to sort all that data – won’t that be expensive? Wouldn’t it be better to just sort the key?”
In my case, it was very expensive, so I changed to sorting just the key and saw massive speed improvements as I suspected, but only if paging is involved, else (in my case) the cost of post-sort lookups to get the data was higher than the cost of sorting the whole set.
Here is what I mean, using your query – rewritten to sort the key column, then join back to get the data with a 100 row “page” selection. On my laptop, this tends to perform about 30-50% quicker for this scenario.
SELECT x.rn,
s.SalesOrderNumber,
s.OrderDate,
s.DueDate,
s.ShipDate,
s.PurchaseOrderNumber,
s.AccountNumber,
s.SubTotal,
s.TaxAmt,
s.Freight,
s.TotalDue
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY CASE @SortOrder
WHEN ‘OrderDate’ THEN OrderDate
WHEN ‘DueDate’ THEN DueDate
WHEN ‘ShipDate’ THEN ShipDate
END DESC)
AS rn,
SalesOrderID
FROM Sales.SalesOrderHeader
) AS x
join Sales.SalesOrderHeader s
on s.SalesOrderID = x.SalesOrderID
where rn>30000 and rn<30100
ORDER BY rn ;
You can definitely run into interesting situations where pre-sorting can dramatically improve performance. When you have to perform sorting in the database, it’s worth it to investigate a number of different sorting techniques to make sure you’re using the best one.
I can see how your solution would work for improved paging – with the right set of indexes on a large enough table this would be very effective. In the case of AdventureWorks (which never should be used to judge anything) this performs marginally worse on I/O and produces the same plan cost as the “winner” in the main post.
Yep, “It Depends” is the only really dependable answer.
I used a very simple method for my scenario. I have the sorting criteria set in a separate table. My solution is like this:
The only thing to keep in mind is to specify column names in single quotes in case you are directly writing the logic in order by clause instead of using a varchar type variable. I compared two methods and found that cost of using a varchar type variable is lower.
I suppose this method should apply to your example in blog and other examples in comments section.
Guys, please let me know whether this approach works for you. Please let me know your suggestions regarding performance as well.
Thanks,
Deepak Khandelwal
Guys, sorry, its not working, i have to use dynamic sql.
Have you tried using OPTION (RECOMPILE) to see if you can remove the Sort phase from the plan, for fields that are already “pre-sorted” in an index.
That sounds like a great experiment for anyone with a copy of the AdventureWorks database!
In my situation I need to Allow a paged result with dynamic sorting and filtering.
In addition I need to know the total amount of rows that the filter resulted in.
to show Rows 1-50 of 356
How do I get the row count of the inner cte expression?
The most effective way to do this is in your application – load the results into a
DataTable, or similar, and apply counting and sorting as needed.If you insist on doing it the database, you can use
COUNT()and a windowing function. The downside to this approach is – if you have a large result set, you get to read the whole result set, not the first 50 rows… and you get to do it every time.I have a large datasets >300K rows each and that is why I don’t want to load it into my application. Plus this data is not static and I don’t want manage conflicts
My application calls the procedure which currently returns 2 tables
1) Info table, that contains total row count (needed so the application can request next page(s))
2) Result table, the page (x Row that match the users search / Filter)
The problem with my sql is that I am querying the data 2x,
Can this be done without scanning the table 2 times
sample sp:
ALTER PROCEDURE [dbo].[WebGridPageGet]
@Page int
,@Rows int
,@SortColumn nvarchar(50) = NULL
,@SortDir nvarchar(50) = NULL
,@Search nvarchar(50) = NULL
AS
BEGIN
SET NOCOUNT OFF;
DECLARE @TotalRows int
DECLARE @TotalPages int
DECLARE @PageIndex int
DECLARE @StartRowNumber int
DECLARE @EndRowNumber int
DECLARE @SearchString nvarchar(255)
DECLARE @SearchLike nvarchar(55)
SET @SearchLike = [dbo].[fnBuildLikeString](@Search);
SELECT @TotalRows = COUNT(*) FROM [SysWebDocInfoView_InFormDB_V23_WC_1] WHERE
(
(@SearchLike IS NULL)
OR
(
CONVERT(NVARCHAR,[Id]) = @Search
OR [Id] LIKE @SearchLike
OR [BusinessName] LIKE @SearchLike
OR [Title] LIKE @SearchLike
— .. MORE OF THESE HERE
)
)
SET @TotalPages = (@TotalRows / @Rows) + 1
SET @PageIndex = @Page – 1;
SET @StartRowNumber = (@PageIndex * @Rows) + 1
SET @EndRowNumber = (@PageIndex * @Rows) + @Rows
if(@EndRowNumber > @TotalRows)
BEGIN
SET @EndRowNumber = @TotalRows
END
SELECT ‘PageInfo’
,’DocInfo’;
SELECT @TotalRows AS TotalRows
SELECT * FROM
(SELECT *, CASE
WHEN @SortColumn = ‘Id ‘ AND @SortDir = ‘ASC’ THEN ROW_NUMBER() OVER ( ORDER BY Id ASC)
WHEN @SortColumn = ‘Id ‘ AND @SortDir = ‘DESC’ THEN ROW_NUMBER() OVER ( ORDER BY Id DESC)
WHEN @SortColumn = ‘BusinessName ‘ AND @SortDir = ‘ASC’ THEN ROW_NUMBER() OVER ( ORDER BY BusinessName ASC)
WHEN @SortColumn = ‘BusinessName ‘ AND @SortDir = ‘DESC’ THEN ROW_NUMBER() OVER ( ORDER BY BusinessName DESC)
— .. MORE OF THESE HERE
END AS RowNumber FROM [SysWebDocInfoView_InFormDB_V23_WC_1] WHERE
(
(@SearchLike IS NULL)
OR
(
CONVERT(NVARCHAR,[Id]) = @Search
OR [Id] LIKE @SearchLike
OR [BusinessName] LIKE @SearchLike
OR [Title] LIKE @SearchLike
— .. MORE OF THESE HERE
)
)
) AS PagedResult
WHERE
(RowNumber >= @StartRowNumber AND RowNumber <= @EndRowNumber)
ORDER BY RowNumber
END
Thanks,
David
Yes, this can be done. Read the second suggestion I gave you. It’s only 50% worse than what you’re doing now.
When I combine date column with varchar column I got the error message
Conversion failed when converting date and/or time from character string.
ROW_NUMBER() OVER (ORDER BY CASE @OrderBy WHEN ‘QuoteDate’ THEN QuoteDate
WHEN ‘VendorName’ THEN VendorName
END ASC )RowNumber
The problem is probably that when the sql server compiles the sql statement it assigns the CASE statement a return datatype based on the type of the first WHEN clause, NOT the WHEN clause that is actually evaluated so when you execute that sql it tries to convert VendorName to datetime which is why you get the error.
Ah, the joys of SQL 🙂
use tt
go
— create test table and inset into new values
/*
Create table dbo.TEST (ID_ACCO int, ID_OBJE int, ID_OBTY int)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(10,1,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(9,2,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(8,3,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(7,4,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(6,5,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(5,6,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(4,7,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(3,8,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(2,9,1)
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(1,10,1)
;
*/
———————————————————————
— Sort table using parametrs Column and DESC or ASC
declare @Column as varchar(20)
declare @Sort as varchar(20)
declare @Tab as table (ID_ACCO INT, ID_OBJE int, SORT int)
————— Coulmn name —————-
–Set @Column = ‘ID_OBJE’
Set @Column = ‘ID_ACCO’
—————- Sorting type —————–
–set @Sort =’Asc’
Set @Sort =’Desc’
Begin
— Crate query
With a
as (select
ID_ACCO,
ID_OBJE,
CASE When @Column=’ID_ACCO’ then ID_ACCO
When @Column=’ID_OBJE’ Then ID_OBJE End AS SORT
from dbo.TEST)
— insert query result (with) to temporary table @Tab
Insert into @Tab Select * from a;
— Select data from @Tab according selected Column and type of sorting
If @Sort=’Asc’
Select * from @Tab
order by SORT ASC
Else If @Sort=’Desc’
Select * from @Tab
order by SORT DESC
Else
Select * from @Tab
End
The problem with your example, aside from using a table variable with only 10 rows, is that this sort of IF logic is very naive. At compile time, both paths will be expanded and optimized for whichever variable you pass in. Check out my answer here for more information.
Hi,
You have right, your approach is faster but if we test it on 1000000 records in TEST table it cost 6 secound comparison to mine 9-14 secound (depending on selected paremeters) on my local computer using MS SQL EXPRESS ). Ofcourse if we want to see all thise recourds. My solution give you posibility to choose type of sorting using parameter therfore is heavier 🙂
If you know better idea how dynamically choose DESC or ASC sorting I will be grateful for the hint ?
— add record to TEST table
Create table dbo.TEST (ID_ACCO int, ID_OBJE int, ID_OBTY int);
DECLARE @i INT;
DECLARE @j INT;
DECLARE @k INT;
SET @i = 1;
SET @j = 1000000;
SET @k = @j;
WHILE @i <= @k
BEGIN
Insert into dbo.TEST (ID_ACCO, ID_OBJE, ID_OBTY) Values(@i,@j,1)
SET @i= @i + 1;
SET @j= @j – 1;
END;
—- First solution
declare @Column as varchar(20)
declare @Sort as varchar(20)
declare @Tab as table (ID_ACCO INT, ID_OBJE int, SORT int)
————— Coulmn name —————-
Set @Column = 'ID_OBJE'
–Set @Column = 'ID_ACCO'
;
SELECT
ID_ACCO,
ID_OBJE,
SORT
FROM
(select
ROW_NUMBER() OVER (ORDER BY CASE When @Column='ID_ACCO' then ID_ACCO When @Column='ID_OBJE' Then ID_OBJE End asc) SORT,
ID_ACCO,
ID_OBJE
from dbo.TEST
) a
Order by sort asc
— secound solution
declare @Column as varchar(20)
declare @Sort as varchar(20)
declare @Tab as table (ID_ACCO INT, ID_OBJE int, SORT int)
————— Coulmn name —————-
–Set @Column = 'ID_OBJE'
Set @Column = 'ID_ACCO'
—————- Sorting type —————–
–set @Sort ='Asc'
set @Sort ='Desc'
;
With a
as (select
ID_ACCO,
ID_OBJE,
CASE When @Column='ID_ACCO' then ID_ACCO
When @Column='ID_OBJE' Then ID_OBJE End AS SORT
from dbo.TEST)
Insert into @Tab Select * from a
If @Sort='Asc'
Select * from @Tab
order by SORT ASC
Else If @Sort='Desc'
Select * from @Tab
order by SORT DESC
This is the approach I use, it gives me the option to sort ASC and DESC and have the row number for paging. This approach is Jeremiah Peschka approach but without the subquery and adding Mihai Foltache suggestion to use multiple CASE otherwise you will have an error when you combine different data type on the case statement. I use this approach for a table with 700,000 row and works just perfect with excellent performance.
DECLARE @SortCol VARCHAR(50) = ‘OrderDate’;
DECLARE @SortDir varchar(50) = ‘desc’
SELECT ROW_NUMBER() OVER (ORDER BY CASE WHEN (@SortCol = ‘OrderDate’ AND @SortDir = ‘asc’)
THEN OrderDate END ASC,
CASE WHEN (@SortCol = ‘OrderDate’ AND @SortDir = ‘desc’)
THEN OrderDate END DESC,
CASE WHEN (@SortCol = ‘DueDate’ AND @SortDir = ‘asc’)
THEN DueDate END ASC,
CASE WHEN (@SortCol = ‘DueDate’ AND @SortDir = ‘desc’)
THEN DueDate END DESC,
CASE WHEN (@SortCol = ‘ShipDate’ AND @SortDir = ‘asc’)
THEN ShipDate END ASC,
CASE WHEN (@SortCol = ‘ShipDate’ AND @SortDir = ‘desc’)
THEN ShipDate END DESC
) AS rn,
SalesOrderNumber,
OrderDate,
DueDate,
ShipDate,
PurchaseOrderNumber,
AccountNumber,
SubTotal,
TaxAmt,
Freight,
TotalDue
FROM Sales.SalesOrderHeader
Great! I like it 🙂
Yesterday I tried to do it based on your advice and I did this. Execution plan is longer and has 2 sorts but total execution time is similar to your example (1000000 records about 6-8 secound).
Look at this:
—————————————————— My proposition
declare @Column as varchar(20)
declare @Sort as varchar(20)
declare @Tab as table (ID_ACCO INT, ID_OBJE int, SORT int)
–Set @Column = ‘ID_OBJE’
Set @Column = ‘ID_ACCO’
–Set @Sort = ‘Desc’
Set @Sort = ‘Asc’
SELECT
ID_ACCO,
ID_OBJE,
SORT
FROM
(select
Case When @Sort=’Asc’ then
ROW_NUMBER() OVER (ORDER BY
Case @Column When ‘ID_ACCO’ Then ID_ACCO
When ‘ID_OBJE’ Then ID_OBJE END Asc)
When @Sort=’Desc’ then
ROW_NUMBER() OVER (ORDER BY
Case @Column When ‘ID_ACCO’ Then ID_ACCO
When ‘ID_OBJE’ Then ID_OBJE END Desc) END AS SORT,
ID_ACCO,
ID_OBJE
from dbo.TEST
) a
Order by sort
——————————————————- Your las exsamlpe based on my table
declare @Column as varchar(20)
declare @Sort as varchar(20)
declare @Tab as table (ID_ACCO INT, ID_OBJE int, SORT int)
Set @Column = ‘ID_OBJE’
–Set @Column = ‘ID_ACCO’
Set @Sort = ‘Desc’
–Set @Sort = ‘Asc’
SELECT
ID_ACCO,
ID_OBJE,
SORT
FROM
(select
ROW_NUMBER() OVER (Order by
Case When @Sort=’Asc’ And @Column=’ID_ACCO’
then ID_ACCO END Asc,
CASE When @Sort=’Desc’ And @Column=’ID_ACCO’
Then ID_ACCO END Desc,
CASE When @Sort=’Asc’ And @Column=’ID_OBJE’
Then ID_OBJE END Asc,
CASE When @Sort=’Desc’ And @Column=’ID_OBJE’
Then ID_OBJE END Asc) AS SORT,
ID_ACCO,
ID_OBJE
from dbo.TEST
) a
Order by sort