How to Think Like the SQL Server Engine: Adding an ORDER BY
We started out the How to Think Like the Engine series with a simple query with a WHERE clause:

Now let’s add an ORDER BY:
|
1 2 3 4 |
SELECT Id FROM dbo.Users WHERE LastAccessDate > '2014/07/01' ORDER BY LastAccessDate; |
Here’s the updated plan – note that the query cost has tripled to $17.72 Query Bucks. Let’s dig into why:

We read the plan from right to left, hovering our mouse over each operator. Each operator is kinda like a standalone program that has its own dedicated work to do, and produces a specific output.
The first thing that happens is the Clustered Index Scan.
At the top right, the clustered index scan is exactly the same as it was in the last query. Hover your mouse over that and there are a lot of juicy details that we didn’t really dig into before:
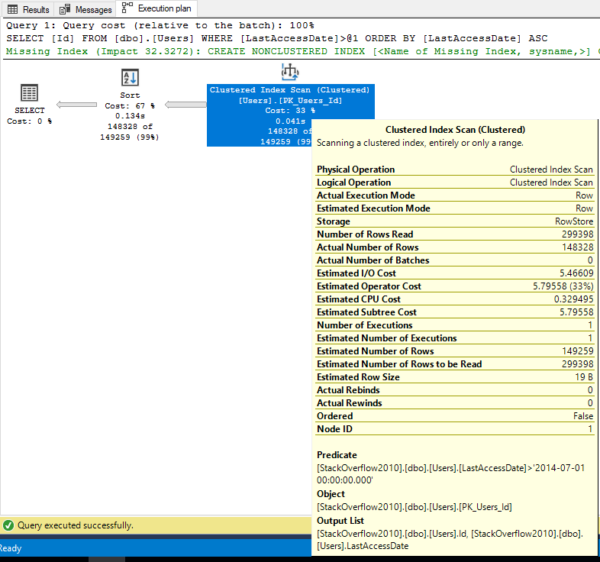
- Predicate: the clustered index scan mini-program is only going to return rows where the LastAccessDate > ‘2014-07-01’. (Pretty nifty how it changed the date format and added the time, right?)
- Estimated Number of Rows: 149,259
- Estimated Number of Rows to be Read: 299,398 (we have to scan the whole table to find the people who match)
- Output List: Id, LastAccessDate (because upstream of this mini-program, other mini-programs are going to need both Id and LastAccessDate. Specifically, the Sort operator – which happens next – is going to need to sort all these rows by LastAccessDate.)
The data flows out of this scan operator, and flows into the next one: Sort.
The second thing that happens is the Sort.
The sort’s input is the 148,328 rows of Id & LastAccessDate that came out of the Clustered Index Scan, and they’re not sorted in any kind of order – but our query asked for them to be ordered by LastAccessDate. That’s where the Sort’s work comes in. Hover your mouse over it to see what’s happening in that mini-program:

A few points of interest:
- Order By (down at the bottom): the main goal of the sort
- Estimated Number of Rows: 149,259
- Estimated I/O Cost: $0.01 (because there’s not much I/O to do if you’re sorting 150K rows)
- Estimated CPU Cost: $11.7752 Query Bucks (because sorting is mostly CPU work)
But note that those estimates above are all based on 149,259 rows. If way more rows came in (or less), then our actual work would have been way more (or less.) This is a good time to stop and mention that you don’t see Actual Cost numbers here in Query Bucks: SQL Server doesn’t go back and re-cost stuff after the work has been completed. Anytime you see a cost – even on an actual plan – it’s just an estimate that was done before the query started. Just like you, SQL Server doesn’t later confess just how over budget or late its work was.
So why did the query cost triple from $6 to $18?
It all comes back to the $11.7752 Query Buck cost of the Sort operator, which is brand new in this plan. Sorting data is hard work.
I jokingly say that SQL Server is the world’s second most expensive place to sort data – second only to Oracle. Next time someone complains about the $7K per core cost of SQL Server Enterprise Edition, remind them that Oracle is $47K per core. $47K. Hoo boy.
If you need to sort data, try doing it in the app tier instead. Developers are really good about scaling out application work, and their app servers don’t cost $7K per core. I’m all about going to bat for my developers to get them more & faster web servers because those are easier/cheaper than scaling out sorting in SQL Server. If the query doesn’t have a TOP, then it probably shouldn’t have an ORDER BY.
What’s that, you say? You’ve never heard Microsoft dispense that advice?
Microsoft, the company that charges $7K per core to do your sorting for you? They haven’t told you about that? Huh. Must have been too busy about telling you how you can now do R, Python, and Java inside the SQL Server, all at the low low price of $7K per core. Funny how that works.
And the more columns you add, the worse it gets. Next up, let’s try SELECT *.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
Another great article. But I disagree that sorting should be done in the application tier. As the dude that writes that web application code, I often find that a given feature (and it’s database queries) has evolving requirements.
First, we do something simple like bringing back all the data in the table and letting the application page it and sort it. Then the data grows and the performance slows. Then someone complains and I get to go in and modify the code to deal with the paging and sorting.
As I’ve gotten more grey hairs, I’ve learned to put the paging and sorting into the database in the first place if I suspect the data is going to grow over time. The application has to be retested and redeployed to all the environments with their corresponding planning and outages. Considering my time and cost to do this, $7K/core doesn’t seem so bad. 🙂
Kevin – oh I agree, if you’re doing pagination, that belongs in the database tier. But if you’re only doing ORDER BY without a TOP (like I’m talking about in the post, and I try to make that clear), then it needs to be in the app tier.
Fun read and very well put!
Yep! I remember this was one of the many takeaways I got from our class in Portland. So recently we stopped using ORDER BY clauses and sort on the front end. Real world example: in our case, we code in ASP.NET on the front end and use DevEx Gridviews for tabular data. We used to but stopped passing ORDER BY clauses to SQL Server in a recent release and instead use a function that DevEx provides and we sort the data at the presentation layer. So far, so good.
And if my SQL server is on the same machine as the web server? Should I still sort on the front end or not?
Given that SQL Server Standard Edition costs $2,000 per core and Enterprise Edition costs $7,000 per core, it’s fairly unusual to run your web server on the same server – but if you don’t care about lighting money on fire, by all means, go for it. 😉
Internal licenses can be “free” if you have certain MPN competencies ?
Oh sure, as long as you’re not paying for SQL Server, it doesn’t really matter much – but keep in mind that if you get a job anywhere else, you’re going to be in for a rough surprise.
It also matters for security. Databases generally need different security and access configuration compared to web servers, so it’s better for them to be on a separate server. Note that PCI-DSS explicitly requires database servers and web servers to be implemented on separate servers (or separate virtual servers).
Ignoring the security and licensing issues with this, personally I would rather maintain them as separate servers. This makes it much easier to diagnose performance issues.
@Karel
>> And if my SQL server is on the same machine as the web server? Should I still sort on the front end or not?
Yes, because if you were able to separate SQL Server and Web server into 2 separate “machines” then you’re all set. That’s just an infrastructure change. You could also add memory to the existing machine but Brent’s argument that you’re “burning money” has merit. That said, many customers of ours choose to run IIS and SQL on the same machine by choice and who are we to argue 🙂
Interesting idea about sorting on the app server. I wonder if ORMs implemented that advice?
More specifically, .NET Entity Framework from Microsoft?
Oh wait, never mind.
If I could give you all of my Internet points for today, I would, hahaha.
To nudge EF to sort in the app server, just add .ToEnumerable()
Thank you for a great series posts!
> I jokingly say that SQL Server is the world’s second most expensive place to sort data – second only to Oracle.
How about Vertica and other MPP databases? : )
They haven’t met Larry’s sales team. 😉
You make a good point if the sort is unrelated to the criteria of the query, let alone if the sort field/s can change dynamically.
However, if you are doing a selection based upon the field that you are sorting on, surely you should bite the bullet and build an index on that field.
That would alleviate both the initial Clustered Index Scan and the Sort.
This does bring to mind one question that I have… Many of the Index recommendations shown by sp_BlitzIndex are functionally bogus – they are duplicates with different or additional Include fields. How much overhead is there really in skipping the Includes altogether and does this calculation differ when the Table is small enough to keep in memory or if you are running SSDs instead of spinning platters ?
Simon – stay tuned in the series! You’re about to learn a lot – you’ll enjoy this quite a bit.
Sadly, in my experience end users rarely sort on a clustered index (which for our system is a less than meaningful identity column), its usually on some date or other data that isn’t related to the CI.
“If the query doesn’t have a TOP, then it probably shouldn’t have an ORDER BY.”
Printed!