My Transaction Log File Is How Big?
2 Comments
How bizarre
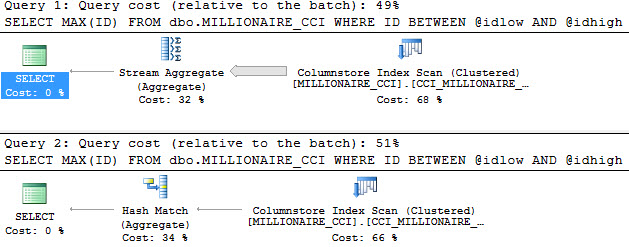
So there’s this funny thing about SQL Server: many units of measure boil down to 8k pages. That’s the size of a data page, so when you measure reads, or size, sometimes the only thing you can do is convert that to MB or GB, or if you’re super lucky, TB.
But transaction logs don’t have pages. Not 8k, not any other kind. Log files are full of Virtual Log files, or VLFs. These VLFs hold transactions, and can vary in size if you have your logs set to grow by a percentage.
Which brings up a curious bit of documentation for sys.database_files and sys.master_files.


Options to convert
All of these queries give me correct results. The math has been around forever in a billion blog posts, and it’s not that interesting. Dividing by 128 or multiplying by 8 and then dividing by 1024 will get you to the same place.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT df.file_id, df.name, df.type_desc, df.physical_name, ((df.size * 8) / 1024.) AS [size_mb], df.max_size FROM StackOverflow.sys.database_files AS df; SELECT mf.file_id, mf.name, mf.type_desc, mf.physical_name, ((mf.size * 8) / 1024.) AS [size_mb], mf.max_size FROM sys.master_files AS mf WHERE mf.database_id = DB_ID('StackOverflow') SELECT df.file_id, df.name, df.type_desc, df.physical_name, ((df.size / 128.)) AS [size_mb], df.max_size FROM StackOverflow.sys.database_files AS df; SELECT mf.file_id, mf.name, mf.type_desc, mf.physical_name, ((mf.size / 128.)) AS [size_mb], mf.max_size FROM sys.master_files AS mf WHERE mf.database_id = DB_ID('StackOverflow') |
Where does it come from?
Running sp_helptext on sys.database_files and sys.master_files sheds some light on things. Namely, that it doesn’t want light shined (shone?) upon it.
|
1 2 3 4 5 |
sp_helptext 'sys.database_files' GO sp_helptext 'sys.master_files' GO |
Trying to query any of these system views will fail miserably.

Really, the only hint is sitting in a function that… you guessed it, we don’t have access to!

What was the question?
Given the amount of potential confusion that it could cause, it’s an odd choice for Microsoft to store log files in sizes apparently converted to 8k pages. It makes querying the data a bit easier, which I appreciate, and perhaps it’s just the documentation that could use an update.
Thanks for reading!