Performance Tuning
Index Scans: Not Nearly As Bad As You Might Think
Using our good old buddy the StackOverflow demo database, let’s look at the Users table. I want to get the first 10 users in the table ordered by Id, the primary clustered key, which is an identity field.
Here’s the actual execution plan:
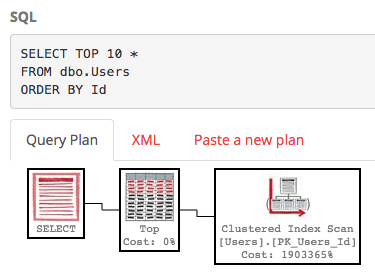
Ooo – clustered index scan – that’s bad, right?
Not so fast. Click on the plan to view it in PasteThePlan.com, and hover your mouse over the Clustered Index Scan:
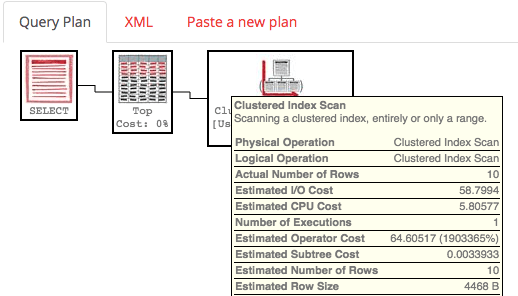
We didn’t scan the whole clustered index – just part of it.
And you’ve always heard seeks are great, right?
Let’s test that out too with a very similar query:
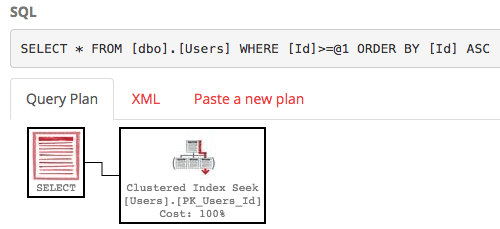
That query plan gets a clustered index seek. Perhaps we’ve been told that seeks are better than scans. So is this query less impactful than the first query? Absolutely not – this query takes a heck of a long time to run, and if you click on the plan and hover your mouse over that seek operator, you’ll see a lot more than 10 rows get returned.
The only difference between seeks and scans: where you start.
Seek means we know the starting point’s value. The starting value might happen to be the first row in the table, but that’s irrelevant. Seek means we know the value – in the case of our latter query, we knew the Id would be 1. Sure, as human beings, you and I know that we started our identity field with a value of 1 – but SQL Server doesn’t know that, nor does it know for sure that you never set identity insert on, and backloaded a bunch of data with negative identity fields.
Scan means we start at one end of the index, regardless of what value we find there.
Neither seek nor scan has anything to do with where we stop reading. We can do a scan that only reads a few 8KB pages, and we can do a seek that reads the entire table.
This has two big performance tuning implications. First, when you see a plan, you can’t just look at seek vs scan. Second, when you read the index usage DMVs, you can’t judge efficiency based solely on seek vs scan.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
The second query isn’t equivalent as it doesn’t have the TOP 10 clause..
That’s the point. They’re not the same. You can get a great plan with a scan, and a seek doesn’t mean it’s light weight.
It’s comparing apples and pears.
TOP 10 is a special case – without ORDER BY, it will always be executed as a table scan. In your example, the table is stored as a clustered index and not as a heap. If the table was stored as a heap, it will also be executed as a table scan and will stop when 10 rows is read. So your example DOES NOT show anything about scanning or seeking in an index, but about table scan contra using an index. Only an example of confusion!!
> It’s comparing apples and pears. TOP 10 is a special case – without ORDER BY, it will always be executed as a table scan.
Uh, no, that’s bananas. Try this:
SELECT TOP 10 * FROM [dbo].[Users] WHERE [Id] >= 1
That gives you a clustered index seek. Enjoy your learning in the fruit aisle! And just on a personal note, whenever you find yourself using the words “always” or “never,” stop to think for a second: “If I believed the opposite, how would I go about proving it?” Then try that test.
You must distinguish between table scan and using an index. If a table scan is executed, the query plan will show clustered index scan if the table is stored as a clustered index and only use the word table scan if the table is stored as a heap. But the index is not used as an index in your example, so the operation is a table scan. Your new statement have a predicate, so it’s an quite different situation. If a statement with TOP have a predicate or ORDER BY an index can be used! Clustered or Nonclustered. So it depends of the statement.
Carsten – you said “TOP 10 is a special case – without ORDER BY, it will always be executed as a table scan.”
You’re still defending that despite proof to the contrary. We’re going to have to agree to disagree. Thanks for stopping by, though!
On similar topic seek vs scan, which one is more effective if we are joining 2 tables using inner join and mathing record is available for all rows, so whole table need to be read.
Karan – your best bet is to go ahead and try it to see. The goal with these posts is to show you how to measure the differences, and then you can try experiments on your own servers (and with the Stack database if you like.)
I tried AdventureWorks2014 database on Sales.SalesOrderHeader, I found the following 2 queries have the same IO Logical Read, slightly difference on time cost. I thought the first one would read more IO pages as it needs to go through the index root & intermediate pages to position the given SalesOrderID,
set statistics io on; set statistics time on;
select * from Sales.SalesOrderHeader where SalesOrderID >= 43659 — the first value of SalesOrderID
select * from Sales.SalesOrderHeader
Both queries would use the B-Tree of the index, that’s why you don’t see a difference. What you’re expecting from the second query is called “allocation order scan”. It has a couple of extra requirements. Check out this great article by Paul White
https://sqlperformance.com/2015/01/t-sql-queries/allocation-order-scans
What a great article, it explains very well about B Tree Scan & IAM Driven Scan.
Thank you.
LOL YOU ARE A NOOB WHO SELECTS * FROM USER TABLE
YOU CAN PASS EXECUTION PLANS TO STORED PROCEDURES NOOB
As Wolfgang Pauli would say, you’re not even wrong.