[Video] Office Hours 2017/06/14 (With Transcriptions)
This week, Brent, Erik, Tara, and Richie discuss setting up an archive process, CTEs vs temp tables, deadlocks, alternatives to replication, Erik and Brent’s pre-con for this year’s PASS Summit, and more.
You can register to attend next week’s Office Hours, or subscribe to our podcast to listen on the go.
Enjoy the Podcast?
Don’t miss an episode, subscribe via iTunes, Stitcher or RSS.
Leave us a review in iTunes
Office Hours Webcast – 2017/6/14
How should I archive data?
Brent Ozar: Alright, we’ll go ahead and get started. So James says, “do you know any good blog posts on setting up an archive process?” And if you don’t have good blog posts, I would say what are some of the lessons you’ve learned around setting up an archive process?
Erik Darling: Batching.
Brent Ozar: Go on…
Erik Darling: Batching is super important with the archive process, especially if you’re not using, sort of, table partitioning, where it’s easy to swap things in and out, or if you’re not using partition views where, like, you sort of have free reign to knock a table out if you don’t want the data in it anymore. If you don’t feel like dealing with it then you have to be really careful, kind of dealing with, sort of, one giant monolithic table, that you don’t lock the whole thing down trying to delete a few hundred thousand or million rows at a time. You kind of want to break that into smaller bites.
Brent Ozar: The thing that I didn’t ever understand until, I don’t know, I started doing the whole consulting thing was the whole lock escalation process.
Erik Darling: Yeah, it’s no fun.
Brent Ozar: I’m just like, I’m only deleting 15,000 rows, you know, what’s the big deal?
Erik Darling: Why do I need a table lock? Oh…
Brent Ozar: Yeah, and when there’s like five million rows in the table, 50 million rows in the table, what’s the big deal? Tara, what about you, what other lessons have you learned along the way with building an archive process?
Tara Kizer: I mean databases that I’ve supported have had to, maybe not archive the data, but purge the data based upon whatever the data retention policy was for customers. And, you know, these systems have existed since SQL Server 2000, and it was always just some kind of delete process, but batched, you know. Definitely batching, you know, while loop and delete top whatever. But, for me, if it were a new system, I’d be putting table partitioning or partition views in place right off the bat because I don ‘t want to have to put those in place later on when the database gets bigger, because it’s harder to put in place later. So start off with it, even if you don’t think your database is ever going to be big. I want to start avoiding the deletes and having to – most of the systems I have supported have been 24/7, you know. Maybe there’s a slower period, but it’s still – there’s users using the system and those deletes are just problematic; even in small batches. Or it would be because you do such a small batch, your job ends up taking hours because it’s only doing a little bit of work at a time, so it starts creeping into the busy times.
Brent Ozar: I would say, another thing I’d recommend with archiving is, if you can archive at certain days and times – say it’s Sunday at 10pm, if you can only archive at that one time, which is awesome, after you’re done archiving, put the database in read only mode. The other database where you’re archiving to, if you have the wonderful luxury of being able to archive to a different database, seal that database as read only, and that’s when you take your backup. You don’t have to backup that database again until your next round of archiving hits. Granted, that’s more technical data 0:02:43.2], It’s more work that you got to go take on, but when you start to grow to large sizes of databases, it’s totally awesome.
How is “Michaella” pronounced?
Brent Ozar: Ah man, Michaela, you got to send me an instruction on how to pronounce your name, because I’m going to see you all the time in here, you’re a faithful listener…
Tara Kizer: It’s usually Michaella.
Brent Ozar: That’s what I thought too…
Erik Darling: But then last week he said Michaella, something else, and she said you got it right, but we didn’t know which one it was for.
Brent Ozar: Like a Hawaiian kind of thing. Michae-la [crosstalk] there we go. See, the thing is Michaella, I’m not going to remember next week.
Tara Kizer: He can’t even say my name right, so you have no hope.
Brent Ozar: I literally had – when Tara started I literally put a Post-it note on my screen that said “tear a piece of paper”, because that’s the instruction that she gave me on how to pronounce her name.
Tara Kizer: That’s what people teased me for in school.
Brent Ozar: And it works. So Michae-la piece of paper, I might be able to remember that.
What’s better, CTEs or temp tables?
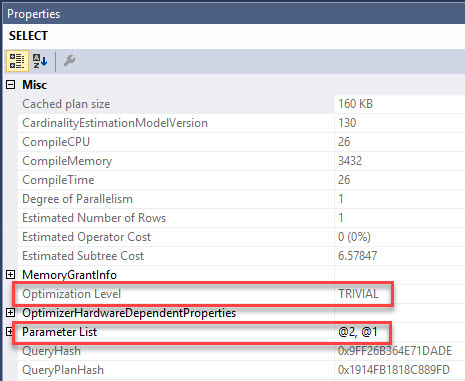
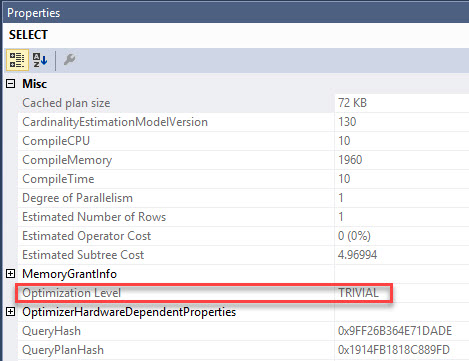
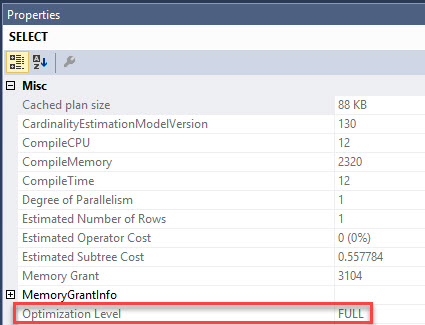
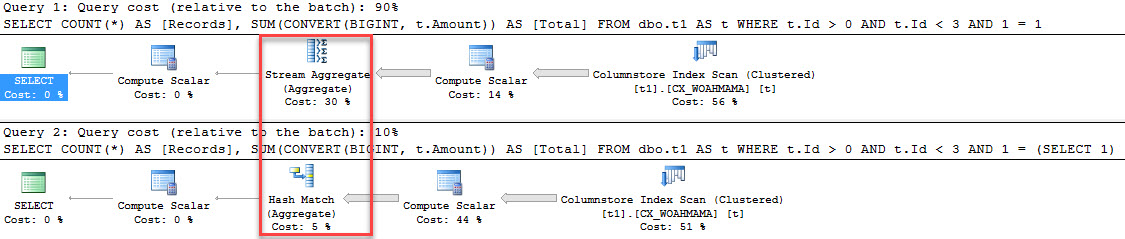
Brent Ozar: Michaelle says, “CTEs versus temp tables; I notice that on SQL 2016 Service Pack one that the CTE is using indexes from the table…” which might imply that maybe the temp table is not. So Erik, speaking of your T-SQL Level Up level two, I believe you talk about CTEs inside there.
Erik Darling: Oh I sure do. I think I talk a little bit about temp tables as well. So CTEs are okay for certain things. I think what you’re looking at is, is there a performance difference? Well the CTEs can use the base tables and they can use any indexes you have on the base tables. Whereas when you stick stuff into a temp table, you’re responsible for indexing that temp table. CTEs have always been able to use indexes because they’re accessing the base tables in the query. I think the main difference that I would put between them is that CTEs don’t materialize, whereas temp tables do. So if you, you know, run a CTE, you’re just essentially running a query and you can use the results of that query and, you know, anything after that. Whereas temp tables, you can stick data in there and then you can query them all day long.
Brent Ozar: And the other thing I would say is, if you know you’re going to reuse something 50 times, temp tables make so much sense there.
Erik Darling: Because there’s a weird quirk with CTEs where if you – the more times and, like you know, subsequent SELECTs that you join to a CTE, the more times that syntax has to execute. So if you, you know, you can just write a simple mockup of this. I think I actually have a blog post about it; I’ll find the link. Much easier than explaining it…
Brent Ozar: And it seems so obvious, when you look at the query I’m like, I only wrote the CTE once, shouldn’t you just execute it? It’s like some kind of sub-query, you just execute against once and then everything gets joined to it. Michaella – see, I got it right there Michaella, and the reason why is I left it on the screen where your answer was. Michaella says “yes, the CTE is called eight times”. Yeah, that’s one of those examples where it might make more sense to do a temp table.
Erik Darling: Hang on, I’ve got a link for coming up for you then Michaella. I’m going to say it as not Michelob. That’s how I’m going to remember it.
Brent Ozar: Oh my goodness.
Tara Kizer: But, you know, if the CTE is recursive, then if you switch that to a temp table, you’re having to update that temp table, right, in order to achieve the same recursiveness?
Brent Ozar: And then recursive CTEs have their other problems too, which is, don’t those ones go single threaded?
Erik Darling: Well the recursive part runs serially. Anything on the outside can go parallel; it’s funny.
What’s an alternative to replication?
Brent Ozar: James says, “what is…” Oh Richie’s here. James says, “what is an alternative solution besides replication?” He hates it.
Erik Darling: Buy a printer.
Tara Kizer: Do you have Enterprise Edition? That’s always my first question, because if you don’t, replication is the right solution, in my opinion, for reporting; if you’re asking about reporting.
Brent Ozar: Or log shipping…
Tara Kizer: I hate log shipping as a solution for reporting.
Brent Ozar: What?
Tara Kizer: Well because as far as – if you can put a delay in your restores, log shipping’s a good solution, but every single time that transaction log has to be restored, it kicks out the reports, and generally speaking you’ll have long running reports that could take a couple of hours to run; so you have to have a delay in your restores. And the systems that I’ve supported cannot have that long of a delay in the data, you know. Even just the latency that’s caused by say the archival process is problematic for the systems that I’ve supported. Or rebuilding indexes causes a lot of latency, so log shipping delay – it just depends on your company, of course. But if you have Enterprise Edition, I’d go for a different solution.
Brent Ozar: What would be that solution?
Tara Kizer: I’d go with availability groups with a readable secondaries.
Brent Ozar: it’s so much easier – it doesn’t matter if the database changes, it doesn’t matter if people change – if they add 50 tables tomorrow, if they drop 50 tables tomorrow, AGs are just going to work.
Tara Kizer: one of the drawbacks with AGs though is that in transactional replication, a lot of times your reporting solution would have different indexes because you just didn’t need those on the OLTP side, you needed more indexes on the reporting solution. That’s not possible in AGs; you’re stuck with putting all of your objects, tables, indexes, everything has to go on the writable side so that the readable side has it. It’s a big drawback and if you do a synchronous readable secondary, then that can cause performance issues to the writable side. So you may want to do asynchronous where there’s some latency.
Brant Ozar: You can have different amounts of data on both sides, for example. You cannot replicate deletes over to your secondary, so then that you can keep forever history over on your replication subscribers. Pretty slick stuff.
How do I resolve deadlocks?
Brent Ozar: Uday says, “do you guys have any recommendations or blog posts on how to approach resolving deadlocks?”
Tara Kizer: Only thing I can think of is anything Jonathan Kehayias writes, you know. He’s the deadlock expert, that I know about at least, you know. I’ve attended a deadlock presentation he did at PASS a few years ago; it’s good information. It’s a really complicated topic. If there’s anyone who has a blog post out there, it would probably be him. They’re not fun to troubleshoot – I know he thinks it’s fun, but most of us really want to stay away from that. I’ve had to do significant deadlock troubleshooting where just one stored procedure would take like three weeks to figure out because it was just – the stored procedure wasn’t necessarily complex, but understanding everything else that went into it, it was hard to figure out. On systems that I’ve supported where I know what the application can do, I’ve recommitted snapshot isolation level to help reduce deadlocks and blocking, but not all systems can support that.
Erik Darling: And the other thing with RCSI is that if you’re dealing with dueling write operations, then you don’t get much dice out of that. And enabling snapshot isolation to deal with, you know, dueling writes is complicated. [crosstalk] Yeah, you have to have all this crazy error handling and…
Brent Ozar: I have it as a bold point on a slide, you can use this for updates, any questions? Okay no, great, moving on. I just kind of cheat on deadlocks. So what I would do is I would run sp_BlitzIndex. With sp_BlitzIndex, it gives you this warning about aggressive indexes, meaning indexes that have had a lot of lock waits on them. This isn’t smoking gun proof that it’s tied into your deadlocks, it’s just that in the kinds of places where I see aggressive index warnings, those are usually the tables that are involved. And then I’ll just look at what are the right non-clustered indexes to add into this scenario and maybe do I have – one of two things is happening, either I have way too many indexes and updates are taking forever to lock all of them, or I don’t have any. Like there’s a clustered index on a table and every time I’m trying to do an update I’m locking the whole honking table.
I’d also say that this is a great time for monitoring software too. If you have a SQL Sentry performance advisor, or what do they call it, SQL Sentry One? Sentry One SQL Sentry for SQL Server Sentry… whatever. Idera SQL Diagnostic Manager or Quest Spotlight, they will all send you emails with the deadlock graph every time deadlocks occur. I’m not saying that makes it easy.
Tara Kizer: I had performance advisor at my last job and that three week stored procedure – it took three weeks because we were doing load testing, trying to simulate production load to cause the deadlocks to happen, because you can’t necessarily replicate this in your test environment, dev environment. You need a production load on it, so it took us a while, plus I was also working on other things. But I had the deadlock graph, I’m just like, okay. You know, so I knew what indexes were involved and I knew what processes are involved, I was like oh [crosstalk]…
Erik Darling: Then the other SSMS window…
Tara Kizer: Yeah, and this is – they use NOLOCK like it was the turbo button, you know, because this was implemented before I joined the company. But NOLOCK was everything and it still is deadlocking.
Erik Darling: You know, if you don’t have a monitoring tool, what – I would probably just fall on the sword and fire up extended events to catch deadlocks, because you get the whole deadlock graph…
Tara Kizer: It’s pretty low, you know, it doesn’t use a lot of resources when it’s just – you know, it fires after it happens. It’s not like you’re gathering execution plans, which is a major hit. [crosstalk]
Brent Ozar: Lou Fritz says, “Kendra Little has a great free session on deadlocks.” I totally forgot about this. So if you go to SQLworkbooks.com, this is Kendra’s new site for training courses, and she has a course that’s free right now. She may end up charging for it later, so if you want it, I would go sign up for it now, look at her trouble shooting blocking, locking and deadlocks for beginners.
Tara Kizer: I might even check that out, except I hate deadlocks; it’s a tossup. Do I really want to learn more? I do want to learn from Kendra, she’s a great presenter, you know.
What’s up with licensing?
Brent Ozar: When we first started carving up our video courses – our in person courses, Jeremiah, Kendra and I were carving up modules, like which ones of us were going to tackle which courses. And one of them was licensing, where like we have to have licensing in the senior DBA class and all of us made the same face that you did. All of us were like screw that, and I lost the rock paper scissors. And now I love licensing…
Tara Kizer: Oh good.
Brent Ozar: Well I had to spend like three weeks of my life researching licensing to write training decks. Now I’m like, it’s so cool.
Erik Darling: Learning to love licensing.
Tara Kizer: It’s funny about licensing, the Microsoft employees don’t even understand the licensing. They will tell you, you need to buy licensing for this server, and it ends up being completely false, you now, it’s just a salesperson trying to get you to buy more licenses; but they don’t understand it either. So you pull the legal documents and say, no right here it says I don’t have to.
Erik Darling: Yeah, they just hope you won’t do that.
Tara Kizer: Exactly.
Erik Darling: No, no you need licenses for that.
Richie Rump: I just always installed dev edition, and I’m good.
Brent Ozar: Says the guy who’s doing all of our production work…
Erik Darling: No one ever checks. They have so many customers, what are the odds? It’s like cigarettes, what are the odds? …
Brent Ozar: Oh god, this is why our company’s going to go down the drain, people, you’ll remember this moment.
Tara Kizer: You know what’s funny, two jobs ago I was assigned the licensing task and it was about a month before I left my job because…
Brent Ozar: It’s going to take me about 35 days.
Richie Rump: Now, you leaving has nothing to do with that licensing thing does it? Oh no, of course hot. Oh no…
Brent Ozar: Can you hand over the work that you’ve gotten done so far? Oh my dog ate it, oh dang, I had a hard drive crash…
Erik Darling: There was a printer jam and that was it.
Richie Rump: I lost my 3.5 floppies, it was here somewhere. I’m missing floppy 35 of 35 [crosstalk]
Tara Kizer: Installing Windows NT 351 on floppies, there was like 40 or something.
Brent Ozar: Yes, I remember signing up for a Windows beta, just so I could get 30 some free floppy disks. Like this is awesome, they’re just going to give them to me?
Erik Darling: Free storage.
Introducing our first-ever podcast sponsor
Brent Ozar: So we’ve come to a point in the podcast where – we’ve never really wanted to take ads on the podcast, but we’re going to go and start something new. We always wanted to keep it purely educational, but Microsoft came to us and they said, hey, you know what? There’s some parts of SQL Server that just don’t get the attention that they deserve, and we want to start publicizing these parts of SQL Server so that people can get more mileage out of them. So with that in mind, I’d like to introduce our first podcast sponsor.
Now we’re not perfect. All of us have our little individual quirks, we don’t highlight the right things in the script when we go to execute. We write things we didn’t really mean to intend. Sometimes we import the wrong data or sometimes we just code a really crappy stored procedure that has the wrong impacts that we don’t want. You don’t want to redefine all your table from scratch.
Tat’s why our podcast today is brought to you by the DELETE command. The DELETE command doesn’t judge. Whether it’s a single row or thousands, DELETE is there for you in your darkest hours to hide all of your mistakes. DELETE is there when you need to hide the bodies.
So remember, when you’re in a dark place, there’s always the DELETE command. So thanks very much to the DELETE command for being the first sponsor on our webcast.
Erik Darling: A subsidiary of Truncate co…
Brent Ozar: A subsidiary of Truncate Incorporated…
Richie Rump: Yeah don’t use those crappy WHERE clauses, they tend to foul things up, so…
Brent Ozar: Well it’s a performance tuning technique; the WHERE just slows you down. WHERE would require you to use an index.
Erik Darling: It’s complicated, there’s logic, you have to think about them. Who wants to do that? I don’t have time for that.
How do I preserve row order during ETL?
Brent Ozar: So Ben says, “when we’re using SSIS and we’re importing from a flat file, can the identity column in the destination table ensure preservation of original order of rows in the source file?” Oh you’re getting tricky. Am I the only one who’s done this? Judging by thee looks…
Tara Kizer: I’ve done it.
Erik Darling: With SSIS, yeah, maybe. I haven’t done that with SSIS.
Brent Ozar: So the way that the table is sorted, even if you have an identity column, that doesn’t mean that table’s sorted in that order. Even if the clustered index is on it, the order that the rows, paired with the clustered index, can matter. So you want to have an ORDER BY basically on whatever you’re pulling out of the source file; you can sort the stuff in SSIS to determine the direction of what’s coming out. I just would never rely on it, because what happens, if you start loading duplicate rows, you’re going to over – if you tune the SSIS package, you’re going to update existing rows, so they won’t be in the same order in the table.
Tara Kizer: If I’m moving data via SSIS and I want to preserve the identity column value, which is a little bit different than what Ben’s asking, then I’m using the identity insert on option, so that I’m copying over exactly the value. That’s a sysadmin function though, so you have to make sure that, you know, the job, the process, has sysadmin. But I don’t want different values on two systems for the same row. So I’m preserving the identity value with that function.
Richie Rump: Okay, so why do we care about order with an identity column, right? So identity is a surrogate key; as a surrogate key, it’s meaningless. It should never have any sort of meaning. So, when we put some sort of order on it, now we’re inferring some sort of meaning onto that. Just dump it. Have a separate column and put an order there, if you really need it., but it shouldn’t be on the identity column, at all.
Brent Ozar: He adds, “there’s no identity in the source file, but the problem is that the order of the rows in the source table is critical, it’s just not specified in the source file.” Yeah, with like SSIS, you can add your own fields as part of the import, and that’s what you would add a row number, as part of that.
Richie Rump: Exactly.
Brent Ozar: Don’t rely on the database’s side, because you’re going to import the file over and over again, and you want that row number every time.
Tara Kizer: So the order of the data in the file is sorted, from what I’m gathering. So it’s in the correct order, and when you are inserting from a file to SQL Server with an identity column, it should preserve the order, because it’s going to be inserting row by row by row over.
Brent Ozar: Yeah, I just worry about somebody doing something like resetting an identity field, you reseed it and go in the negative direction, you know, anything like that. He says, “ah derived field, you rock”. Yeah, every now and then we get one right.
Erik Darling: Can that be parallelized? Because I wonder if that might screw up order as well.
Richie Rump: It will screw up order if it is parallelized. If you want to do a bulk upload on that, it will screw it up. So yes, you want to do that before you do all your, sort of, your imports.
What’s up with the PASS Summit this year?
Brent Ozar: Nice. Coleen says she “went to Kendra’s PASS 2016 session on deadlocking” and said, “it rocked.” Yeah, Kendra’s a great teacher, really fun to learn from.
Richie Rump: I was there and I was completely lost, but I’m not [crosstalk]…
Tara Kizer: Yeah, wasn’t that the session that we all showed up and she said you guys don’t belong here, this is for beginners.
Erik Darling: Yeah, that was the one.
Tara Kizer: I still learned some stuff.
Brent Ozar: I think that’s true with every session at Summit. I don’t think I’ve ever gone somewhere and not learned something, you know. There’s always some like tidbit where you’re like, whoa, I never thought of that. So speaking of which, Erik and I have pre-con this year. So Erik, what’s our pre-con about this year at PASS Summit?
Erik Darling: Perf [crosstalk] perf tuning, expert perf tuning. In the year 2017, so we’re not going to sit there and talk about profiler with you. We’re not going to…
Brent Ozar: Oh man, I’d written a session already.
Erik Darling: You’re fired. Fired from the pre-con.
Brent Ozar: Damn it.
Erik Darling: You can still get…
Brent Ozar: So yeah, it’s about 2016 and 2017, so what are you talking about during the pre-con?
Erik Darling: Well, I’m going to talk about that new stored procedure that’s up on the screen – oh, that was up on the screen. Now I look dumb, now I look quite foolish. So I wrote I stored procedure recently, another one. This one is called sp_BlitzQueryStore, and this one does for the query store what sp_BlitzCache does for your plan cache. It does have a little bit of a different method to it. It goes in and kind of looks at your worst periods of time for certain metrics and then collects anything that ran during those time periods. So it’s a little bit different, you’re not just giving it one sort order and saying give me the whole thing by this. But I’m going to be talking about how to use that to sort of delve into query store the way you delve into the plan cache with BlitzCache. So that will be fun.
Brent Ozar: Yeah, I’m going to start off with looking at wait types. I’m like, screw perfmon count, or screw this queue length, screw page life expectancy. All those things, they’re not really relevant anymore. What makes so much more sense is just asking SQL Server, hey, what’s your bottleneck? And then focusing on that one thing, because none of us can do a perfect job of systems administration. You’re going to have a slow tempdb, you’re not going to have enough RAM, you’re not going to have perfect indexes. Just focus on the one thing that the business users are going to notice as quickly as possible. So we’re going to talk about how to analyze wait stats with sp_BlitzFirst, how to look them at short periods of time or since the server startup, and then a quick decoder ring as to which wait types mean different things.
Are you coming to the mid-Atlantic?
Brent Ozar: Ben says, “when are any of you in the Mid Atlantic?” I don’t think ever. Mid Atlantic is like North Carolina, right? [crosstalk]
Erik Darling: I can’t row that far either.
Brent Ozar: Yeah, I don’t think we have anything planned for that anytime soon. I’m in Boston at the end of this month, but that’s as close as I get. Richie…
Erik Darling: I think south, you know, if I went any further south, I’d be out of Brooklyn, so I don’t want to do that.
Brent Ozar: And yeah, if Richie went any further north, he’d be out of Miami Dade, so yeah, neither of those work.
Richie Rump: I’d be out of Northern Cuba…
Erik Darling: There be snakes.
Brent Ozar: Coleen says, “one more and I’ll shut up. I went to your session too, Brent, and waited for a selfie, but the line was too long.”
Tara Kizer: That’s crazy.
Erik Darling: There was no line for me. Tara had a longer line than me.
Tara Kizer: I was surprised when people would come up to me while we were walking and Brent would be right there and they were like, hey Tara, I recognize you from [inaudible] Why are you recognizing me, here’s Brent.
Brent Ozar: Yes, it will be even funnier as more of those cartoons get out; it’s fun. Tara has a new, like, It Rocks cartoon, and it’s pretty cool. Alright, well thanks everybody for hanging out with us this week at Office Hours, and we will see you guys next week. Adios everybody.

























 Part of the magic in sp_BlitzBackups is being able to centralize backup information from multiple servers into a repository for analysis.
Part of the magic in sp_BlitzBackups is being able to centralize backup information from multiple servers into a repository for analysis.