The Surprising Behavior of Trailing Spaces
28 Comments
In every training class we do, I learn stuff from students. Here’s last week’s surprise.
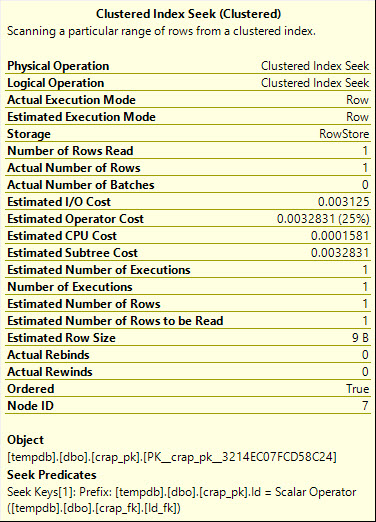
Create a temp table, and put in a value with trailing spaces. Then query for it using the = and <> operators, using different numbers of trailing spaces:
|
1 2 3 4 5 6 |
CREATE TABLE #Wines (Winery VARCHAR(50)); INSERT INTO #Wines VALUES ('Cliff Lede '); SELECT * FROM #Wines WHERE Winery = 'Cliff Lede'; SELECT * FROM #Wines WHERE Winery <> 'Cliff Lede'; SELECT * FROM #Wines WHERE Winery = 'Cliff Lede '; SELECT * FROM #Wines WHERE Winery <> 'Cliff Lede '; |
SQL Server simply ignores the trailing spaces:

The mind-blowing part to me is the <> operator – that seemed utterly crazy to me.
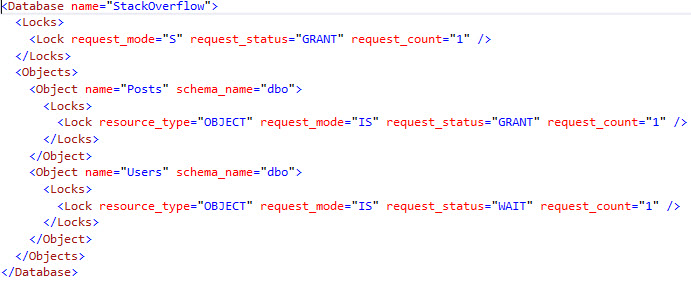
And if you add another table, and join to it, guess what happens:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE #PreferredDrinks (Drinker VARCHAR(50), FavoriteWine VARCHAR(50)); INSERT INTO #PreferredDrinks VALUES ('Brent Ozar', 'Cliff Lede'); INSERT INTO #PreferredDrinks VALUES ('Richie Rump', 'Cliff Lede '); /* Has 3 spaces */ INSERT INTO #PreferredDrinks VALUES ('Tara Kizer', 'Cliff Lede '); /* Has the exact number of spaces */ INSERT INTO #PreferredDrinks VALUES ('Erik Darling', 'Manischewitz'); SELECT * FROM #Wines w INNER JOIN #PreferredDrinks p ON w.Winery = p.FavoriteWine; |
All of the joins work regardless of the trailing space count:

This behavior is documented in KB 316626. Turns out the K in KB really does stand for knowledge.