Why Developers Should Consider Microsoft SQL Server
19 Comments
I know, I know, I’m biased because I’m a SQL Server guy. Hear me out, though, and I’ll give you both sides.
The Good
It’s stable and mature. SQL Server has been out for forever, so it’s easy to find blogs, videos, books, and people who can help.
Everything integrates with it. Visual Studio, reporting tools, everything is aware of SQL Server. Everything has drivers for SQL Server.
High availability is relatively easy to implement. SQL Server has a few features (failover clustering, log shipping, and database mirroring) that work pretty well out of the box with a minimum of expertise required. If you want to get fancy, you can scale out reads and do powerful stuff with Always On Availability Groups – although I’d be the first to tell you that feature isn’t nearly as easy.
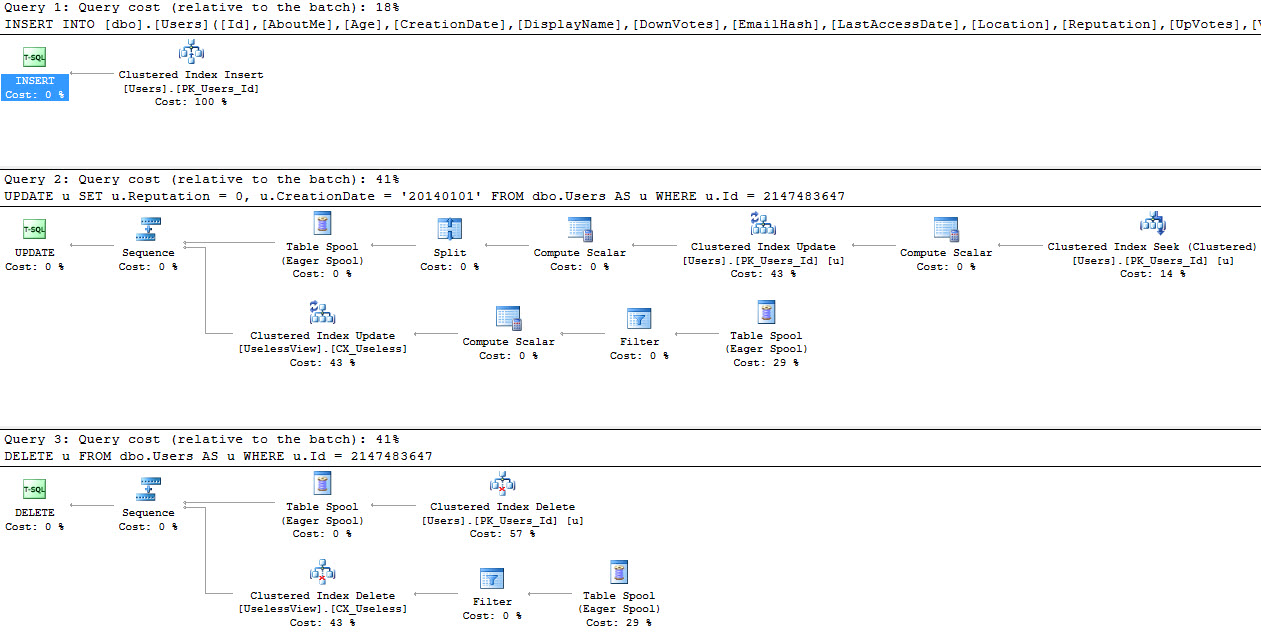
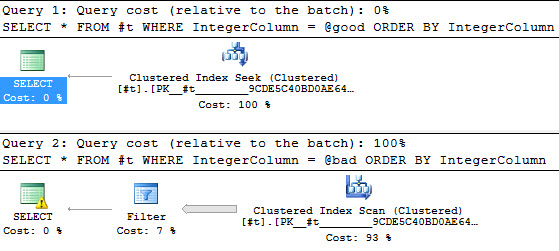
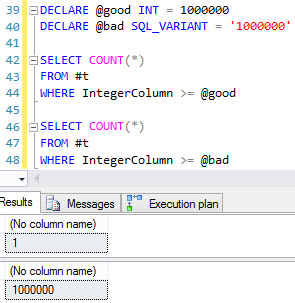
The query optimizer is really, really good. Even if you suck at writing queries, the optimizer does a pretty doggone good job of turning your typewriter-monkey act into a decent execution plan. With just a little bit of education about how it works, you can do a phenomenal job of scaling. Since SQL Server 2014 SP1, you can even watch query plans unfold live. Other databases post things like “we now have histogram-based stats” or “we have parallel scans” and I think, “woohoo, welcome to 2000!”
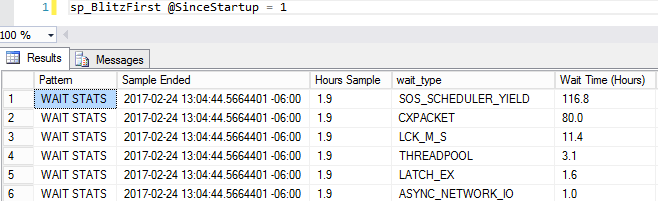
The built-in instrumentation is super-detailed and free. SQL Server exposes all kinds of internal data in a query-friendly format. Some platforms call these system tables – in SQL Server, we call them dynamic management views (DMVs), system functions, DMOs, etc, and there’s bajillions of them. There’s so many, and they’re so stable, that we’ve written tons of free scripts to make troubleshooting easier.
It checks a ton of enterprise boxes. When I look at feature guides at EnterpriseReady.io, I realize that I just kinda take a lot for granted in SQL Server. Sure, we have encryption, auditing, reporting, SLAs, Active Directory integration, yadda yadda yadda. If you’re building a new app today, you may not think you need that stuff – but the instant you try to sell into a big enterprise, you’ll hit walls without these features.
The community is great – not just for a closed-source product, but for any kind of product. #SQLhelp is active on Twitter, questions get answered fast on DBA.StackExchange.com,
There are a lot of storage features in the box. If you’re just getting started building something, you don’t want to hassle with half a dozen specialized persistence layers for relational data, key/value stores, spatial, XML, JSON, columnstore analytics, in-memory OLTP, full text search, R, etc. You can use one driver, dump your stuff in SQL Server, and call it a day.
The Bad
Few people use those storage features. Yeah, about columnstore, in-memory OLTP, JSON, XML, R, all that? Nobody uses those. If you run into performance problems, you’re gonna be out on your own.
It’s kinda expensive. Standard Edition (128GB max RAM) is about $2,000 USD per CPU core, which means a dual-socket, quad-core box is $16K of licensing. Enterprise Edition – and you may want to be sitting down for this – is $7K per core, which would be $56K for that same dual-socket, quad-core box. And then there’s the ongoing maintenance fees.
I try to keep the costs in perspective by saying SQL Server is one of my most valuable and reliable employees. It’s like a member of my development team. But yeah, it costs as much as a member of the team, especially when I start to scale. (But hey, it’s way cheaper than Oracle.)
The Ugly
It phones home. Starting with SQL Server 2016, it phones home by default, and in the free editions (Developer/Express/Evaluation), you can’t turn it off.
It’s closed source. I don’t have some kind of philosophical problem with closed source stuff, but you need to be aware that you’re not going to be able to examine the source code and suggest a fix for an issue that’s killing you. Your options are:
- Open a $500 support ticket – and if it’s a real bug, they’ll refund your money, and might even give you a hotfix.
- File a bug at Microsoft Connect – there’s no SLA here, and while sometimes they fix bugs in a matter of weeks or months, you still have to wait until the Cumulative Update is made public. The CU/build # isn’t posted in the Connect item, either, so you’re left reading knowledge base articles trying to figure out whether your fix is in yet.
- Cultivate relationships at Microsoft – I’ve had more than one Microsoft person tell me, “You could get what you want from us a lot faster if you would just network the idea with us politely.” Uh, okay, in the words of a timeless philosopher, ain’t nobody got time for that.
Disclaimer: I blatantly stole this idea from the excellent post, Why You Should Learn PostgreSQL.