Updating the Stack Overflow Demo Database
1 Comment
StackOverflow.com shares your questions, answers, comments, votes, users, badges, etc by doing a public data dump that you can download via BitTorrent.
I take that data, and I turn it into a SQL Server database that you can query. It’s so much better than the Microsoft sample databases because:
![]()
- It’s just a handful of easily-understood tables
- It has real-world data distribution
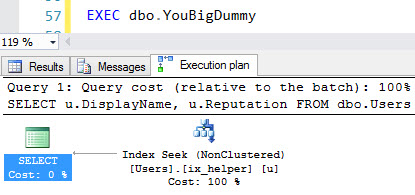
- Sample queries to tune are available at data.stackexchange.com
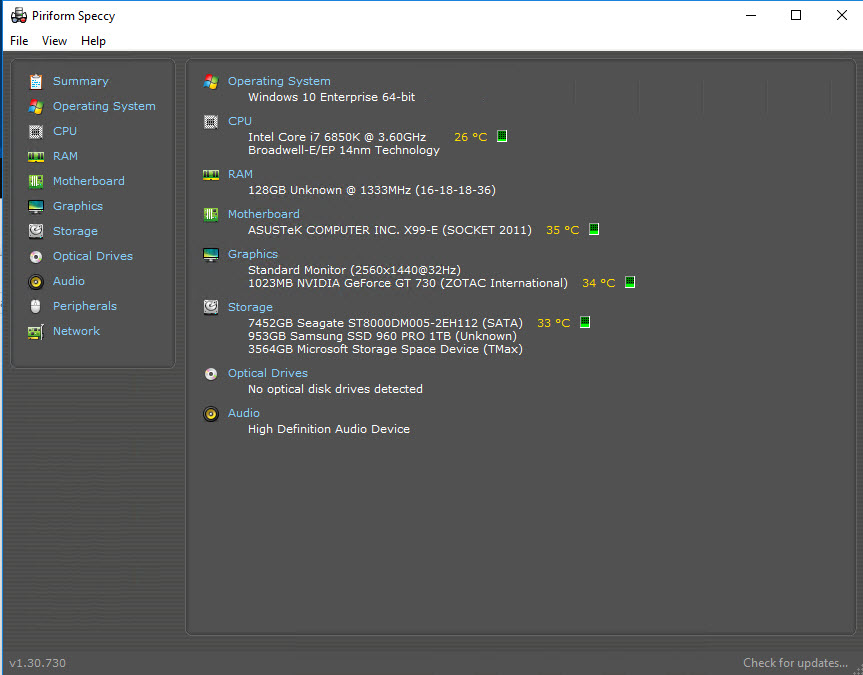
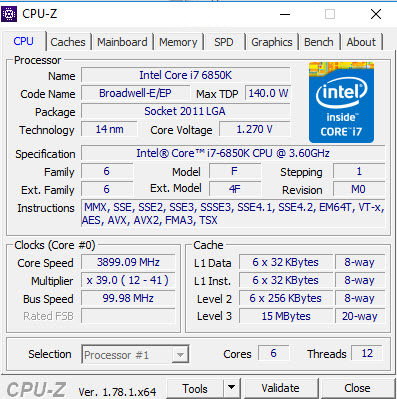
- It’s big enough to see real performance issues (the 2017-01 version is up to 110GB)
- It’s actually fun to read the data while you’re working with it
If you like playing around with this kind of thing, you can get the latest version now.