
In our Faux PaaS project, we need a backup plan – or rather, a restore plan.
On each SQL Server instance, clients can create as many databases as they want, anytime they want, with no human intervention. We need those databases covered by disaster recovery as quickly as practical.
SQL Server’s newer disaster recovery options – Always On Availability Groups and async database mirroring – have a few drawbacks. They require configuration for each new database, and they can hit worker thread exhaustion as you grow to hundreds or thousands of protected databases.
That’s where old-school log shipping comes in.
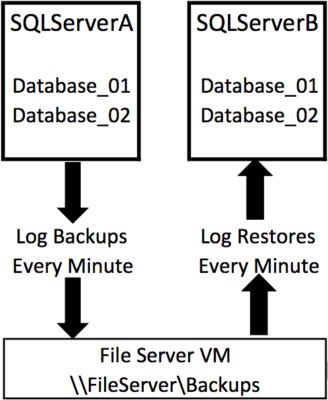
Log shipping (Books Online) isn’t just a built-in feature – it’s more of a technique that’s been around forever. In essence:
- The primary takes a log backup every X minutes
- The secondary watches that file share, and restores any new log backups that show up
SQL Server has their implementation of log shipping built right into the product, and it’s great – having stood the test of time for over a decade. (When’s the last time you saw a Cumulative Update that fixed a log shipping bug?) Normally, given the choice between reusing Microsoft’s code versus writing my own, I’ll take theirs every time.
Native log shipping isn’t perfect, though. We had a few ambitious requirements that SQL Server’s implementation didn’t quite meet:
- Zero setup for newly added databases
- Zero communication between the primary and secondary servers
- High throughput to keep up with hundreds or thousands of databases, but without hundreds or thousands of jobs running simultaneously
- Open source the whole thing so you can find our bugs
To make log shipping scale, we built sp_AllNightLog.
On the primary server, multiple Agent jobs take backups simultaneously across lots of databases using Ola Hallengren’s proven DatabaseBackup proc. You control the backup frequency and the number of Agent jobs to balance recoverability against performance overhead.
On the restoring server, same thing, but with sp_DatabaseRestore – multiple Agent jobs watch folders for incoming files, and restore ’em. Just like with regular log shipping, you can control the job schedules, so you can use the servers for read-only reporting workloads during the day, then catch ’em back up to current overnight.
You can install the restore side of it on multiple servers, in multiple locations, too. Here’s a sketch-out of a more advanced implementation similar to one we’re doing for the Faux PaaS project:

To learn more:
- Read the sp_AllNightLog documentation
- Download the free First Responder Kit (and check out Tara’s white paper in there about disaster recovery in Google Cloud)
- For interactive help, visit the #FirstResponderKit channel in the SQL Server community Slack (just be patient, community members aren’t always around in the Slack room)
- To file a bug, hit the Github Issues
I do expect to see lots of bugs in here for now – this hasn’t gone into production anywhere yet, only into our testing labs, so I’m sure we’re going to discover neat stuff over the next few weeks. If you choose to put it in production, I’d highly recommend watching the Github repo (click the Watch icon at the top right when you’re logged in) to get emails as people find bugs.

We’d like to thank kCura for making this open source project possible, and thank Google Compute Engine for helping us lay the foundation with sp_DatabaseRestore. I’m a huge believer in partnering with clients to not just make their own projects happen, but help you, dear reader, by contributing this work back into the open source community.
Wanna work with us on fun projects like this? kCura is hiring a Senior DBA, and it’s a heck of a fun place to work.

9 Comments. Leave new
Congrats on the awesome release!
I’ll just leave this here:
http://i.imgur.com/Uy8c8uC.jpg
WHAT IS THIS SORCERY?!
Seriously though, I may need this. Yesterday.
should this read: On the primary server, multiple Agent jobs take backups simultaneously across lots of databases using “sp_DatabaseBackup”
Ah, sort of! Good catch. sp_DatabaseRestore doesn’t actually take backups, huh? 🙂
Oooh shiny
Wish I had watched your github repo, I built something similar, a month ago to solve the same problem for the same product.
I’ll sort through you code over the next week or so and fork it.
Took a while to figure out how to deal with the edge cases like multiple backupsets of different types in the same backup files.
as well as deciding what to do when the chain breaks.
Charles – thanks!
About different types in the same backup files – I never, ever, ever use multiple backups in the same file. If you run into a backup file corruption problem, insert sad trombone here.
About broken chains – check the current open issues list. There’s a field I just added recently to restore_worker that lets you promote restores to either full or diff. Right now it’s a manual troubleshooting step.
hi can i use sp_AllNightLog for express edition ?
there is any documentation for that ?
Radityo – we haven’t tried, no.