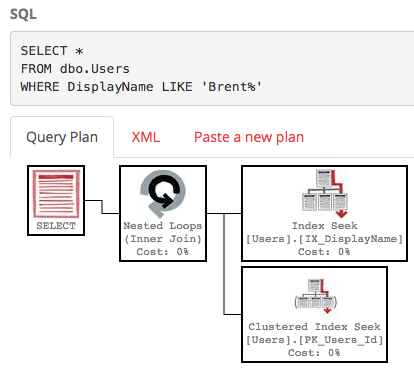
Should I Install Multiple Instances of SQL Server?
46 Comments

Instance stacking is the technique of installing multiple instances of SQL Server on the same Windows instance. For example, you might have a VM or server named SQLPROD1, and have:
- SQLPROD1 – default instance of SQL Server, say SQL 2016
- SQLPROD1\SQL2014 – for our older apps
- SQLPROD1\SharePoint – because it’s supposed to be on its own instance
- SQLPROD1\development – for our QA & testing
The Benefits of Instance Stacking
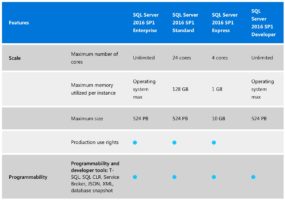
Lower SQL licensing costs – you only have to pay for one license, and then even Standard Edition lets you install dozens of instances on the same Windows base.
Lower Windows licensing costs – you only have to pay for one Windows.
Easier Windows patching – since you only have to patch one OS install.
The Drawbacks of Instance Stacking
Much harder performance tuning – all of the instances share the same CPU, memory, network pipe, and storage pipe. While SQL Server does offer tricks like affinity masking and memory settings to alleviate the first two, it’s got no answers for the second two. A backup on one instance will knock out performance on the other instances regardless of how much tuning work you put in. If none of the instances are performance-sensitive, this doesn’t matter – but how often does that happen? And how do you figure out what the “right” memory or CPU settings are? It takes so much human work and experimentation that it really only makes sense when you have plenty of free time per DBA per server.
Much harder reboot planning – you have to get all of the customers on all of the instances to agree on a time to patch Windows.
Security challenges – sometimes, we get those awful folks who insist on being able to RDP into the Windows instance that hosts their databases. If they insist on being sysadmin on the box altogether, then they can make changes that wreak havoc on the other running instances.
The Alternative: Virtualization
Whenever you think about carving up a single server into smaller pieces, think virtualization instead. It’s a great default place for new SQL Servers.
Every SQL Server deserves its own Windows instance. Yes, this does mean higher licensing costs – you’ll need to license SQL Server Enterprise Edition at the hardware host level, and then you can pack in as many VMs as possible into the host.
Then, each VM gets their own performance management, patch schedules, and security. Plus, surprise bonus: every VM, even the tiniest ones, get all of the features of Enterprise Edition.