
ColumnStore Indexes And Recursive CTEs
Alone Together
When I think about SQL Server features, I often picture a high school cafeteria.
AGs are making fun of Mirroring, index rebuilds are walking around taking everyone’s lunch, dta is making a glue sandwich, and no one knows who Service Broker is even though they’ve been going to school together since Kindergarten.
At the artsy table are two oft-misunderstood and unpopular features: ColumnStore indexes and Recursive CTEs. The oldest person on Stack Overflow, Joe Obbish, recently blogged about a deficiency in ColumnStore indexes when it came to doing string aggregation. When someone says “X is bad at Y”, my first reaction is generally to try to find other things X is bad at, and kicking X while it’s down.
Lace Up Your Boots
I know what you’re thinking: WHY WOULD YOU EVER DO THIS?
Well, ladies and gentlemen, that’s what consultants specialize in.
Stuff no one else would ever do.
There’s a really interesting relationship in the Stack Overflow database both within the Posts table, and connecting the User and Comment tables. You can build up pretty interesting hierarchies with them.
The Posts table has both questions and answers in it. You can tell them apart using the PostTypeId column, and you can also look at the ParentId column. If a post is an answer to a question, it’ll have the Id of the question populated.
Likewise, the Comments table connects comments to posts and answers, and both tables track the Ids of users. This comes in Handy for grabbing DisplayName from the Users table.
Having spent an amount of time only a consultant can looking at stuff in the database, I know that post 184618 currently (2016-03 data dump) has the most answers in the Posts table, at 518. So that’ll be our performance bar.
Gangland
Let’s start by indexing and querying rowstore tables.
Here are our awesome nonclustered indexes.
|
1 2 3 4 5 |
CREATE UNIQUE NONCLUSTERED INDEX ix_HierarychyHelper ON dbo.Posts (ParentId, Id, OwnerUserId); CREATE UNIQUE NONCLUSTERED INDEX ix_HierarychyHelper ON dbo.Comments (PostId, UserId, Id); CREATE UNIQUE NONCLUSTERED INDEX ix_HierarychyHelper ON dbo.Users (Id) INCLUDE (DisplayName); |
And here’s our extra fun recursive query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
WITH postparent AS ( SELECT p.Id, p.ParentId, p.OwnerUserId , hierarchyid::GetRoot() AS PostPath FROM dbo.Posts AS p WHERE p.Id = 184618 UNION ALL SELECT p2.Id, p2.ParentId, p2.OwnerUserId, TRY_CONVERT(HIERARCHYID, pp.PostPath.ToString() + CONVERT(VARCHAR(11), p2.Id) + '/') FROM postparent pp JOIN dbo.Posts AS p2 ON pp.Id = p2.ParentId UNION ALL SELECT c.Id, c.PostId, c.UserId , TRY_CONVERT(HIERARCHYID, pp.PostPath.ToString() + CONVERT(VARCHAR(11), c.Id) + '/') FROM postparent pp JOIN dbo.Comments AS c ON pp.Id = c.PostId AND pp.OwnerUserId = c.UserId ) SELECT pp.Id, pp.ParentId, pp.OwnerUserId, u.DisplayName, pp.PostPath, pp.PostPath.GetAncestor(1) AS PostPathAncestor, pp.PostPath.GetLevel() AS PostPathLevel FROM postparent pp JOIN dbo.Users AS u ON u.Id = pp.OwnerUserId ORDER BY PostPathLevel OPTION (MAXRECURSION 0); |
With my indexes in place, here are my stats Time and IO results. I’ve lopped off all the zero-read operations. for readability.
|
1 2 3 4 5 6 7 |
Table 'Worktable'. Scan count 2, logical reads 3194 Table 'Users'. Scan count 0, logical reads 1926 Table 'Comments'. Scan count 642, logical reads 1930 Table 'Posts'. Scan count 642, logical reads 1933 SQL Server Execution Times: CPU time = 0 ms, elapsed time = 24 ms. |
I even have what most would consider a reasonable execution plan for such a query.
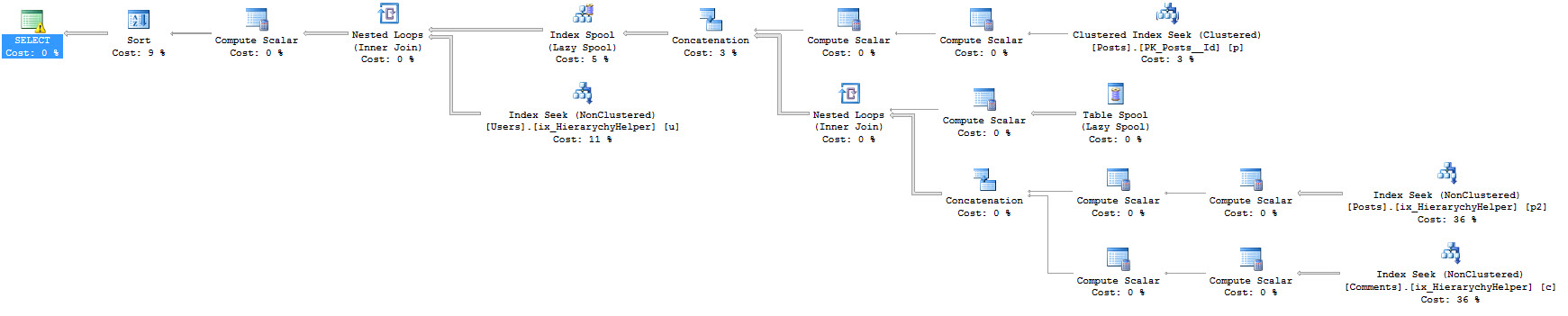
Inflection Point
With that in mind, let’s hop on over to my ColumnStore version of the Stack Overflow data dump. All of the tables here either have a clustered ColumnStore index on them, or a nonclustered one if they have columns with datatypes that make that impossible (Users and Posts both have columns that are MAX types, which makes CS puke).
Running the same query, here are the results of stats Time and IO. What you’re looking at are the results of the second run with a warm cache. The first run took about 4 minutes and did a bunch of physical reads, and that didn’t seem fair.
|
1 2 3 4 5 6 7 8 9 |
Table 'Worktable'. Scan count 1286, logical reads 283557113 Table 'Users'. Scan count 0, logical reads 1975 Table 'Comments'. Scan count 1, lob read-ahead reads 105411. Table 'Comments'. Segment reads 377, segment skipped 0. Table 'Posts'. Scan count 2, logical reads 4, lob logical reads 77526, lob physical reads 2, lob read-ahead reads 118902. Table 'Posts'. Segment reads 48, segment skipped 0. SQL Server Execution Times: CPU time = 197515 ms, elapsed time = 197675 ms. |
If you’re wondering what those milliseconds are in minutes, it’s 3:17. So uh, there’s our first problem.
And here’s the query plan, which bears some interpretive dance. It looks a whole heck of a lot like the previous plan. Prior plan? One of those. Except two index spools are introduced.

Funny things you should know about Index Spools: They’re single threaded, and I’m going to go out on a limb and say SQL doesn’t build ColumnStore Index Spools. They cache data in tempdb. When they’re Eager, they cache all the rows coming to them, and when they’re Lazy they only cache rows as required. This makes Lazy Spools much more benign than Eager Spools (there’s a Lazy Spool in both of the query plans).
They also make up the majority of the work our query is doing here in ColumnStore land. There are other obvious problems with it, like it running in Row mode rather than Batch mode. I stuck the query plan in Paste The Plan for anyone interested in poking around more.
I’m not getting any prettier, here
Stuff like this is part of the reason why we’ve started warning about Index Spools in sp_BlitzCache and sp_BlitzQueryStore. We started warning about ColumnStore indexes operating in Row Mode a while back because it’s basically a death knell for performance.
This post should have a point, right? ColumnStore! Not good at everything. Pretty spiffy for aggregations, but there are plenty of times when traditional row store indexes will out-perform them.
For more information about Spools, check out these links:
Fabiano Amorim: Part 1 and Part 2
Paul White: Part 1, Part 2, Part 3
Rob Farley: Part 1
A most excellent dba.stackexchange.com question, in which Joe Obbish gets prescribed some Spool Softener
Thanks for reading!

7 Comments. Leave new
Adding OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) is useful when you want to compare performance of your queries on a table with a NC columnstore index.
Yeah, unfortunately there’s not a similar hint for clustered ColumnStore indexes.
“AGs are making fun of Mirroring, index rebuilds are walking around taking everyone’s lunch, dta is making a glue sandwich, and no one knows who Service Broker is even though they’ve been going to school together since Kindergarten.”
this is quite possibly the best sentence ever to appear on this blog. tears of joy, sir. tears of joy.
plus, i now have a solution to a problem which plagues me on a near-daily basis: next time i can’t put a name to a face it’s: “Hey hey, Service Broker! Long time no see!”
? I feel glad when you’re glad ??
Those musical notes really didn’t pan out here.
I was just working on this very issue this week. It helped me identify what was going on with a recursive CTE that was utterly failing for me. Thanks Erik. The timing was perfect.
Woohoo! Glad to hear it! I knew of these would finally pay off.