PasteThePlan.com Winners and Sample Plans
3 Comments
When we announced PasteThePlan last week, we wondered what kinds of plans you folks would paste in. Six of you won free Everything Bundles:
- Ajay Dwivedi
- Samuel Jones
- Stefan Gabriel
- Stephan Schon
- Steve Armistead
- Vesa Juvonen
But rather than stepping through their plans (which are awesome too), I’m going to show a few bits and pieces from the hundreds of plans you all pasted in during the first week.
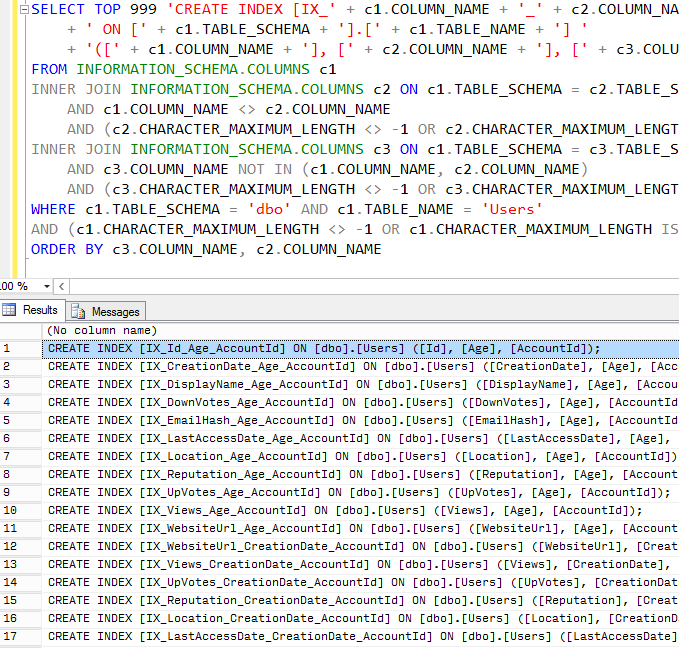
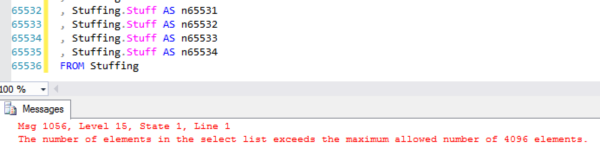
Long batch – this one’s got tons of issues, but even just the first statement has one of my favorites: parsing a string in order to build a subquery, and then checking to see if elements of that string are numeric. Cardinality estimation hell.
Helpful comment block – hey, whenever you have to read long queries in foreign languages, it’s always good to start with a useful comment block. At least SET NOCOUNT ON is documented.

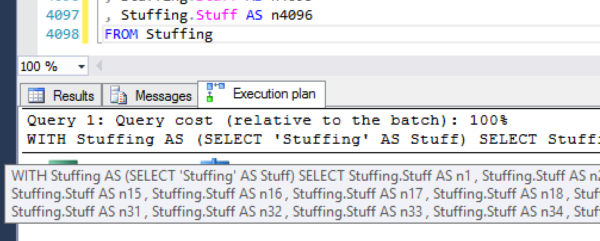
Deadlock checking – first thought: ooo, wow, someone’s checking for deadlocks. Second thought: OH GOD, THAT PLAN. (Pictured at right.)
Seemingly simple select – it’s just a one-line select * from a view – how bad can it be? Holy cow, how many tables are in this view?!?
Shredding URL strings in the WHERE clause – not to mention trimming phone numbers. Hoowee.
Dirty reads and table variables – actually, Dirty Reed and the Table Variables sounds like a great name for a band.
Nested selects causing table scans – when people tell me Entity Framework writes bad code, I’m going to point them to this query and say no, YOU write bad code.
It’s been so much fun watching folks paste plans in and get help on StackExchange. We’re already coming up with lots of ideas on how to help make this process easier for you and get you tuning advice faster. Stay tuned!
(Get it, tuned? Tune? Oh, fine, I’ll go back to T-SQL.)
 Since the dawn of man, people have struggled with sharing execution plans with each other for performance tuning. Now, it’s easy.
Since the dawn of man, people have struggled with sharing execution plans with each other for performance tuning. Now, it’s easy.