Updated First Responder Kit: sp_Blitz markdown output, sp_BlitzIndex statistics checks
4 Comments
In addition to lots of bug fixes and tweaks, my favorite option is:

sp_Blitz @OutputType = ‘markdown’, @CheckServerInfo = 1, @CheckUserDatabaseObjects = 1
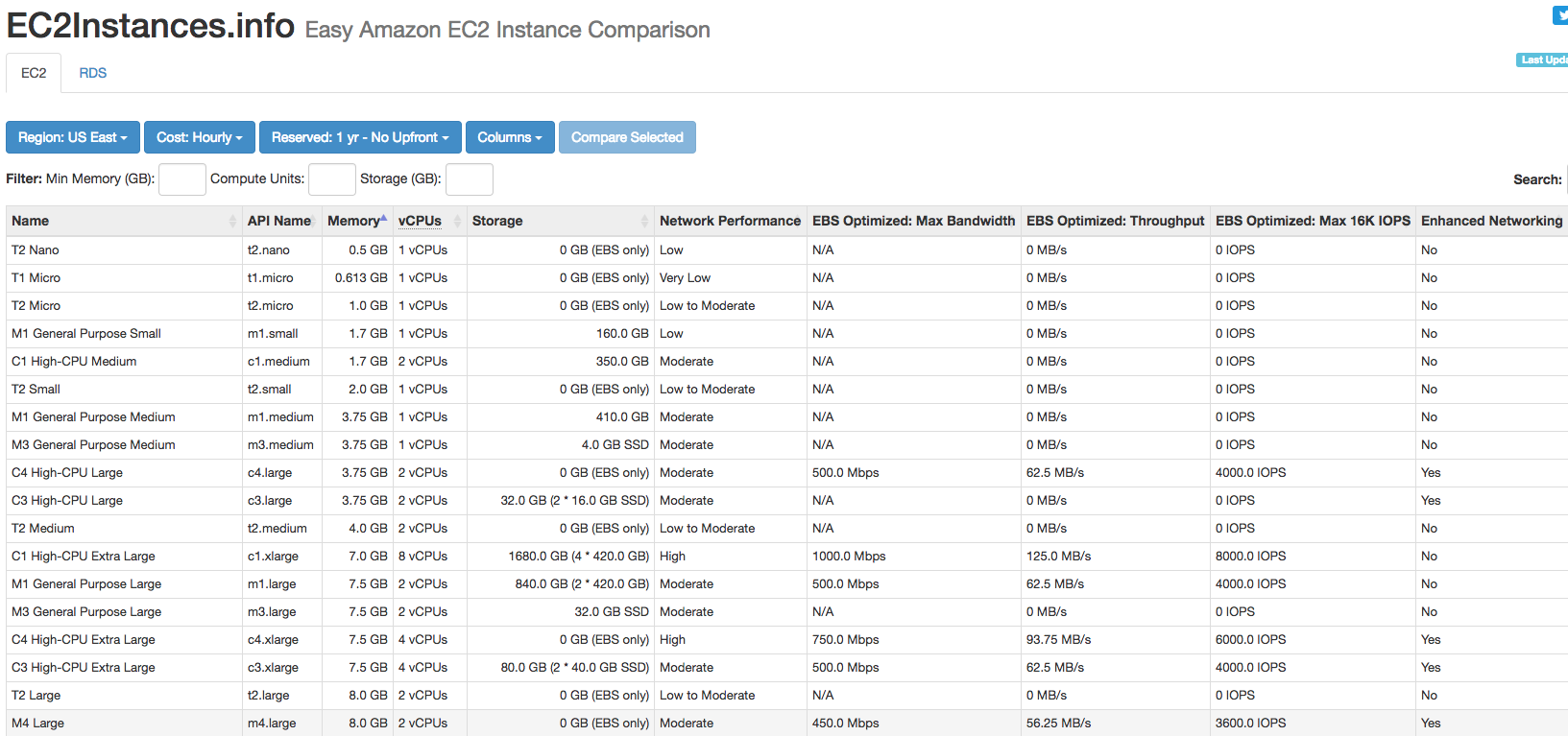
See, recently I’ve spent a lot of time looking at Stack questions going, “Man, if I just had the output of sp_Blitz, I bet I could answer that question in five minutes.” But sp_Blitz’s output doesn’t lend itself well to copy/pasting.
StackOverflow lets you format your questions and answers with a flavor of Markdown, a cool way of editing text files. So I added @OutputType = ‘markdown’ with a bullet-list-tastic format. (Sadly, Stack’s flavor of Markdown doesn’t support tables, which would have made things easier.)
I don’t include all of the fields from sp_Blitz’s results – for example, there’s no URLs or query plans, because those things don’t make as much sense here.
In other news:
sp_Blitz v53.3:
- New check for failover cluster health (Matt Tucker) – warning if you don’t have failover cluster nodes available in sys.dm_os_cluster_nodes.
- New check for endpoints owned by user accounts (HBollah)
- New check for wait stats cleared since startup (Brent Ozar) – useful in combination with @CheckServerInfo = 1, which includes any wait stats that are bottlenecks.
- Improved Amazon RDS and SQL Server 2005 compatibility (Brent Ozar)
sp_BlitzFirst v25.2:
- Split what’s running now code into new sp_BlitzWho (Ryan Howard) – several folks said they found this section useful on its own. We’ll add more into sp_BlitzWho down the road.
sp_BlitzIndex v4.2:
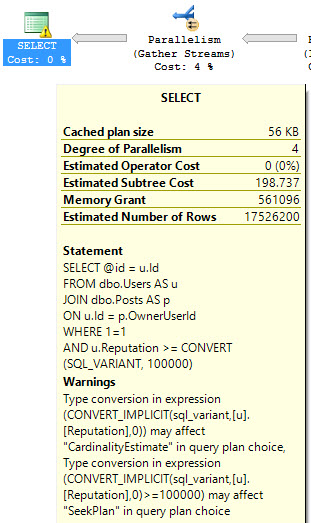
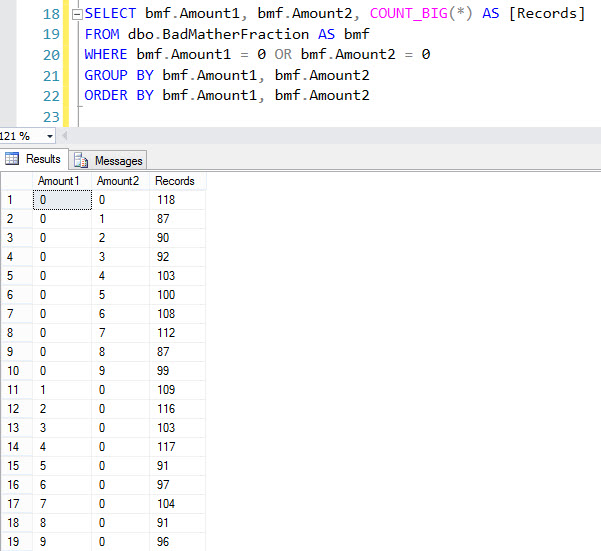
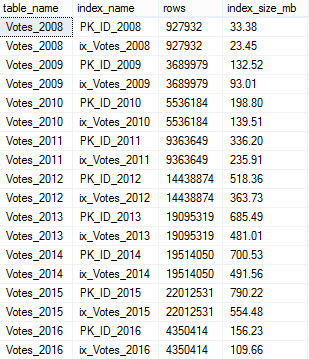
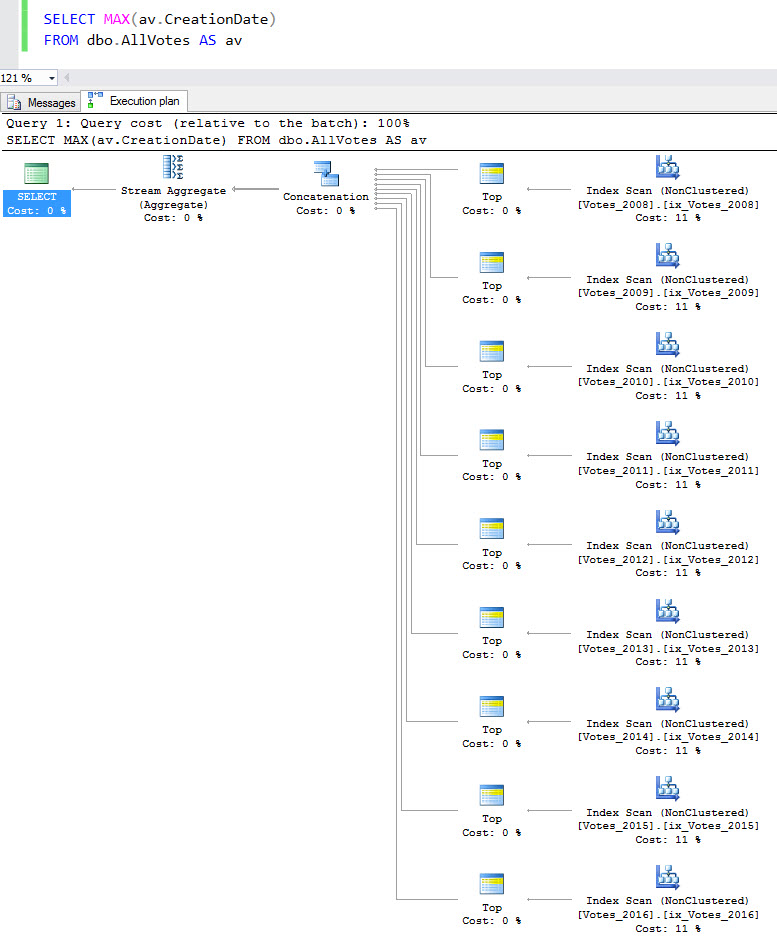
- Added statistics checks (Erik Darling) – warning about outdated stats and stats with low sample rates.
- Added database name to multi-db result sets (Brent Ozar) – notable because it’s a breaking change if you’d built anything on top of @GetAllDatabases = 1.
Go get the goods now, and if you’d like to contribute code or file issues, head over to the Github repo.