
Why Columnstore Indexes May Still Do Key Lookups
I was a bit surprised that key lookups were a possibility with ColumnStore indexes, since “keys” aren’t really their strong point, but since we’re now able to have both clustered ColumnStore indexes alongside row store nonclustered indexes AND nonclustered ColumnStore indexes on tables with row store clustered indexes, this kind of stuff should get a closer look.
Of course, the effects of the sometimes-maligned Key Lookup are sometimes pretty lousy.
When datatypes aren’t supported by columnstore
You may need to mix indexes in cases where you have columns with unsupported datatypes, like MAX, or perhaps just datatypes that don’t have aggregate pushdown support in ColumnStore yet. I hesitate to make a list here, since it could change in a CU, but here’s what the MS doc currently says about it:
The input and output datatype must be one of the following and must fit within 64 bits.
Tiny int, int, big int, small int, bit
Small money, money, decimal and numeric which has precision <= 18
Small date, date, datetime, datetime2, time
Got it? Also!
The aggregates are MIN, MAX, SUM, COUNT and COUNT(*).
Aggregate operator must be on top of SCAN node or SCAN node with group by.
This aggregate is not a distinct aggregate.
The aggregate column is not a string column.
The aggregate column is not a virtual column.
So uh, anything outside of those datatypes and aggregates can potentially inhibit optimal performance (in case you’re wondering, this sentence wasn’t written by a lawyer).
Demoing it with a clustered columnstore index
Here’s how I set the tables up, finally. Remember kids: loading large volumes of data into tables with nonclustered indexes is dumb.
Don’t do it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
USE tempdb GO CREATE TABLE dbo.cci ( Id BIGINT IDENTITY(1, 1), Beavis DATE, Butthead DATE, INDEX cx_whatever CLUSTERED COLUMNSTORE ); CREATE TABLE dbo.crsi ( Id BIGINT IDENTITY(1, 1), Beavis DATE, Butthead DATE, INDEX cx_whatever CLUSTERED (Id) ); INSERT dbo.cci WITH ( TABLOCK ) (Beavis, Butthead) SELECT TOP 10485760 DATEADD(DAY, (x.r % 365), CONVERT(DATE, GETDATE())), DATEADD(DAY, (( x.r * -1 ) % 365), CONVERT(DATE, GETDATE())) FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY @@ROWCOUNT ) AS r FROM sys.messages AS m CROSS JOIN sys.messages AS m2 ) AS x; INSERT dbo.crsi WITH (TABLOCK)(Beavis, Butthead ) SELECT c.Beavis, c.Butthead FROM dbo.cci AS c CREATE NONCLUSTERED INDEX ix_whatever ON dbo.cci ( Beavis ) CREATE NONCLUSTERED COLUMNSTORE INDEX ix_whatever ON dbo.crsi ( Beavis ) |
We now have the most optimal setup to get a Key Lookup plan: tables with clustered indexes and God-awful single column nonclustered indexes (okay, so there are exceptions here, but for the most part…).
Come and take it
First up, we need a date to work with. I know most of you can sympathize with that problem.
Q: which function do DBAs have the biggest problem with in real life?
A: GETDATE()
Actually, I’m told DBAs make great spouses, because you barely have to see them.
What was I saying? Date? DATE!
Date.
|
1 2 3 |
SELECT MAX(c.Beavis) AS [Cornholio] FROM dbo.cci AS c WHERE 1 = (SELECT 1); |
If you want an explanation for the 1 = (SELECT 1), head over here. Otherwise, let’s write some queries.
For me, that query returns a value of 2018-08-23. The first thing I discovered is that you really have to jump through hoops to get the Key Lookup to happen. The optimizer’s adversity to choosing Key Lookup plans with ColumnStore indexes is well-meaning.
With regular row store indexes, returning 28k rows out of 10,485,760 with a Key Lookup plan would be a no-brainer for the optimizer.
Hooray for index hints.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT * FROM dbo.cci AS c WITH (INDEX = ix_whatever) --Clustered ColumnStore, nonclustered row store index on Beavis WHERE c.Beavis >= '2018-08-23' AND 1 = (SELECT 1); GO SELECT * FROM dbo.crsi AS c WITH (INDEX = ix_whatever) --Clustered Row Store on ID, nonclustered ColumnStore on Beavis WHERE c.Beavis >= '2018-08-23' AND 1 = (SELECT 1); GO |
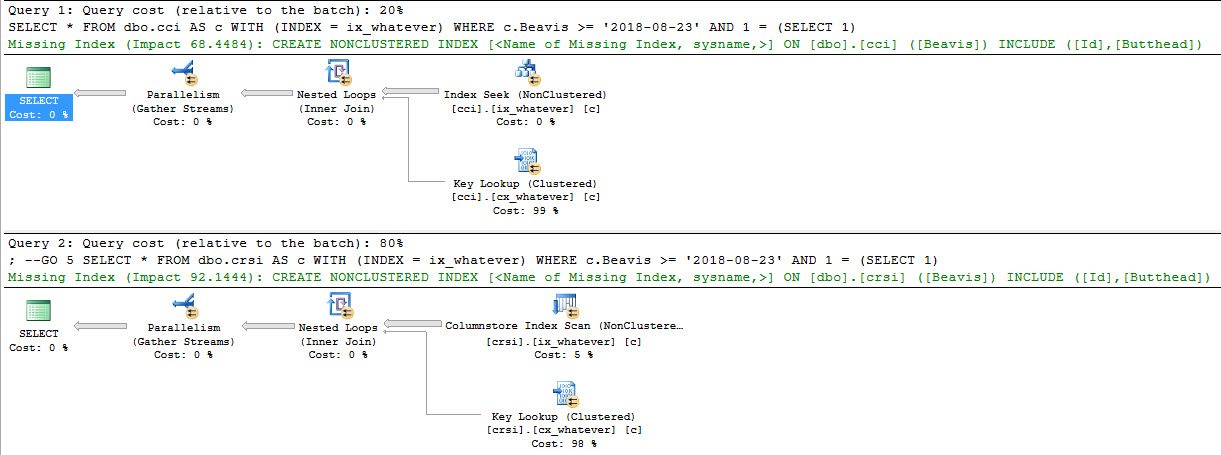
Looking at screencaps of query plans isn’t too fun, is it? I stuck them on PTP for anyone interested.
And for extra credit, let’s see what sp_BlitzCache says about our queries.
|
1 |
EXEC master.dbo.sp_BlitzCache @IgnoreSystemDBs = 0, @DatabaseName = 'tempdb' |

The warnings shown by sp_BlitzCache
It’s nice when you don’t have to do any work to find problems. That’s why I do all the work I do on sp_BlitzCache and sp_BlitzQueryStore. I want to make your life better and easier. Let’s look at some of the warnings we have for each query:
- Clustered ColumnStore: Missing Indexes (1), Parallel, Expensive Key Lookup, Plan created last 4hrs, Forced Indexes, ColumnStore Row Mode
- Clustered Row Store: Missing Indexes (1), Parallel, Expensive Key Lookup, Unused Memory Grant, Plan created last 4hrs, Forced Indexes
Without opening a plan or looking at a single tool tip or hitting f4, we know some things:
- SQL is angry about missing indexes
- We have expensive key lookups
- We’re forcing indexes
- We have a ColumnStore query operating in row mode instead of Batch mode
- We have an unused memory grant
- Both plans are relatively new in the cache (duh)
But focusing on the point of the post, which we should probably do, something kind of obvious happens.
The query that uses the nonclustered ColumnStore index does a typical Key Lookup. It’s able to (1) scan the ColumnStore index in Batch mode, (2) pass those rows to a Nested Loops join, and then (3) ‘join’ the nonclustered index to the clustered index on the clustered index key column.
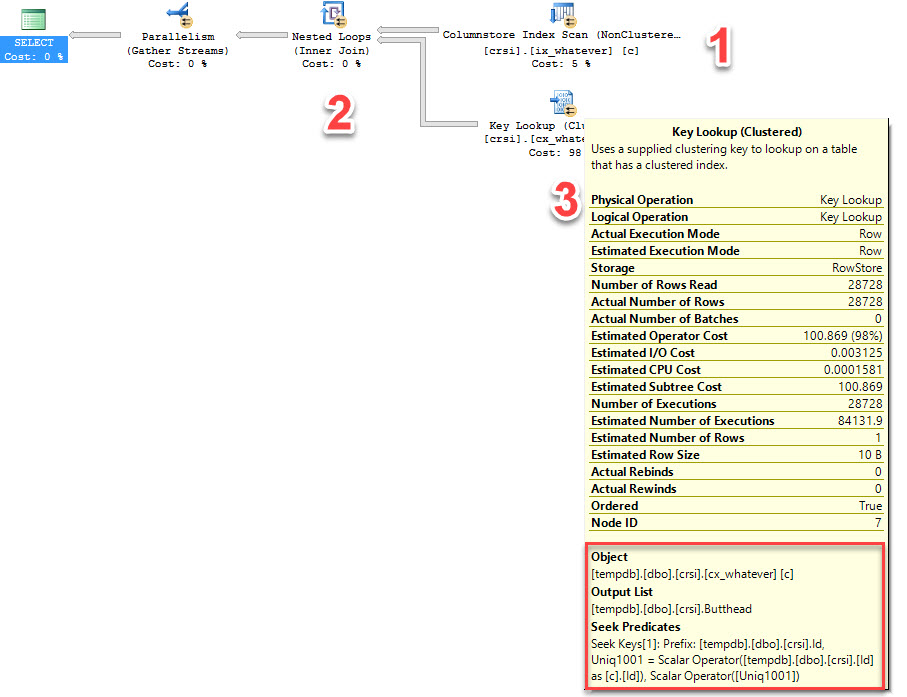
But clustered ColumnStore indexes don’t have key columns.
Let’s look at what happens there!

I’m going to assume that this is a bit like a RID Lookup in a plan using HEAPs. Without a clustered index key column, we need to rely on internal metadata to locate rows. That’s what the Seek Keys[1]: Prefix: ColStoreLoc1000 = Scalar Operator([ColStoreLoc1000]) part of the Key Lookup is doing. Interesting!
Fun yet?
This isn’t a knock against clustered ColumnStore indexes. The team behind them has done awesome work to make them more usable and less painful (remember back when they didn’t work with Availability Group secondaries? Of course you don’t!). I wrote this because I’ve gotten increasingly interested in ColumnStore as it becomes more powerful, and as more people start hopping on newer versions of SQL Server where they’re a viable path to fixing real problems.
Thanks for reading!

10 Comments. Leave new
Great write up. Still on SQL2014 pain.
Ah, 2014. The sister you didn’t know was ugly for two years.
Throwing an error:
USE tempdb
GO
CREATE TABLE dbo.cci
(
Id BIGINT IDENTITY(1, 1),
Beavis DATE,
Butthead DATE,
INDEX cx_whatever CLUSTERED COLUMNSTORE
);
Whatever you do, don’t tell us what the error message is. That might help us figure out the problem.
Sorry, I thought you ran the query i provided. Any way the error I am getting:
Msg 102, Level 15, State 1, Line 10
Incorrect syntax near ‘)’.
the red mark at after the below end of the parenthesis.
” INDEX cx_whatever CLUSTERED COLUMNSTORE
); “
Sounds like you’re not on a version/edition of SQL Server that supports clustered columnstore indexes. The query worked fine here.
It sounds like you’re on 2014 or below, or your database is in an earlier compatibility mode.
Using dbfiddle, this fails on 2014 and succeeds on 2016+.
Next time, please do some basic troubleshooting.
Thanks!
Here’s a fun one: we’ve been using the CCS for a year and a half and love it – daily data feeds were fast, even with a bunch of separate WHERE criteria (on multiple fields, plus it’s all partitioned on date-received). However, we recently had performance on a different type of query go from .1 second to 10 minutes per row, and we didn’t see anything obvious. So in lieu of deep-diving the problem, we decided to add a non-clustered index on one field (a bigint ID field in the table; we created it and made sure to include partitioning).
That query went back to being performant – but many other queries started sucking wind. We check out the plan, and they’re doing index scans on that new index, then using the CCS as a key lookup (as opposed to just using the CCS). Try RECOMPILE, still slow. Try 9481, still slow. We wind up forcing the CCS via an index hint, and back to fast.
Now, this is all on 2016 SP1 CU1, so hopefully once we get them to patch it’ll fix this issue, but IMHO it bears mentioning.
I wonder if you could have gotten the same outcome from adding a stats object with full scan on the column. Often adding an index like that has the effect of giving the optimizer a better histogram to look at.
[…] https://www.brentozar.com/archive/2017/09/key-lookups-columnstore-indexes/ […]