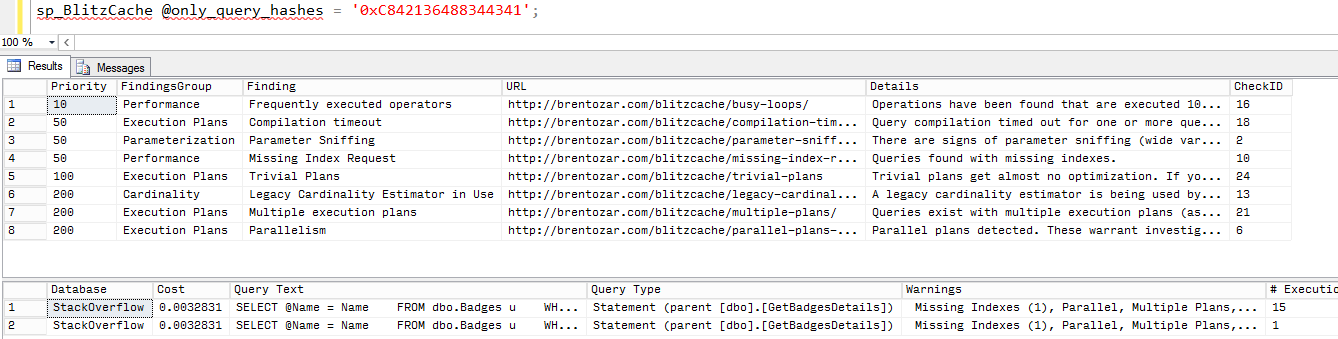
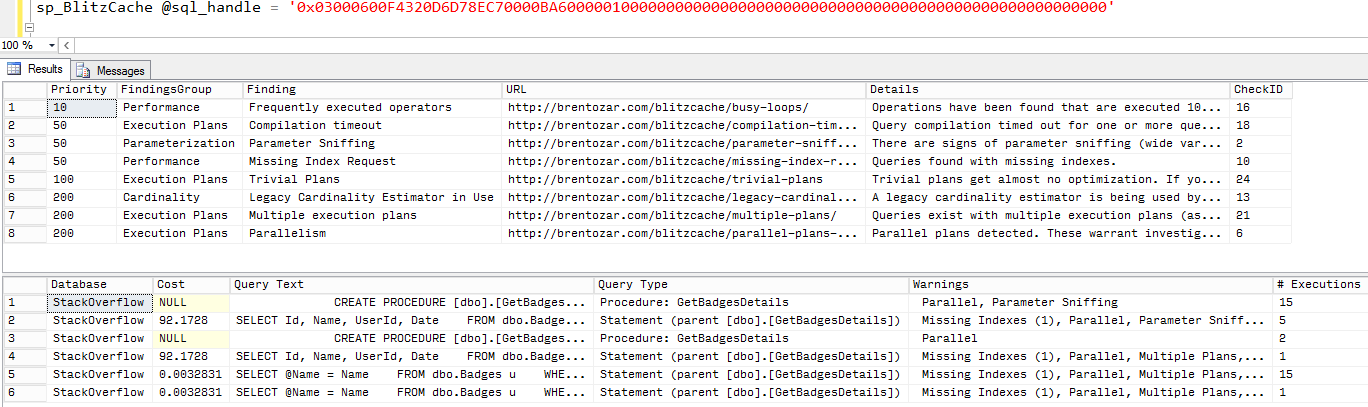
Bad Idea Jeans Week: Prevent the Use of the Database Engine Tuning Advisor
12 Comments
Every now and then, we put on our bad idea jeans in the company chat room and come up with something really ill-advised. We should probably bury these in the back yard, but…what fun would that be? Bad ideas are the most fun when they’re shared.
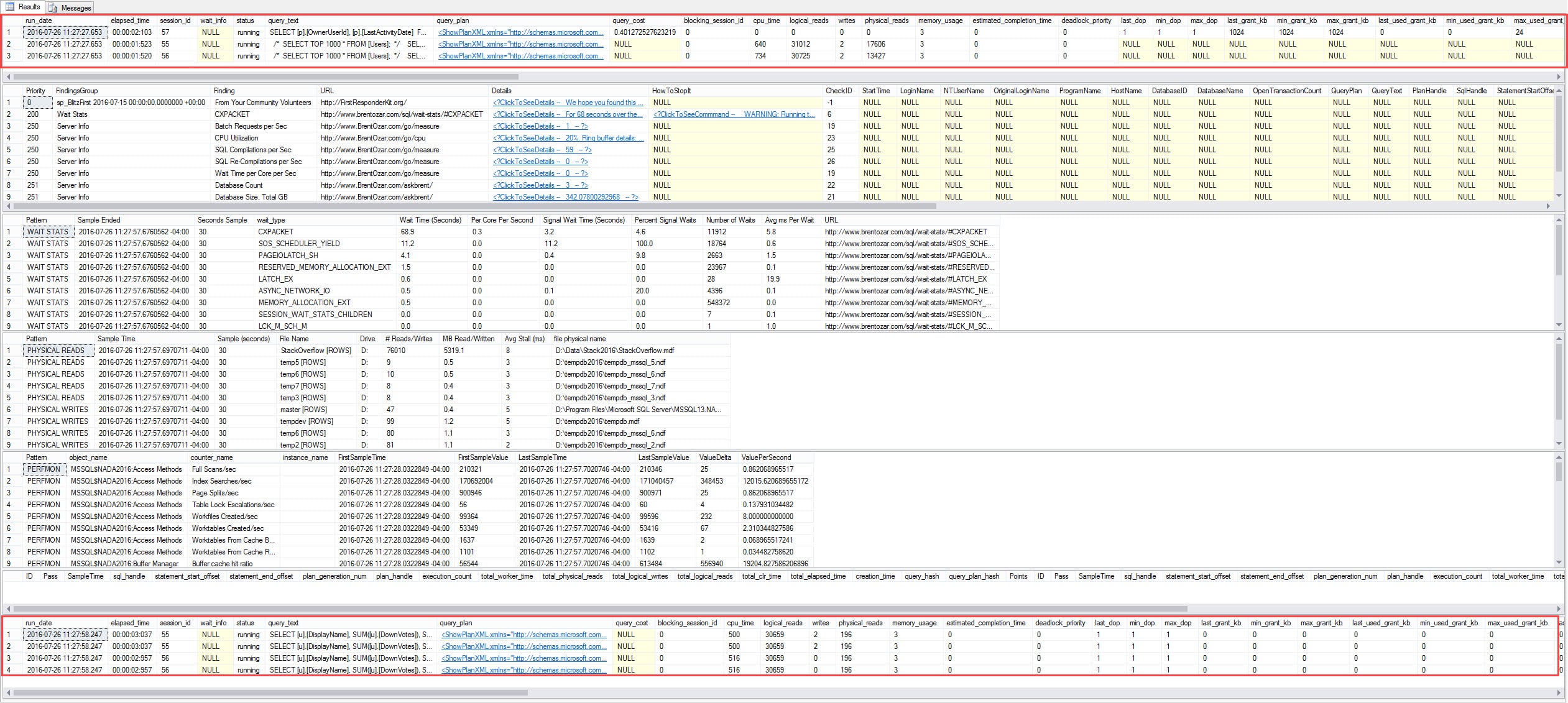
One day, after seeing enough horrific but well-meaning indexes created in production by the Database Engine Tuning Advisor, we got to brainstorming. Could we set something up that would stop the DETA on a production box, but let it keep running in a development environment? Meaning, not break the contents of a database, but somehow disable DETA at the server level?
Sí, se puede – and the first step is to understand that the DETA creates these tables in msdb when it first fires up:
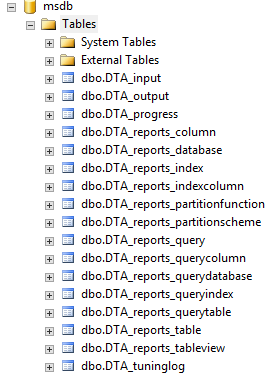
So all we have to do is set up a database trigger inside msdb on the production server. Trigger adopted from an idea from Richie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE msdb; GO CREATE TRIGGER NO_DTA_BAD_DTA ON DATABASE FOR CREATE_TABLE AS DECLARE @indexname NVARCHAR(4000); SELECT @indexname = EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)[1]', 'nvarchar(4000)') IF (CHARINDEX('DTA_', @indexname) > 0) BEGIN PRINT 'DTA Tables are not permitted to exist.'; ROLLBACK; END GO |
This database trigger in MSDB stops the prevention of any tables with DTA in the name. Now, whenever you try to point the DETA at the production server:
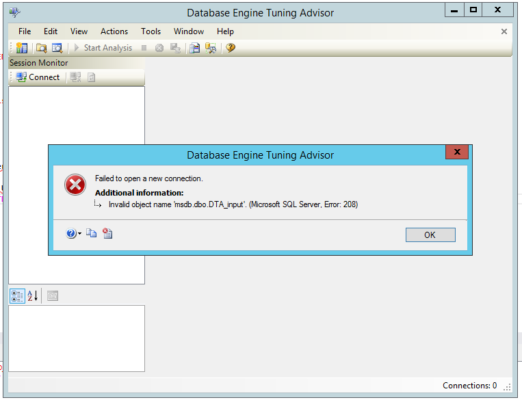
In the immortal words of a timeless philosopher, no no, no no no.
(People who liked this post also liked how I proposed to stop changes to tables.)