SQL Interview Question: “How do you respond?”
40 Comments
Brent’s in class this week!
So you get me instead. You can just pretend I’m Brent, or that you’re Brent, or that we’re both Brent, or even that we’re all just infinite recursive Brents within Brents. I don’t care.
Here’s the setup
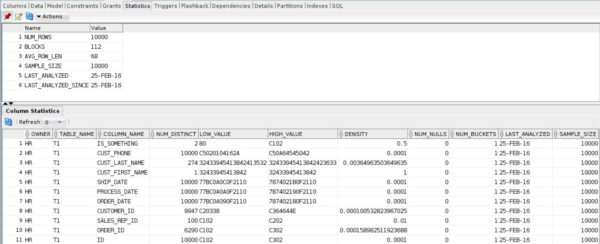
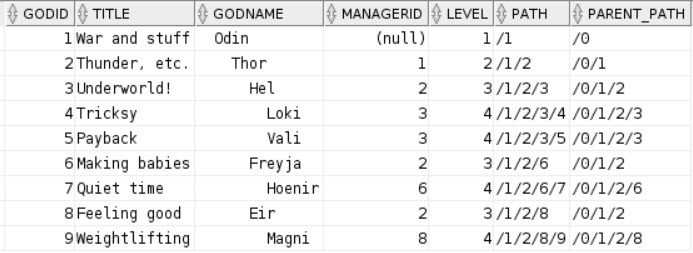
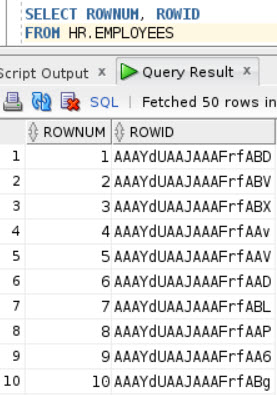
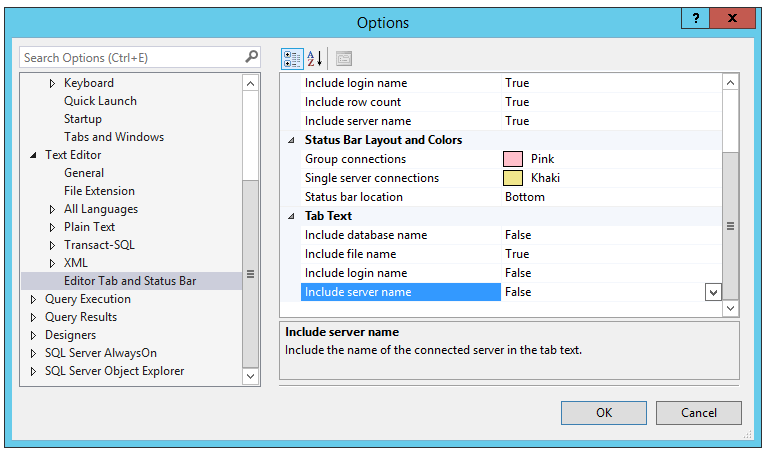
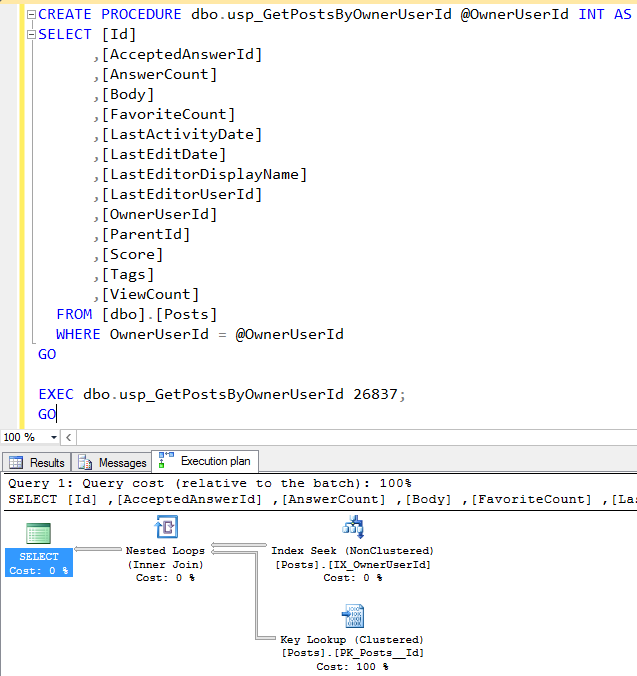
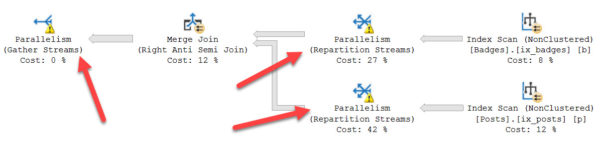
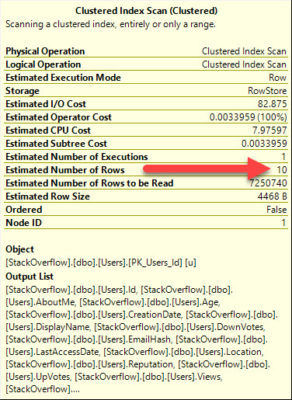
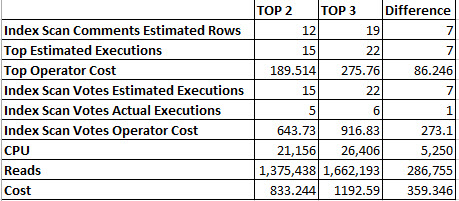
A new developer has been troubleshooting a sometimes-slow stored procedure, and wants you to review their progress so far. Tell me what could go wrong here.
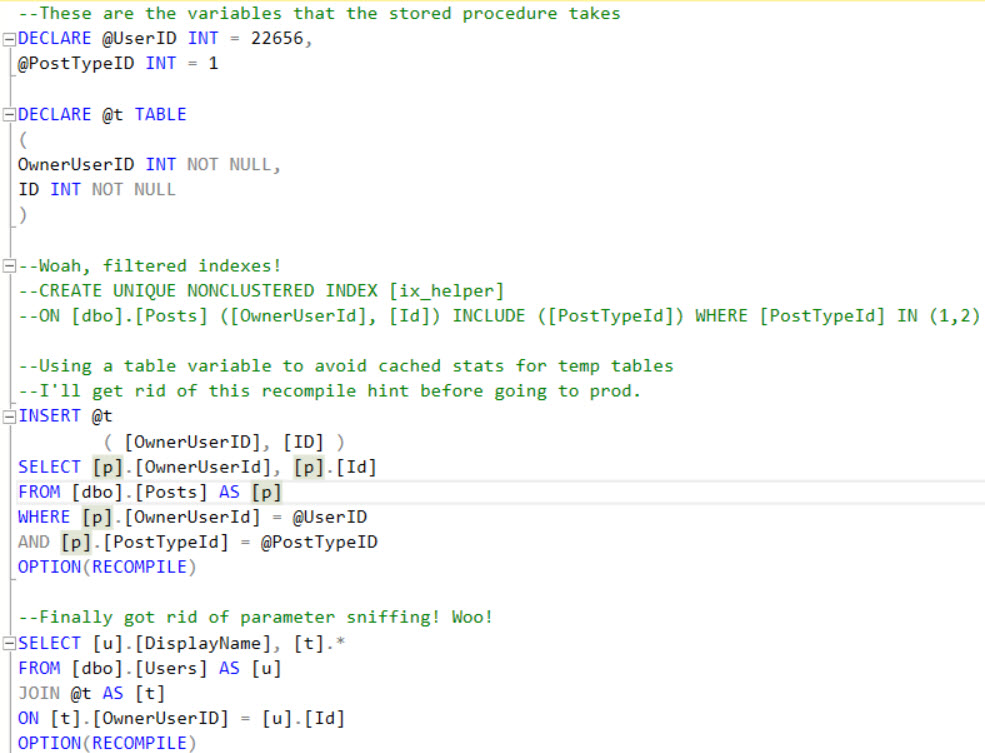
Remember, there are no right answers! Wait…