SQL Interview Question: “How do you respond?”
Brent’s in class this week!
So you get me instead. You can just pretend I’m Brent, or that you’re Brent, or that we’re both Brent, or even that we’re all just infinite recursive Brents within Brents. I don’t care.
Here’s the setup
A new developer has been troubleshooting a sometimes-slow stored procedure, and wants you to review their progress so far. Tell me what could go wrong here.
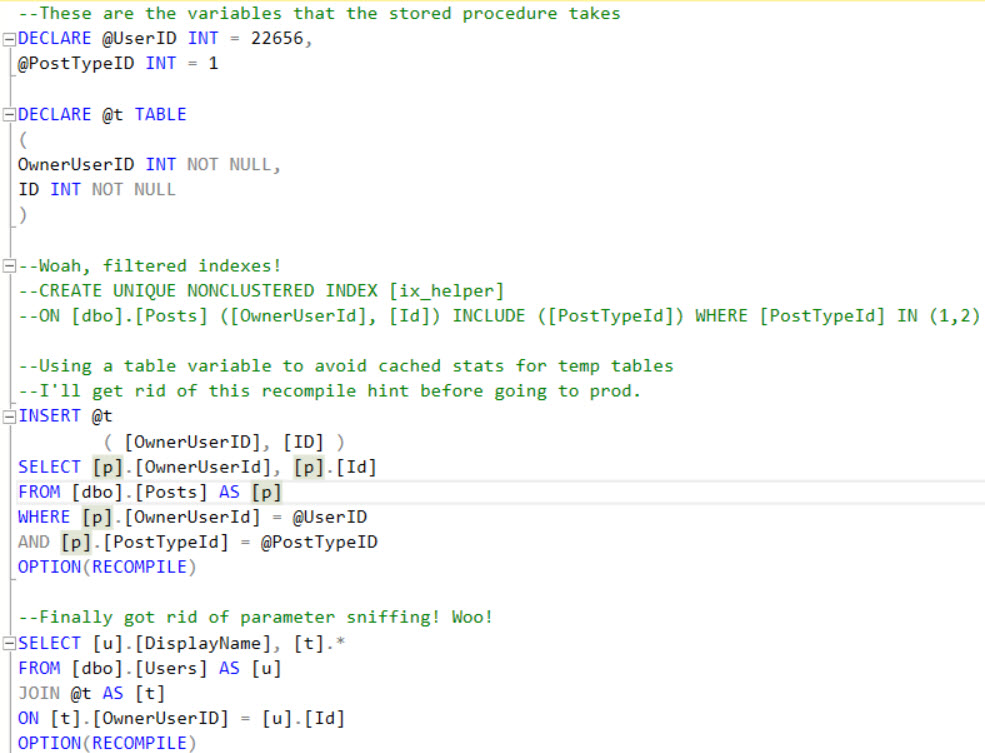
Remember, there are no right answers! Wait…
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
– parameter sniffing on the first query if option(recompile) is removed in production
– tempdb growth
– i’d do just one column with local variable for avoiding parameter sniffing
mistyped on the third line you have to read “i’d do just one query (with a join) with local variable for avoiding parameter sniffing”
CTE….
Unfrozen Caveman DBA does not get the job.
but if it works it ain’t stupid….
Yes, CTEs “work”, but how do they help here?
avoiding the param table I guess..
Ok – will keep on job hunting. My bad. 🙂
How would a CTE eliminate input parameters for a stored procedure? (I’m really confused.)
Nevermind – CTE is completely wrong and irrelevant here.
Lesson 1: Actually read the whole question.
Caveman – ayup, especially when it’s an interview question. But hey, better to learn that lesson here than in a real interview!
Get rid of the recompiles and look at the estimated and actual rows in the plan to see if there actually is parameter sniffing. If so see if using a local variable instead of post_owner helps instead.
Use a cte instead of the table variable as table variables can be problematic. Also a better plan could result.
Are filtered indexes justified here. Is post type never eg 3 ?
The second recompile is especially unnecessary…it will probably have to recompile this anyway due to the table var
TABLE VARIABLES…. BAD….
to avoid cached stats, would be better to use a #temptable, update the stats on it, then recompile,
as the @temp table would only have stats for 1 row rendering the recompile kind of pointless
First question – what testing was done that led the dev to use a table variable, the setup seems unnecessarily complicated. (I’d just like to see the path of ideas and numbers/results)
Second Question – if the SProc only returns Username, OwnerId/UserId, PostId, why not use a single query selecting FROM Post and joining to User?
I like the in-line comments, it feels like there’s a lot of flavor in this stored procedure!
I’d talk to the developer about the Filtered Index. I didn’t notice anything in the query text about only using Post Ids 1 and 2, so I want to know what he/she is using for testing, since that could work just for post types 1 and 2.
It looks to me like the objective of this query is to get all Posts from a specific user, so I’d like to see if the results are correctly showing up, after the optimization changes have been made.
The developer noted that he/she would like to get rid of OPTION RECOMPILE in Prod. I would enforce using the same code in all 3 environments, for consistency and change management.
One last thing, if that Filtered Index is created, I believe it can only be used by the stored procedure when the OPTION RECOMPILE hint is being used. I think I heard this from a presenter at PASS, so I’d like to test to make sure. If that’s true, we need to keep the RECOMPILE statement to ‘correctly’ use the new index.
One thing I just noticed in review of the question, the filtered index is a UNIQUE index, so it could actually cause INSERTs and UPDATEs to start failing since it will enforce uniqueness (on those two types) once implemented. I can’t think of a scenario where that would occur, but it could happen. I’m sure there’s more here that I’m missing.
What could go wrong here? The possibilities are endless. Meteorite strike? Or even more scarily it could be like that terrifically realistic and absorbing film, “2012”, where ‘the neutrinos’ mysteriously start making the entire North American continent tip into the pacific ocean in a hideous apocalypse. Or a huge part of Gran Canaria could collapse into the Atlantic due to a landslip unleashing a massive, deadly mega-tsunami on the eastern seaboard of the USA, Canada and all of the Caribbean.
Dear god, Erik, I need a lie down. See what you’ve done to me!?
And Aerosmith could do the theme song.
One word. Sharknado.
When the OPTION(RECOMPILE) is removed the original slowness problem would likely return since the filtered index does not seem to be doing anything currently.
The person who wrote the query is probably not aware of the limitations around filtered indexing and variables in a WHERE clause.
One correction… Assuming the filtered index does exist already, the OPTION(RECOMPILE) is allowing the test query to use the filtered index. Once the query is moved to production and OPTION(RECOMPILE) is removed, the filtered index will not be used due to the issue with filtered indexing and variables.
1. I would first ask what this code is supposed to do. Looks like there is a table Posts with columns (Id, PostTypeId, OwnerUserId) and a table Users with columns (OwnerUserId, DisplayName). As far as I understand the code, it returns a list of Posts.Ids with corresponding OwnerUserIds and Users.DisplayName. If this is indeed the desired result, then there is no need to first dump the (OwnerUserId, PostId) in the temporary table/temporary variable, do it in one select joining Posts with Users over OwnerUserId.
2. Anti-parameter-sniffing measures are needed only if you have a skewed distribution over UserIds or PostTypeIds. First prove that’s the case and that extra recompilation are not a worse evil.
3. The filtered index: Also here verification is necessary that the index maintenance doesn’t cost more (in potentially more critical code paths) than it helps this code. Also index definition is suboptimal: filter predicates go into index columns (OwnerUserId, PostTypeId), what is selected by the query goes into included columns (Id). Such an index is probably not unique anymore (basing only on column names and my not artificial intelligence 😉 ).
4. The usage of filtered indexes for parametrized queries doesn’t always work as planned. Depending on what decision was made in step 2 (recompile or not) you can also use the dynamic SQL trick (google “Jeremiah Peschka filtered indexes”), create the index as not filtered or not create the index at all (see first sentence in step 3).
In addition, since one of the input parameters is UserID, the output will be constrained to a single user. So lookup DisplayName first and store into a local variable. This removes both the temp table variable and the 2nd JOIN.
As there is no schema provided in the question, we can’t actually tell whether there is only 1 DisplayName per UserId (think UserId/DisplayName/ValidFrom/ValidTo for instance). Even if so, your optimization doesn’t provide any performance benefits.
Let’s see…what could go wrong…
One problem that I can see is that we will only be storing the last execution stats in sys.dm_exec_query_stats, but the column plan_generation_num in sys.dm_exec_query_stats will continue to increment.
Another potential problem could be that we are using more cpu than necessary in this query because of the RECOMPILE statements.
If we are using filtered indexes then these questions come to mind:
How often is the data inserted or updated in this table?
How often are stats updated?
Is there a custom job that updates stats regularly or do we have traceflag 2371 enabled?
How big is the table?
My main worries would be tempdb spills, poor execution plans, and overall poor performance due to bad stats.
One gotcha of table variables is that SQL Server will not have statistics for table variables and the row count is always assumed to be 1. The recompile statements can give you an accurate estimation for the row count in the table variable, but if we take those out we will be getting bad query plans with this.
The new developer should check out this link for more information: https://blogs.msdn.microsoft.com/blogdoezequiel/2012/11/30/table-variables-and-row-estimations-part-1/
Also, Brent Ozar goes into this a little in his “Think like the SQL Engine” training video. In that video there were things I already knew, but there were these little details that he would mention that I didn’t know. For $29, it is worth purchasing. That’s like sacrificing one meal and a beer at a restaurant and personally, I would eat another night of ramen (with a wheat beer) to give this new developer a better chance at life.
In the end I would get away from using the table variable and the recompile statements by either removing the table variable entirely or by converting it into a tempdb and updating statistics on it.
I’m assuming the filtered index was already there then then? Does the comment show that the developer found it and thought it was a bad thing? Maybe they’ll recommend dropping that and creating a normal covering index, where Post type ID is not just included,and part of the key.
The developer may think they’ve fixed the issue bere, but it would probably be because the recompile gets them the best plan every time. Once it’s taken out again in prod (if they remember) this may not be the case.
I’d simplify it though. It can be done in one hit. No need for table variables. Get rid of select *.
Stale stats should be managed as part of normal DB maintenance. Parameter sniffing isn’t necessarily an issue.
Here are a few of my thoughts at a first glance.
First off switching your #table to a @table is going to change the second portion of the query. There aren’t any parameters being used in that portion of the query. Changing this is likely to give the second query a poor cardinality estimate and produce a sub par execution plan. In conclusion my first and largest concern with this query is that he’s changing things that in this procedure that are likely not broken.
Second the note don’t worry I’ll change this code before it goes to prod is something I see in a lot of production code and never fails to make me nervous.
Third I’m going to have to ask when this is going slow. It’s distinctly possible if not likely that the times that this process is going slow. Is when it’s outside of the range of this filtered index. That isn’t really parameter sniffing and is more than likely the cause of this slowdown.
Now considering that the third thing I noticed is where I believe the root cause of problem is you’d think I’d bump that up to number one. However if it’s a dev coming to me for help, I want to guide them more towards discovering the root cause and using good coding habits instead of just throwing things at the dart board.
Those are my initial thoughts. Can’t wait to look through the comments and see what other folks found that I missed.
1. It will not work with the filtered index once recompile option removed.
So, it needs to create 2 separated statements instead of recompile option.
2. The statement is simple enough to use one join instead of a table variable.
Table variable estimated row is always 1 or 1000 depends on compatibility level.
So, it could be a problem in case result set off a lot.
3. Sometimes-Slow was a tricky part. it might be related blocking or one of the big active user.
4. It may consider “nolock” option depends on business logic.
The statement seems pulling PostID based on UserID and PostTypeID. This case may ok with “nolock” option.
5. When the slowness was caused by a big active user, it could be better performance with a different plan. So, we can consider a seperated statement. It needs to verify first.
So, here is my final query.
CREATE PROC USP_ABC
@UserID INT
, @PostTypeId INT
AS
BEGIN
SET NOCOUNT ON;
SET TRAN ISOLATION LEVEL READ UNCOMMITTED — Depends on Business logic
IF @UserID IN (1,10,100) BEGIN
— Big active users : We can deal with a lot of difference way. It may not need either.
SELECT u.DisplayName, u.Id AS OwnerUserId, p.Id
FROM dbo.Users AS u
JOIN dbo.Posts AS p WITH(FORCESCAN) ON p.OwnerUserId = u.Id
WHERE u.id = @UserID
AND p.PostTypeId = @PostTypeID
END ELSE IF @PostTypeId IN (1,2) BEGIN
SELECT u.DisplayName, u.Id AS OwnerUserId, p.Id
FROM dbo.Users AS u
JOIN dbo.Posts AS p ON p.OwnerUserId = u.Id
WHERE u.id = @UserID
AND p.PostTypeId = @PostTypeID
AND p.PostTypeId IN (1,2)
END ELSE BEGIN
SELECT u.DisplayName, u.Id AS OwnerUserId, p.Id
FROM dbo.Users AS u
JOIN dbo.Posts AS p ON p.OwnerUserId = u.Id
WHERE u.id = @UserID
AND p.PostTypeId = @PostTypeID
END
END
– query the users table to get the display name for the @UserId into a local variable -> you can now query dbo.Posts without joining by adding @DisplayName to the SELECT part -> no parameter sniffing problem (NESTED LOOP vs MERGE / HASH JOIN)
– either split the query into two parts using an
IF @PostTypeID IN (1,2)
SELECT @DisplayName DisplayName, @UserId OwnerUserId, p.Id FROM dbo.Posts p
WHERE p.OwnerUserId = @UserID
AND p.PostTypeId = @PostTypeID
AND p.PostTypeId IN (1,2)
ELSE
SELECT @DisplayName DisplayName, @UserId OwnerUserId, p.Id FROM dbo.Posts p
WHERE p.OwnerUserId = @UserID
AND p.PostTypeId = @PostTypeID
– or just remove the filter from the index
– consider to add the @PostTypeId as second column to the index and move the ID column into the INCLUDE part (considering that the index will not be used by other queries)
– remove the RECOMPILES
Why would you give advice to the new developer based on this code. Just talk to this guy (or girl);
1) What was the original procedure?
2) What did you try so far? Give him compliments for the good directions he took; give feedback on the less efficient parts. (make a quick estimation if he is uncertain, etc to balance the feedback)
3) Point him to articles or give him small hints, like: Why did you (or your predecessor) create two queries instead of one? Does this commented in / out code really exists?
4) Don’t do his job; unless you have the certainty:
A) he is so frustrated that he doesn’t want to see this code
B) he misses skills so solve the problem,and it is not a fifteen minutes video
Uh… because this is your job, as a DBA.
Sorry, my point was:
Why would you rewrite the complete SQL – code, when he is just asking for advice?
1 – Parameter Siniffing
– If query hint recompile is removed in production.
– When OPTION (RECOMPILE) is added to an individual statement in the stored procedure, that particular plan will not be cached – but others in the procedure are not affected.
https://www.brentozar.com/archive/2013/06/the-elephant-and-the-mouse-or-parameter-sniffing-in-sql-server/
3 – The query optimizer won’t consider filtered indexes if you’re using local variables or parameterized SQL for the predicate that matches the filter. Jeremiah explains at the following: https://www.brentozar.com/archive/2013/11/what-you-can-and-cant-do-with-filtered-indexes/
Few observations:
1) Because of {variables which are initialized within declaration / filtered indexes} this means that it’s SQL2008 minimum.
2) Because of that filtered index, some settings should be ON or OFF according to MSDN thus:
SET ANSI_NULLS, ANSI_PADDING, ANSI_WARNINGS, ARITHABORT, CONCAT_NULL_YIELDS_NULL, QUOTED_IDENTIFIER ON
SET NUMERIC_ROUNDABORT OFF
See section [Required SET Options for Filtered Indexes]:
https://msdn.microsoft.com/en-us/library/ms189292.aspx
3) @t is not needed. It adds an overhead on tempdb and it’s “kind of” “stop and go” operator: in order to execute last SELECT, database engine should finish inserting data into @t table.
3.1) The source code of SELECT statement used to insert data into @t (without OPTION(RECOMPILE)) could be inserted into last SELECT statement
3.2) or it can be inserted into Common Table Expression and then last SELECT statement could be changed thus SELECT … FROM … /*@t*/ CTE AS …
3.3) or we could rewrite last two statements to be as one SELECT statement thus:
SELECT u.DisplayName, p.OwnerUserID, p.ID
FROM dbo.Users AS u
JOIN dbo.Posts AS p ON u.ID = p.OwnerUserID
WHERE p.OwnerUserID = @UserID
— AND p.PostTypeID IN (1, 2) — uncomment this list if current SP/query should be executed only for these two types
AND p.PostTypeID = @PostTypeID
— OPTION(RECOMPILE) — Uncomment if only current SP/query should be executed for all kind of posts (1, 2 but also 3, 4, etc.).
— Look at CHECK constraints defined on dbo.Post table regarding values allowed for PostTypeID column.
4) Table variables disable parallelism and this is another reason to avoid them.
5) OPTION(RECOMPILE) could generate wrong results (see Microsoft Connect) when the same query (with RECOMPILE hint) is executed concurrently. We should check current build to see if current SQL instance is affected by this bug.
I’m not answering jack without an actual query plan. It’s a fun guessing game but it’s just thT.
Step 1: ditch the brackets 😛
I found saying I’m not answering that rarely goes well in an interview. 😉
Seeing this code would make me ask the developer “What hurts? What problem are you trying to solve?”. I realize it’s s fun exercise to see if we know internals. In an interview the conversation would go one way, in practice, another.
I have a log shipping set up. The secondary is used for reporting. Whenever the user does a query of more than a few seconds log shipping is reported as late until the query finishes. Any idea how to prevent this. Logs are restored every 15 minutes
For consulting help, feel free to click Consulting at the top of the screen. Cheers!